 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional visualization of X-ray micro-CT with large-scale datasets: Efficiency and accuracy for real-time interaction
Jan 21, 2026As Micro-CT technology continues to refine its characterization of material microstructures, industrial CT ultra-precision inspection is generating increasingly large datasets, necessitating solutions to the trade-off between accuracy and efficiency in the 3D characterization of defects during ultra-precise detection. This article provides a unique perspective on recent advances in accurate and efficient 3D visualization using Micro-CT, tracing its evolution from medical imaging to industrial non-destructive testing (NDT). Among the numerous CT reconstruction and volume rendering methods, this article selectively reviews and analyzes approaches that balance accuracy and efficiency, offering a comprehensive analysis to help researchers quickly grasp highly efficient and accurate 3D reconstruction methods for microscopic features. By comparing the principles of computed tomography with advancements in microstructural technology, this article examines the evolution of CT reconstruction algorithms from analytical methods to deep learning techniques, as well as improvements in volume rendering algorithms, acceleration, and data reduction. Additionally, it explores advanced lighting models for high-accuracy, photorealistic, and efficient volume rendering. Furthermore, this article envisions potential directions in CT reconstruction and volume rendering. It aims to guide future research in quickly selecting efficient and precise methods and developing new ideas and approaches for real-time online monitoring of internal material defects through virtual-physical interaction, for applying digital twin model to structural health monitoring (SHM).
Generating Sketches in a Hierarchical Auto-Regressive Process for Flexible Sketch Drawing Manipulation at Stroke-Level
Nov 11, 2025Generating sketches with specific patterns as expected, i.e., manipulating sketches in a controllable way, is a popular task. Recent studies control sketch features at stroke-level by editing values of stroke embeddings as conditions. However, in order to provide generator a global view about what a sketch is going to be drawn, all these edited conditions should be collected and fed into generator simultaneously before generation starts, i.e., no further manipulation is allowed during sketch generating process. In order to realize sketch drawing manipulation more flexibly, we propose a hierarchical auto-regressive sketch generating process. Instead of generating an entire sketch at once, each stroke in a sketch is generated in a three-staged hierarchy: 1) predicting a stroke embedding to represent which stroke is going to be drawn, and 2) anchoring the predicted stroke on the canvas, and 3) translating the embedding to a sequence of drawing actions to form the full sketch. Moreover, the stroke prediction, anchoring and translation are proceeded auto-regressively, i.e., both the recently generated strokes and their positions are considered to predict the current one, guiding model to produce an appropriate stroke at a suitable position to benefit the full sketch generation. It is flexible to manipulate stroke-level sketch drawing at any time during generation by adjusting the exposed editable stroke embeddings.
Decoupled Geometric Parameterization and its Application in Deep Homography Estimation
May 22, 2025



Planar homography, with eight degrees of freedom (DOFs), is fundamental in numerous computer vision tasks. While the positional offsets of four corners are widely adopted (especially in neural network predictions), this parameterization lacks geometric interpretability and typically requires solving a linear system to compute the homography matrix. This paper presents a novel geometric parameterization of homographies, leveraging the similarity-kernel-similarity (SKS) decomposition for projective transformations. Two independent sets of four geometric parameters are decoupled: one for a similarity transformation and the other for the kernel transformation. Additionally, the geometric interpretation linearly relating the four kernel transformation parameters to angular offsets is derived. Our proposed parameterization allows for direct homography estimation through matrix multiplication, eliminating the need for solving a linear system, and achieves performance comparable to the four-corner positional offsets in deep homography estimation.
TexLiverNet: Leveraging Medical Knowledge and Spatial-Frequency Perception for Enhanced Liver Tumor Segmentation
Nov 07, 2024



Integrating textual data with imaging in liver tumor segmentation is essential for enhancing diagnostic accuracy. However, current multi-modal medical datasets offer only general text annotations, lacking lesion-specific details critical for extracting nuanced features, especially for fine-grained segmentation of tumor boundaries and small lesions. To address these limitations, we developed datasets with lesion-specific text annotations for liver tumors and introduced the TexLiverNet model. TexLiverNet employs an agent-based cross-attention module that integrates text features efficiently with visual features, significantly reducing computational costs. Additionally, enhanced spatial and adaptive frequency domain perception is proposed to precisely delineate lesion boundaries, reduce background interference, and recover fine details in small lesions. Comprehensive evaluations on public and private datasets demonstrate that TexLiverNet achieves superior performance compared to current state-of-the-art methods.
