 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompSRT: Quantization and Pruning for Image Super Resolution Transformers
Jan 28, 2026Model compression has become an important tool for making image super resolution models more efficient. However, the gap between the best compressed models and the full precision model still remains large and a need for deeper understanding of compression theory on more performant models remains. Prior research on quantization of LLMs has shown that Hadamard transformations lead to weights and activations with reduced outliers, which leads to improved performance. We argue that while the Hadamard transform does reduce the effect of outliers, an empirical analysis on how the transform functions remains needed. By studying the distributions of weights and activations of SwinIR-light, we show with statistical analysis that lower errors is caused by the Hadamard transforms ability to reduce the ranges, and increase the proportion of values around $0$. Based on these findings, we introduce CompSRT, a more performant way to compress the image super resolution transformer network SwinIR-light. We perform Hadamard-based quantization, and we also perform scalar decomposition to introduce two additional trainable parameters. Our quantization performance statistically significantly surpasses the SOTA in metrics with gains as large as 1.53 dB, and visibly improves visual quality by reducing blurriness at all bitwidths. At $3$-$4$ bits, to show our method is compatible with pruning for increased compression, we also prune $40\%$ of weights and show that we can achieve $6.67$-$15\%$ reduction in bits per parameter with comparable performance to SOTA.
TexLiverNet: Leveraging Medical Knowledge and Spatial-Frequency Perception for Enhanced Liver Tumor Segmentation
Nov 07, 2024



Integrating textual data with imaging in liver tumor segmentation is essential for enhancing diagnostic accuracy. However, current multi-modal medical datasets offer only general text annotations, lacking lesion-specific details critical for extracting nuanced features, especially for fine-grained segmentation of tumor boundaries and small lesions. To address these limitations, we developed datasets with lesion-specific text annotations for liver tumors and introduced the TexLiverNet model. TexLiverNet employs an agent-based cross-attention module that integrates text features efficiently with visual features, significantly reducing computational costs. Additionally, enhanced spatial and adaptive frequency domain perception is proposed to precisely delineate lesion boundaries, reduce background interference, and recover fine details in small lesions. Comprehensive evaluations on public and private datasets demonstrate that TexLiverNet achieves superior performance compared to current state-of-the-art methods.
IPT-V2: Efficient Image Processing Transformer using Hierarchical Attentions
Mar 31, 2024
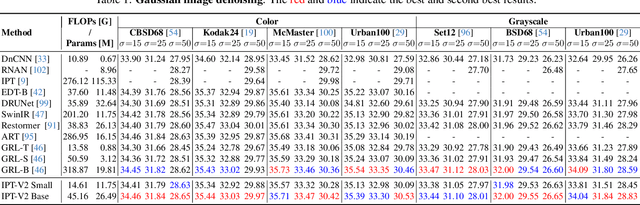
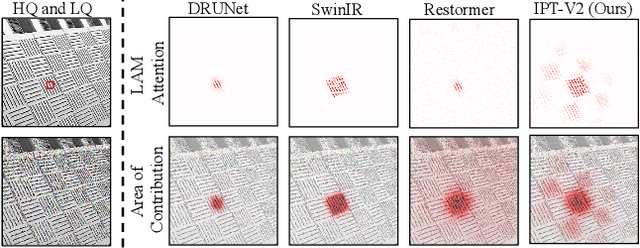

Recent advances have demonstrated the powerful capability of transformer architecture in image restoration. However, our analysis indicates that existing transformerbased methods can not establish both exact global and local dependencies simultaneously, which are much critical to restore the details and missing content of degraded images. To this end, we present an efficient image processing transformer architecture with hierarchical attentions, called IPTV2, adopting a focal context self-attention (FCSA) and a global grid self-attention (GGSA) to obtain adequate token interactions in local and global receptive fields. Specifically, FCSA applies the shifted window mechanism into the channel self-attention, helps capture the local context and mutual interaction across channels. And GGSA constructs long-range dependencies in the cross-window grid, aggregates global information in spatial dimension. Moreover, we introduce structural re-parameterization technique to feed-forward network to further improve the model capability. Extensive experiments demonstrate that our proposed IPT-V2 achieves state-of-the-art results on various image processing tasks, covering denoising, deblurring, deraining and obtains much better trade-off for performance and computational complexity than previous methods. Besides, we extend our method to image generation as latent diffusion backbone, and significantly outperforms DiTs.
