 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
An Empirical Study of World Model Quantization
Feb 02, 2026World models learn an internal representation of environment dynamics, enabling agents to simulate and reason about future states within a compact latent space for tasks such as planning, prediction, and inference. However, running world models rely on hevay computational cost and memory footprint, making model quantization essential for efficient deployment. To date, the effects of post-training quantization (PTQ) on world models remain largely unexamined. In this work, we present a systematic empirical study of world model quantization using DINO-WM as a representative case, evaluating diverse PTQ methods under both weight-only and joint weight-activation settings. We conduct extensive experiments on different visual planning tasks across a wide range of bit-widths, quantization granularities, and planning horizons up to 50 iterations. Our results show that quantization effects in world models extend beyond standard accuracy and bit-width trade-offs: group-wise weight quantization can stabilize low-bit rollouts, activation quantization granularity yields inconsistent benefits, and quantization sensitivity is highly asymmetric between encoder and predictor modules. Moreover, aggressive low-bit quantization significantly degrades the alignment between the planning objective and task success, leading to failures that cannot be remedied by additional optimization. These findings reveal distinct quantization-induced failure modes in world model-based planning and provide practical guidance for deploying quantized world models under strict computational constraints. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/QuantWM.
Diffusion In Diffusion: Reclaiming Global Coherence in Semi-Autoregressive Diffusion
Jan 21, 2026One of the most compelling features of global discrete diffusion language models is their global bidirectional contextual capability. However, existing block-based diffusion studies tend to introduce autoregressive priors, which, while offering benefits, can cause models to lose this global coherence at the macro level. To regain global contextual understanding while preserving the advantages of the semi-autoregressive paradigm, we propose Diffusion in Diffusion, a 'draft-then-refine' framework designed to overcome the irreversibility and myopia problems inherent in block diffusion models. Our approach first employs block diffusion to generate rapid drafts using small blocks, then refines these drafts through global bidirectional diffusion with a larger bidirectional receptive field. We utilize snapshot confidence remasking to identify the most critical tokens that require modification, and apply mix-scale training to expand the block diffusion model's global capabilities. Empirical results demonstrate that our approach sets a new benchmark for discrete diffusion models on the OpenWebText dataset. Using only 26% of the fine-tuning budget of baseline models, we reduce generative perplexity from 25.7 to 21.9, significantly narrowing the performance gap with autoregressive models.
Top 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Deferred Commitment Decoding for Diffusion Language Models with Confidence-Aware Sliding Windows
Jan 05, 2026Diffusion language models (DLMs) have recently emerged as a strong alternative to autoregressive models by enabling parallel text generation. To improve inference efficiency and KV-cache compatibility, prior work commonly adopts block-based diffusion, decoding tokens block by block. However, this paradigm suffers from a structural limitation that we term Boundary-Induced Context Truncation (BICT): undecoded tokens near block boundaries are forced to commit without access to nearby future context, even when such context could substantially reduce uncertainty. This limitation degrades decoding confidence and generation quality, especially for tasks requiring precise reasoning, such as mathematical problem solving and code generation. We propose Deferred Commitment Decoding (DCD), a novel, training-free decoding strategy that mitigates this