Distribution-aware Noisy-label Crack Segmentation
Oct 12, 2024



Road crack segmentation is critical for robotic systems tasked with the inspection, maintenance, and monitoring of road infrastructures. Existing deep learning-based methods for crack segmentation are typically trained on specific datasets, which can lead to significant performance degradation when applied to unseen real-world scenarios. To address this, we introduce the SAM-Adapter, which incorporates the general knowledge of the Segment Anything Model (SAM) into crack segmentation, demonstrating enhanced performance and generalization capabilities. However, the effectiveness of the SAM-Adapter is constrained by noisy labels within small-scale training sets, including omissions and mislabeling of cracks. In this paper, we present an innovative joint learning framework that utilizes distribution-aware domain-specific semantic knowledge to guide the discriminative learning process of the SAM-Adapter. To our knowledge, this is the first approach that effectively minimizes the adverse effects of noisy labels on the supervised learning of the SAM-Adapter. Our experimental results on two public pavement crack segmentation datasets confirm that our method significantly outperforms existing state-of-the-art techniques. Furthermore, evaluations on the completely unseen CFD dataset demonstrate the high cross-domain generalization capability of our model, underscoring its potential for practical applications in crack segmentation.
Promoting Equality in Large Language Models: Identifying and Mitigating the Implicit Bias based on Bayesian Theory
Aug 20, 2024Large language models (LLMs) are trained on extensive text corpora, which inevitably include biased information. Although techniques such as Affective Alignment can mitigate some negative impacts of these biases, existing prompt-based attack methods can still extract these biases from the model's weights. Moreover, these biases frequently appear subtly when LLMs are prompted to perform identical tasks across different demographic groups, thereby camouflaging their presence. To address this issue, we have formally defined the implicit bias problem and developed an innovative framework for bias removal based on Bayesian theory, Bayesian-Theory based Bias Removal (BTBR). BTBR employs likelihood ratio screening to pinpoint data entries within publicly accessible biased datasets that represent biases inadvertently incorporated during the LLM training phase. It then automatically constructs relevant knowledge triples and expunges bias information from LLMs using model editing techniques. Through extensive experimentation, we have confirmed the presence of the implicit bias problem in LLMs and demonstrated the effectiveness of our BTBR approach.
Fast-Fading Channel and Power Optimization of the Magnetic Inductive Cellular Network
Jun 07, 2024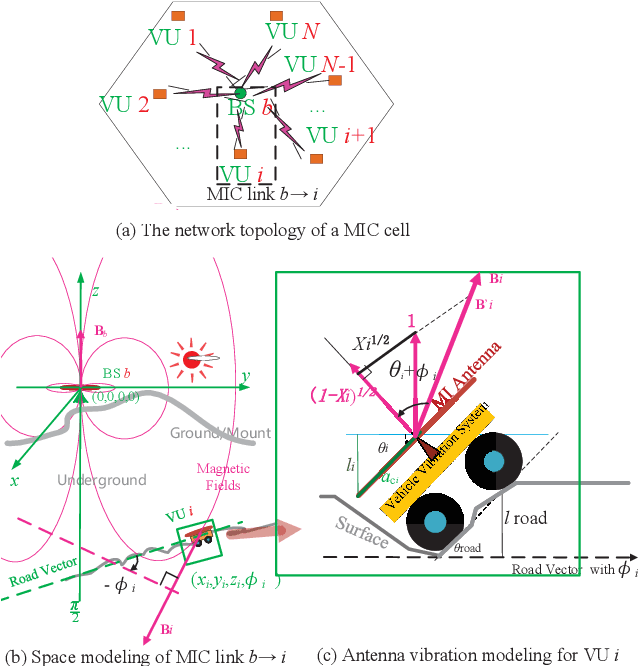
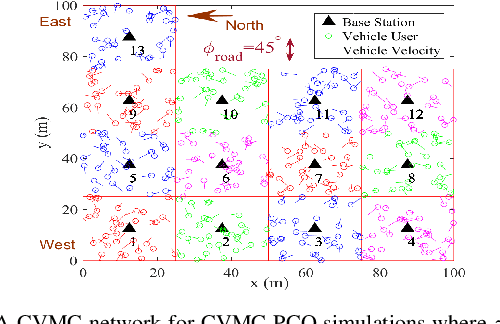
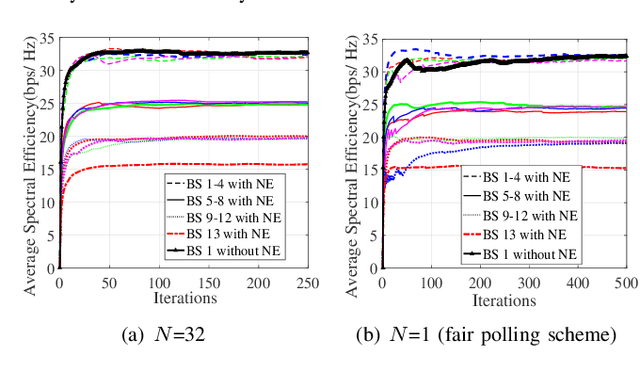
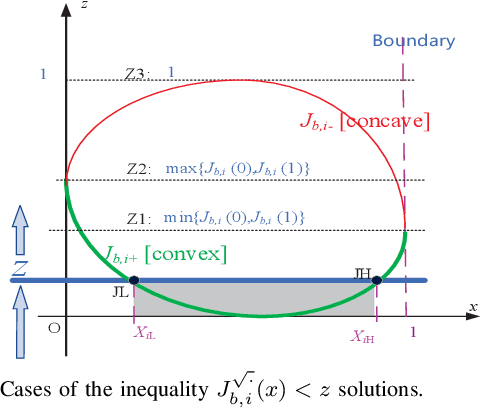
The cellular network of magnetic Induction (MI) communication holds promise in long-distance underground environments. In the traditional MI communication, there is no fast-fading channel since the MI channel is treated as a quasi-static channel. However, for the vehicle (mobile) MI (VMI) communication, the unpredictable antenna vibration brings the remarkable fast-fading. As such fast-fading cannot be modeled by the central limit theorem, it differs radically from other wireless fast-fading channels. Unfortunately, few studies focus on this phenomenon. In this paper, using a novel space modeling based on the electromagnetic field theorem, we propose a 3-dimension model of the VMI antenna vibration. By proposing ``conjugate pseudo-piecewise functions'' and boundary $p(x)$ distribution, we derive the cumulative distribution function (CDF), probability density function (PDF) and the expectation of the VMI fast-fading channel. We also theoretically analyze the effects of the VMI fast-fading on the network throughput, including the VMI outage probability which can be ignored in the traditional MI channel study. We draw several intriguing conclusions different from those in wireless fast-fading studies. For instance, the fast-fading brings more uniformly distributed channel coefficients. Finally, we propose the power control algorithm using the non-cooperative game and multiagent Q-learning methods to optimize the throughput of the cellular VMI network. Simulations validate the derivation and the proposed algorithm.