HyperEditor: Achieving Both Authenticity and Cross-Domain Capability in Image Editing via Hypernetworks
Dec 21, 2023Editing real images authentically while also achieving cross-domain editing remains a challenge. Recent studies have focused on converting real images into latent codes and accomplishing image editing by manipulating these codes. However, merely manipulating the latent codes would constrain the edited images to the generator's image domain, hindering the attainment of diverse editing goals. In response, we propose an innovative image editing method called HyperEditor, which utilizes weight factors generated by hypernetworks to reassign the weights of the pre-trained StyleGAN2's generator. Guided by CLIP's cross-modal image-text semantic alignment, this innovative approach enables us to simultaneously accomplish authentic attribute editing and cross-domain style transfer, a capability not realized in previous methods. Additionally, we ascertain that modifying only the weights of specific layers in the generator can yield an equivalent editing result. Therefore, we introduce an adaptive layer selector, enabling our hypernetworks to autonomously identify the layers requiring output weight factors, which can further improve our hypernetworks' efficiency. Extensive experiments on abundant challenging datasets demonstrate the effectiveness of our method.
IFT: Image Fusion Transformer for Ghost-free High Dynamic Range Imaging
Sep 26, 2023
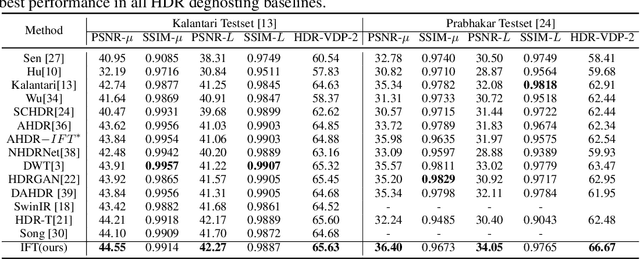

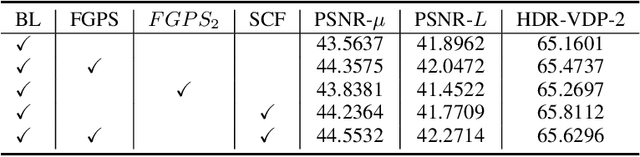
Multi-frame high dynamic range (HDR) imaging aims to reconstruct ghost-free images with photo-realistic details from content-complementary but spatially misaligned low dynamic range (LDR) images. Existing HDR algorithms are prone to producing ghosting artifacts as their methods fail to capture long-range dependencies between LDR frames with large motion in dynamic scenes. To address this issue, we propose a novel image fusion transformer, referred to as IFT, which presents a fast global patch searching (FGPS) module followed by a self-cross fusion module (SCF) for ghost-free HDR imaging. The FGPS searches the patches from supporting frames that have the closest dependency to each patch of the reference frame for long-range dependency modeling, while the SCF conducts intra-frame and inter-frame feature fusion on the patches obtained by the FGPS with linear complexity to input resolution. By matching similar patches between frames, objects with large motion ranges in dynamic scenes can be aligned, which can effectively alleviate the generation of artifacts. In addition, the proposed FGPS and SCF can be integrated into various deep HDR methods as efficient plug-in modules. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance both quantitatively and qualitatively.
Data Upcycling Knowledge Distillation for Image Super-Resolution
Sep 25, 2023Knowledge distillation (KD) emerges as a challenging yet promising technique for compressing deep learning models, characterized by the transmission of extensive learning representations from proficient and computationally intensive teacher models to compact student models. However, only a handful of studies have endeavored to compress the models for single image super-resolution (SISR) through KD, with their effects on student model enhancement remaining marginal. In this paper, we put forth an approach from the perspective of efficient data utilization, namely, the Data Upcycling Knowledge Distillation (DUKD) which facilitates the student model by the prior knowledge teacher provided via upcycled in-domain data derived from their inputs. This upcycling process is realized through two efficient image zooming operations and invertible data augmentations which introduce the label consistency regularization to the field of KD for SISR and substantially boosts student model's generalization. The DUKD, due to its versatility, can be applied across a broad spectrum of teacher-student architectures. Comprehensive experiments across diverse benchmarks demonstrate that our proposed DUKD method significantly outperforms previous art, exemplified by an increase of up to 0.5dB in PSNR over baselines methods, and a 67% parameters reduced RCAN model's performance remaining on par with that of the RCAN teacher model.
