 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquipping LLM with Directional Multi-Talker Speech Understanding Capabilities
Feb 06, 2026Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech understanding capabilities. However, most speech LLMs are trained on single-channel, single-talker data, which makes it challenging to directly apply them to multi-talker and multi-channel speech understanding task. In this work, we present a comprehensive investigation on how to enable directional multi-talker speech understanding capabilities for LLMs, specifically in smart glasses usecase. We propose two novel approaches to integrate directivity into LLMs: (1) a cascaded system that leverages a source separation front-end module, and (2) an end-to-end system that utilizes serialized output training. All of the approaches utilize a multi-microphone array embedded in smart glasses to optimize directivity interpretation and processing in a streaming manner. Experimental results demonstrate the efficacy of our proposed methods in endowing LLMs with directional speech understanding capabilities, achieving strong performance in both speech recognition and speech translation tasks.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Target word activity detector: An approach to obtain ASR word boundaries without lexicon
Sep 20, 2024Obtaining word timestamp information from end-to-end (E2E) ASR models remains challenging due to the lack of explicit time alignment during training. This issue is further complicated in multilingual models. Existing methods, either rely on lexicons or introduce additional tokens, leading to scalability issues and increased computational costs. In this work, we propose a new approach to estimate word boundaries without relying on lexicons. Our method leverages word embeddings from sub-word token units and a pretrained ASR model, requiring only word alignment information during training. Our proposed method can scale-up to any number of languages without incurring any additional cost. We validate our approach using a multilingual ASR model trained on five languages and demonstrate its effectiveness against a strong baseline.
CogniDual Framework: Self-Training Large Language Models within a Dual-System Theoretical Framework for Improving Cognitive Tasks
Sep 05, 2024

Cognitive psychology investigates perception, attention, memory, language, problem-solving, decision-making, and reasoning. Kahneman's dual-system theory elucidates the human decision-making process, distinguishing between the rapid, intuitive System 1 and the deliberative, rational System 2. Recent advancements have positioned large language Models (LLMs) as formidable tools nearing human-level proficiency in various cognitive tasks. Nonetheless, the presence of a dual-system framework analogous to human cognition in LLMs remains unexplored. This study introduces the \textbf{CogniDual Framework for LLMs} (CFLLMs), designed to assess whether LLMs can, through self-training, evolve from deliberate deduction to intuitive responses, thereby emulating the human process of acquiring and mastering new information. Our findings reveal the cognitive mechanisms behind LLMs' response generation, enhancing our understanding of their capabilities in cognitive psychology. Practically, self-trained models can provide faster responses to certain queries, reducing computational demands during inference.
Promoting Equality in Large Language Models: Identifying and Mitigating the Implicit Bias based on Bayesian Theory
Aug 20, 2024Large language models (LLMs) are trained on extensive text corpora, which inevitably include biased information. Although techniques such as Affective Alignment can mitigate some negative impacts of these biases, existing prompt-based attack methods can still extract these biases from the model's weights. Moreover, these biases frequently appear subtly when LLMs are prompted to perform identical tasks across different demographic groups, thereby camouflaging their presence. To address this issue, we have formally defined the implicit bias problem and developed an innovative framework for bias removal based on Bayesian theory, Bayesian-Theory based Bias Removal (BTBR). BTBR employs likelihood ratio screening to pinpoint data entries within publicly accessible biased datasets that represent biases inadvertently incorporated during the LLM training phase. It then automatically constructs relevant knowledge triples and expunges bias information from LLMs using model editing techniques. Through extensive experimentation, we have confirmed the presence of the implicit bias problem in LLMs and demonstrated the effectiveness of our BTBR approach.
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Mar 31, 2024The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at \url{aka.ms/wavllm}.
COSMIC: Data Efficient Instruction-tuning For Speech In-Context Learning
Nov 03, 2023



We present a data and cost efficient way of incorporating the speech modality into a large language model (LLM). The resulting multi-modal LLM is a COntextual Speech Model with Instruction-following/in-context-learning Capabilities - COSMIC. Speech comprehension test question-answer (SQA) pairs are generated using GPT-3.5 based on the speech transcriptions as a part of the supervision for the instruction tuning. With fewer than 20M trainable parameters and as little as 450 hours of English speech data for SQA generation, COSMIC exhibits emergent instruction-following and in-context learning capabilities in speech-to-text tasks. The model is able to follow the given text instructions to generate text response even on the unseen EN$\to$X speech-to-text translation (S2TT) task with zero-shot setting. We evaluate the model's in-context learning via various tasks such as EN$\to$X S2TT and few-shot domain adaptation. And instruction-following capabilities are evaluated through a contextual biasing benchmark. Our results demonstrate the efficacy of the proposed low cost recipe for building a speech LLM and that with the new instruction-tuning data.
Improving Stability in Simultaneous Speech Translation: A Revision-Controllable Decoding Approach
Oct 06, 2023