Equipping Sketch Patches with Context-Aware Positional Encoding for Graphic Sketch Representation
Mar 26, 2024The drawing order of a sketch records how it is created stroke-by-stroke by a human being. For graphic sketch representation learning, recent studies have injected sketch drawing orders into graph edge construction by linking each patch to another in accordance to a temporal-based nearest neighboring strategy. However, such constructed graph edges may be unreliable, since a sketch could have variants of drawings. In this paper, we propose a variant-drawing-protected method by equipping sketch patches with context-aware positional encoding (PE) to make better use of drawing orders for learning graphic sketch representation. Instead of injecting sketch drawings into graph edges, we embed these sequential information into graph nodes only. More specifically, each patch embedding is equipped with a sinusoidal absolute PE to highlight the sequential position in the drawing order. And its neighboring patches, ranked by the values of self-attention scores between patch embeddings, are equipped with learnable relative PEs to restore the contextual positions within a neighborhood. During message aggregation via graph convolutional networks, a node receives both semantic contents from patch embeddings and contextual patterns from PEs by its neighbors, arriving at drawing-order-enhanced sketch representations. Experimental results indicate that our method significantly improves sketch healing and controllable sketch synthesis.
Generalized Correspondence Matching via Flexible Hierarchical Refinement and Patch Descriptor Distillation
Mar 08, 2024



Correspondence matching plays a crucial role in numerous robotics applications. In comparison to conventional hand-crafted methods and recent data-driven approaches, there is significant interest in plug-and-play algorithms that make full use of pre-trained backbone networks for multi-scale feature extraction and leverage hierarchical refinement strategies to generate matched correspondences. The primary focus of this paper is to address the limitations of deep feature matching (DFM), a state-of-the-art (SoTA) plug-and-play correspondence matching approach. First, we eliminate the pre-defined threshold employed in the hierarchical refinement process of DFM by leveraging a more flexible nearest neighbor search strategy, thereby preventing the exclusion of repetitive yet valid matches during the early stages. Our second technical contribution is the integration of a patch descriptor, which extends the applicability of DFM to accommodate a wide range of backbone networks pre-trained across diverse computer vision tasks, including image classification, semantic segmentation, and stereo matching. Taking into account the practical applicability of our method in real-world robotics applications, we also propose a novel patch descriptor distillation strategy to further reduce the computational complexity of correspondence matching. Extensive experiments conducted on three public datasets demonstrate the superior performance of our proposed method. Specifically, it achieves an overall performance in terms of mean matching accuracy of 0.68, 0.92, and 0.95 with respect to the tolerances of 1, 3, and 5 pixels, respectively, on the HPatches dataset, outperforming all other SoTA algorithms. Our source code, demo video, and supplement are publicly available at mias.group/GCM.