Deep Asymmetric Hashing with Dual Semantic Regression and Class Structure Quantization
Oct 24, 2021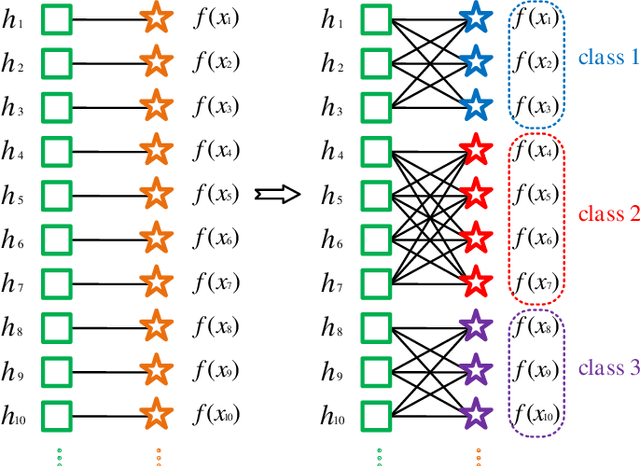
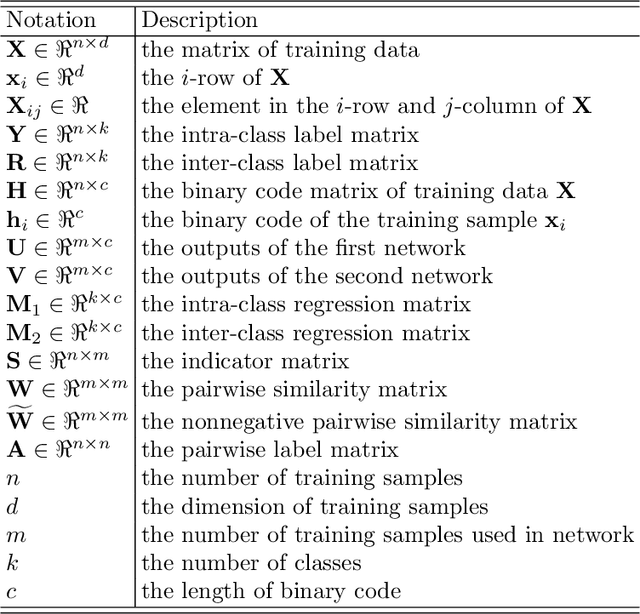
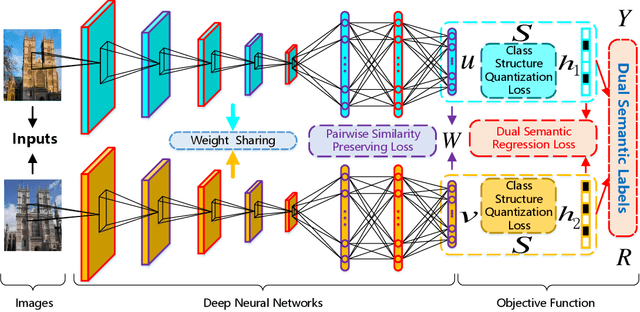
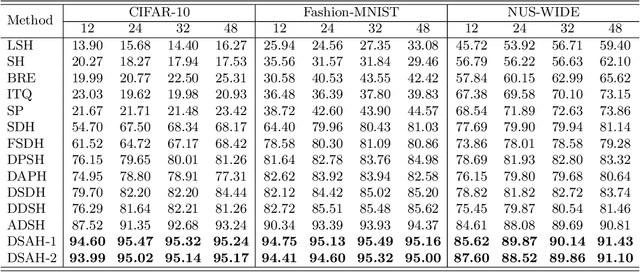
Recently, deep hashing methods have been widely used in image retrieval task. Most existing deep hashing approaches adopt one-to-one quantization to reduce information loss. However, such class-unrelated quantization cannot give discriminative feedback for network training. In addition, these methods only utilize single label to integrate supervision information of data for hashing function learning, which may result in inferior network generalization performance and relatively low-quality hash codes since the inter-class information of data is totally ignored. In this paper, we propose a dual semantic asymmetric hashing (DSAH) method, which generates discriminative hash codes under three-fold constrains. Firstly, DSAH utilizes class prior to conduct class structure quantization so as to transmit class information during the quantization process. Secondly, a simple yet effective label mechanism is designed to characterize both the intra-class compactness and inter-class separability of data, thereby achieving semantic-sensitive binary code learning. Finally, a meaningful pairwise similarity preserving loss is devised to minimize the distances between class-related network outputs based on an affinity graph. With these three main components, high-quality hash codes can be generated through network. Extensive experiments conducted on various datasets demonstrate the superiority of DSAH in comparison with state-of-the-art deep hashing methods.