issue. DCD maintains a confidence-aware sliding window over masked tokens, resolving low-uncertainty tokens early while deferring high-uncertainty tokens until sufficient contextual evidence becomes available. This design enables effective bidirectional information flow within the decoding window without sacrificing efficiency. Extensive experiments across multiple diffusion language models, benchmarks, and caching configurations show that DCD improves generation accuracy by 1.39% with comparable time on average compared to fixed block-based diffusion methods, with the most significant improvement reaching 9.0%. These results demonstrate that deferring token commitment based on uncertainty is a simple yet effective principle for improving both the quality and efficiency of diffusion language model decoding.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025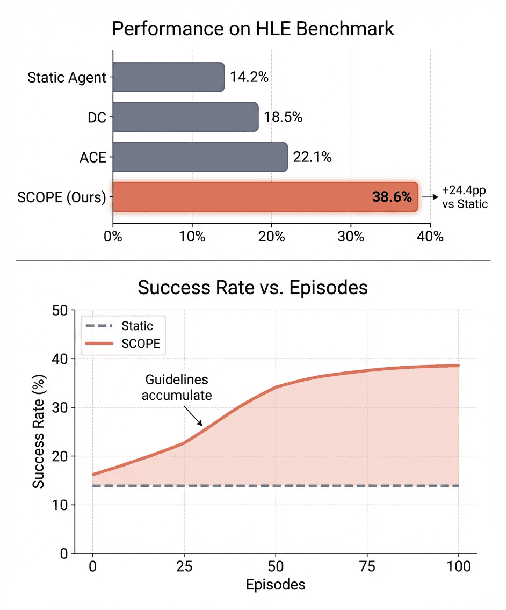
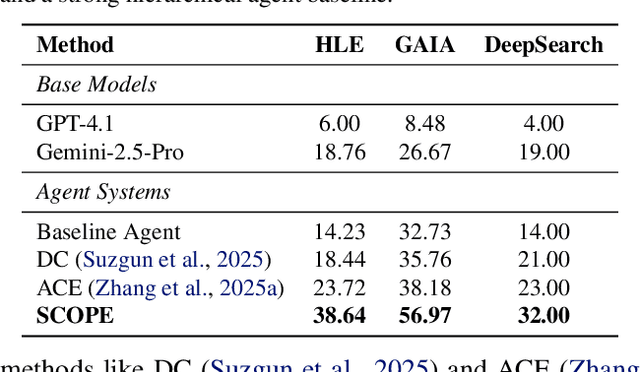
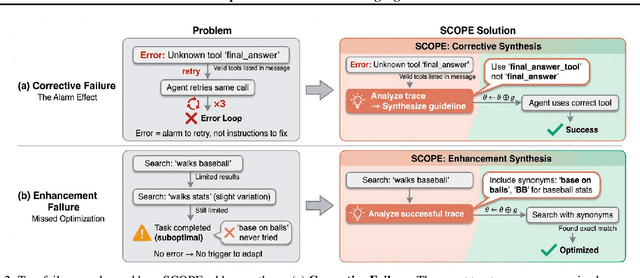
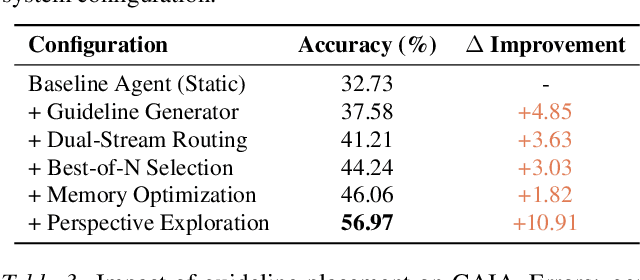
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
VersatileFFN: Achieving Parameter Efficiency in LLMs via Adaptive Wide-and-Deep Reuse
Dec 16, 2025The rapid scaling of Large Language Models (LLMs) has achieved remarkable performance, but it also leads to prohibitive memory costs. Existing parameter-efficient approaches such as pruning and quantization mainly compress pretrained models without enhancing architectural capacity, thereby hitting the representational ceiling of the base model. In this work, we propose VersatileFFN, a novel feed-forward network (FFN) that enables flexible reuse of parameters in both width and depth dimensions within a fixed parameter budget. Inspired by the dual-process theory of cognition, VersatileFFN comprises two adaptive pathways: a width-versatile path that generates a mixture of sub-experts from a single shared FFN, mimicking sparse expert routing without increasing parameters, and a depth-versatile path that recursively applies the same FFN to emulate deeper processing for complex tokens. A difficulty-aware gating dynamically balances the two pathways, steering "easy" tokens through the efficient width-wise route and allocating deeper iterative refinement to "hard" tokens. Crucially, both pathways reuse the same parameters, so all additional capacity comes from computation rather than memory. Experiments across diverse benchmarks and model scales demonstrate the effectiveness of the method. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/VersatileFFN.
Revealing the Power of Post-Training for Small Language Models via Knowledge Distillation
Sep 30, 2025The rapid advancement of large language models (LLMs) has significantly advanced the capabilities of artificial intelligence across various domains. However, their massive scale and high computational costs render them unsuitable for direct deployment in resource-constrained edge environments. This creates a critical need for high-performance small models that can operate efficiently at the edge. Yet, after pre-training alone, these smaller models often fail to meet the performance requirements of complex tasks. To bridge this gap, we introduce a systematic post-training pipeline that efficiently enhances small model accuracy. Our post training pipeline consists of curriculum-based supervised fine-tuning (SFT) and offline on-policy knowledge distillation. The resulting instruction-tuned model achieves state-of-the-art performance among billion-parameter models, demonstrating strong generalization under strict hardware constraints while maintaining competitive accuracy across a variety of tasks. This work provides a practical and efficient solution for developing high-performance language models on Ascend edge devices.
Rethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Aug 09, 2025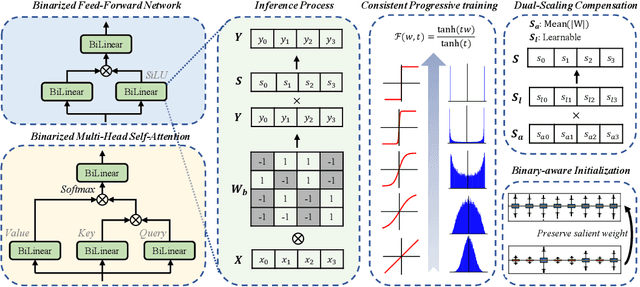

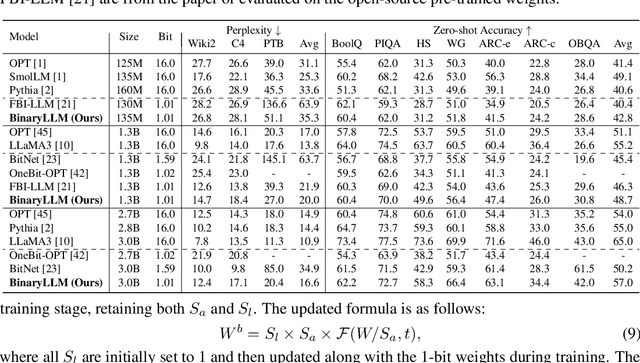
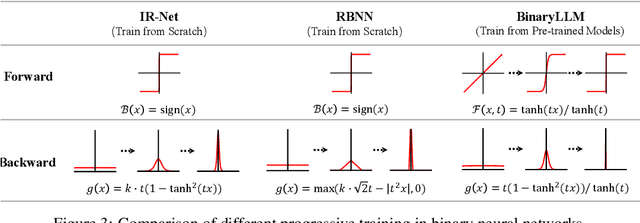
1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes direct adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the floating-point weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.