Simultaneous Speech-to-Text translation serves a critical role in real-time crosslingual communication. Despite the advancements in recent years, challenges remain in achieving stability in the translation process, a concern primarily manifested in the flickering of partial results. In this paper, we propose a novel revision-controllable method designed to address this issue. Our method introduces an allowed revision window within the beam search pruning process to screen out candidate translations likely to cause extensive revisions, leading to a substantial reduction in flickering and, crucially, providing the capability to completely eliminate flickering. The experiments demonstrate the proposed method can significantly improve the decoding stability without compromising substantially on the translation quality.
E-Branchformer: Branchformer with Enhanced merging for speech recognition
Sep 30, 2022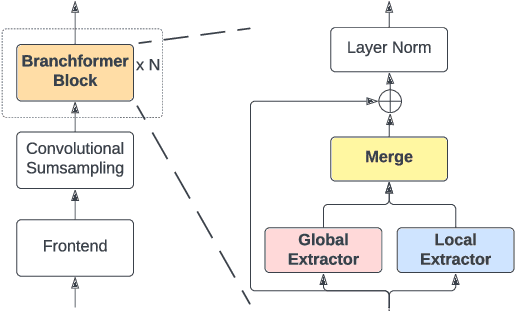
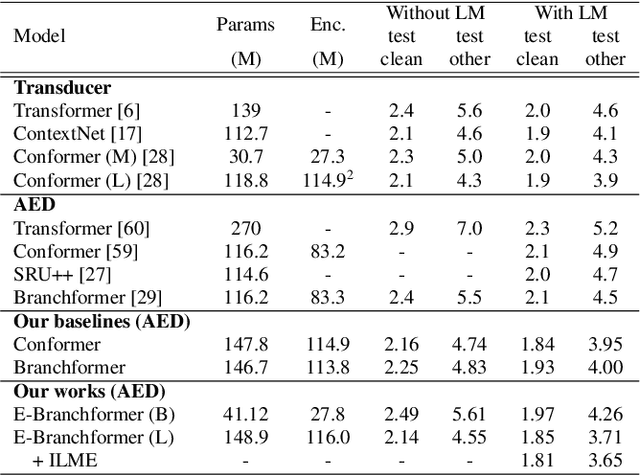
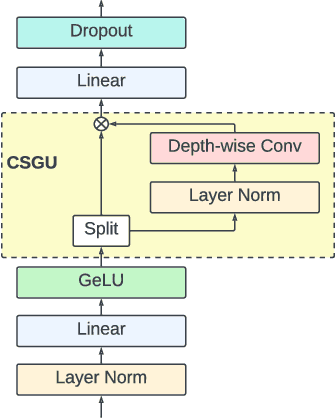
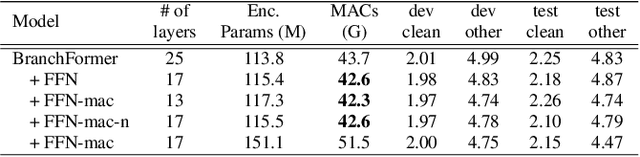
Conformer, combining convolution and self-attention sequentially to capture both local and global information, has shown remarkable performance and is currently regarded as the state-of-the-art for automatic speech recognition (ASR). Several other studies have explored integrating convolution and self-attention but they have not managed to match Conformer's performance. The recently introduced Branchformer achieves comparable performance to Conformer by using dedicated branches of convolution and self-attention and merging local and global context from each branch. In this paper, we propose E-Branchformer, which enhances Branchformer by applying an effective merging method and stacking additional point-wise modules. E-Branchformer sets new state-of-the-art word error rates (WERs) 1.81% and 3.65% on LibriSpeech test-clean and test-other sets without using any external training data.
SRU++: Pioneering Fast Recurrence with Attention for Speech Recognition
Oct 11, 2021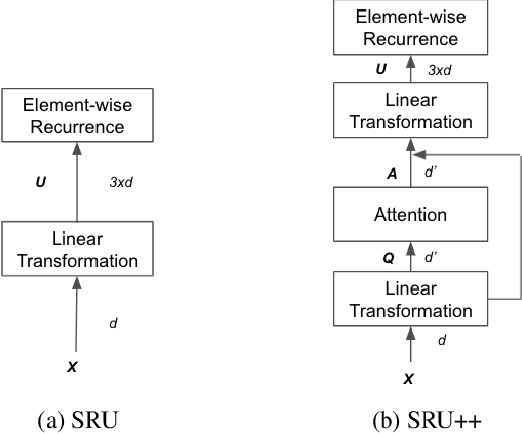



The Transformer architecture has been well adopted as a dominant architecture in most sequence transduction tasks including automatic speech recognition (ASR), since its attention mechanism excels in capturing long-range dependencies. While models built solely upon attention can be better parallelized than regular RNN, a novel network architecture, SRU++, was recently proposed. By combining the fast recurrence and attention mechanism, SRU++ exhibits strong capability in sequence modeling and achieves near-state-of-the-art results in various language modeling and machine translation tasks with improved compute efficiency. In this work, we present the advantages of applying SRU++ in ASR tasks by comparing with Conformer across multiple ASR benchmarks and study how the benefits can be generalized to long-form speech inputs. On the popular LibriSpeech benchmark, our SRU++ model achieves 2.0% / 4.7% WER on test-clean / test-other, showing competitive performances compared with the state-of-the-art Conformer encoder under the same set-up. Specifically, SRU++ can surpass Conformer on long-form speech input with a large margin, based on our analysis.