Supervised feature selection with orthogonal regression and feature weighting
Oct 09, 2019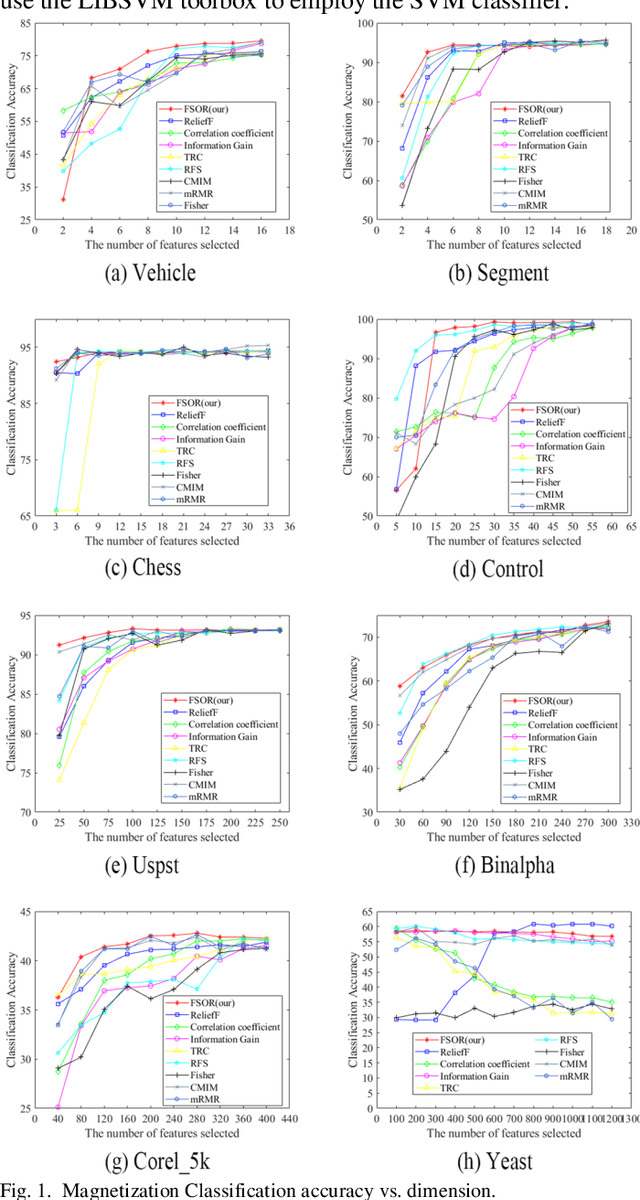
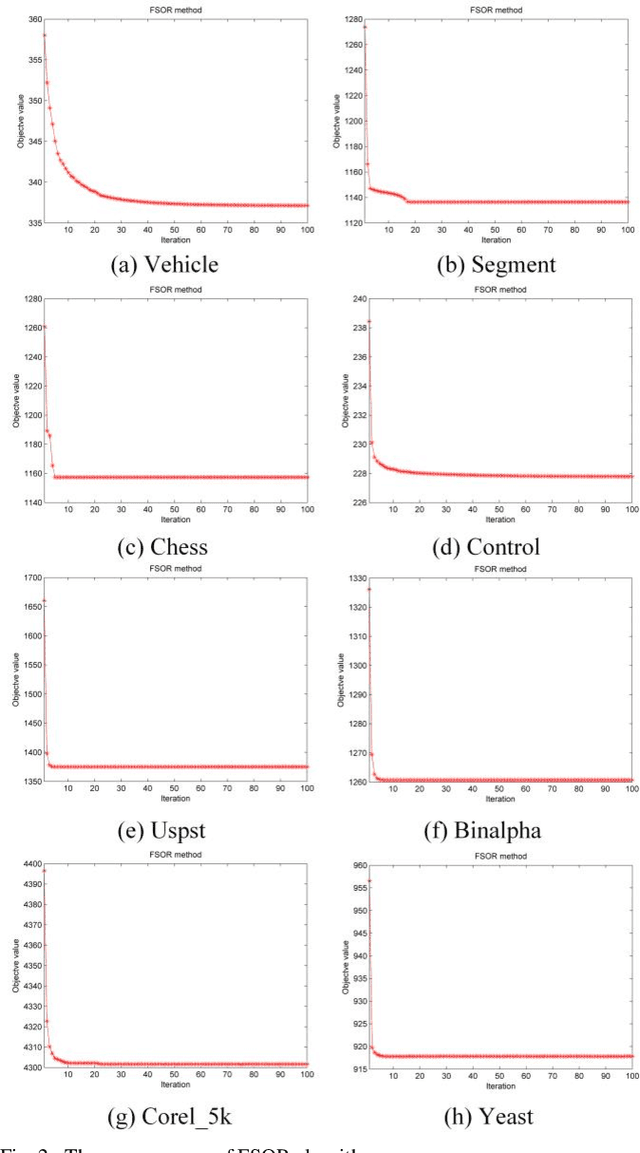
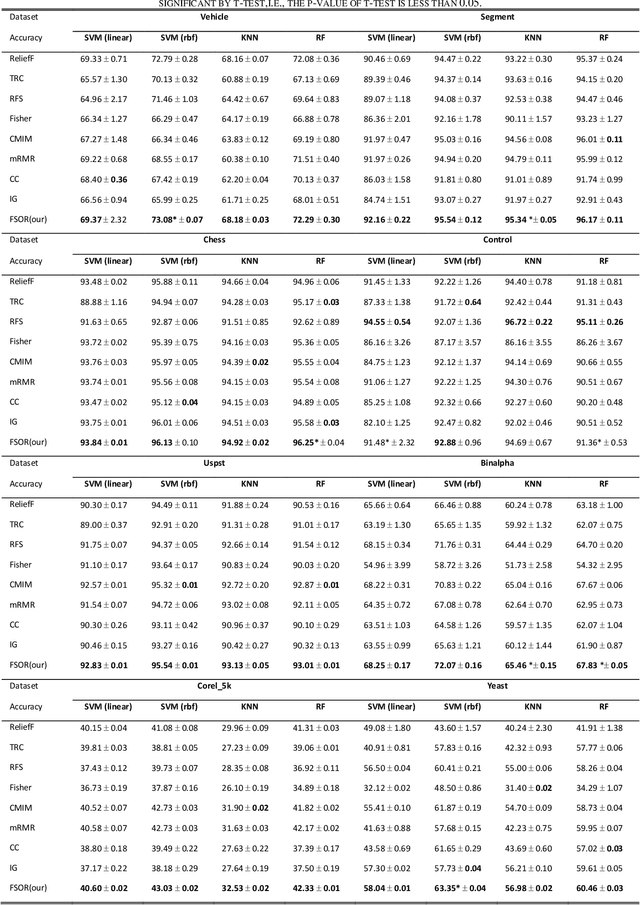
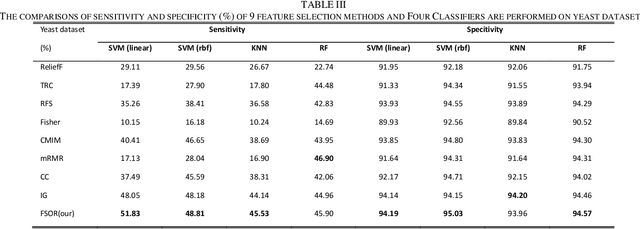
Effective features can improve the performance of a model, which can thus help us understand the characteristics and underlying structure of complex data. Previous feature selection methods usually cannot keep more local structure information. To address the defects previously mentioned, we propose a novel supervised orthogonal least square regression model with feature weighting for feature selection. The optimization problem of the objection function can be solved by employing generalized power iteration (GPI) and augmented Lagrangian multiplier (ALM) methods. Experimental results show that the proposed method can more effectively reduce the feature dimensionality and obtain better classification results than traditional feature selection methods. The convergence of our iterative method is proved as well. Consequently, the effectiveness and superiority of the proposed method are verified both theoretically and experimentally.