 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
AgentCollab: A Self-Evaluation-Driven Collaboration Paradigm for Efficient LLM Agents
Mar 27, 2026Autonomous agents powered by large language models (LLMs) perform complex tasks through long-horizon reasoning and tool interaction, where a fundamental trade-off arises between execution efficiency and reasoning robustness. Models at different capability-cost levels offer complementary advantages: lower-cost models enable fast execution but may struggle on difficult reasoning segments, while stronger models provide more robust reasoning at higher computational cost. We present AgentCollab, a self-driven collaborative inference framework that dynamically coordinates models with different reasoning capacities during agent execution. Instead of relying on external routing modules, the framework uses the agent's own self-reflection signal to determine whether the current reasoning trajectory is making meaningful progress, and escalates control to a stronger reasoning tier only when necessary. To further stabilize long-horizon execution, we introduce a difficulty-aware cumulative escalation strategy that allocates additional reasoning budget based on recent failure signals. In our experiments, we instantiate this framework using a two-level small-large model setting. Experiments on diverse multi-step agent benchmarks show that AgentCollab consistently improves the accuracy-efficiency Pareto frontier of LLM agents.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Towards Universal Offline Black-Box Optimization via Learning Language Model Embeddings
Jun 08, 2025The pursuit of universal black-box optimization (BBO) algorithms is a longstanding goal. However, unlike domains such as language or vision, where scaling structured data has driven generalization, progress in offline BBO remains hindered by the lack of unified representations for heterogeneous numerical spaces. Thus, existing offline BBO approaches are constrained to single-task and fixed-dimensional settings, failing to achieve cross-domain universal optimization. Recent advances in language models (LMs) offer a promising path forward: their embeddings capture latent relationships in a unifying way, enabling universal optimization across different data types possible. In this paper, we discuss multiple potential approaches, including an end-to-end learning framework in the form of next-token prediction, as well as prioritizing the learning of latent spaces with strong representational capabilities. To validate the effectiveness of these methods, we collect offline BBO tasks and data from open-source academic works for training. Experiments demonstrate the universality and effectiveness of our proposed methods. Our findings suggest that unifying language model priors and learning string embedding space can overcome traditional barriers in universal BBO, paving the way for general-purpose BBO algorithms. The code is provided at https://github.com/lamda-bbo/universal-offline-bbo.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
TrimR: Verifier-based Training-Free Thinking Compression for Efficient Test-Time Scaling
May 22, 2025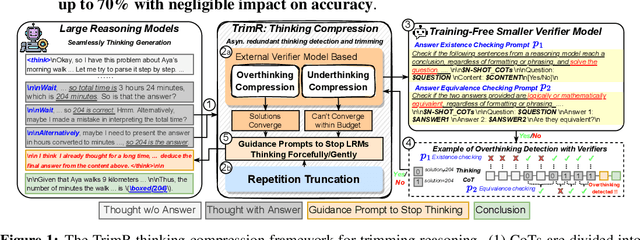
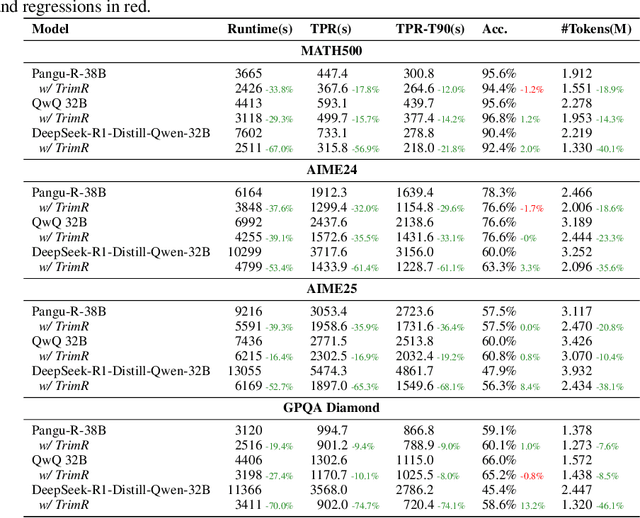
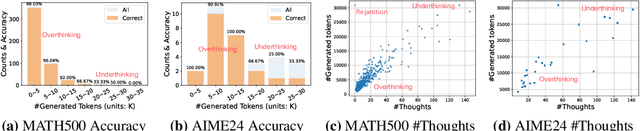
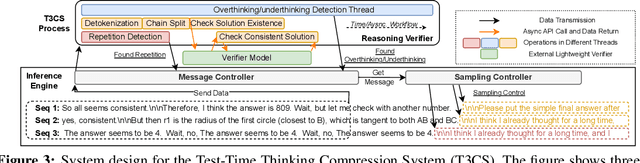
Large Reasoning Models (LRMs) demonstrate exceptional capability in tackling complex mathematical, logical, and coding tasks by leveraging extended Chain-of-Thought (CoT) reasoning. Test-time scaling methods, such as prolonging CoT with explicit token-level exploration, can push LRMs' accuracy boundaries, but they incur significant decoding overhead. A key inefficiency source is LRMs often generate redundant thinking CoTs, which demonstrate clear structured overthinking and underthinking patterns. Inspired by human cognitive reasoning processes and numerical optimization theories, we propose TrimR, a verifier-based, training-free, efficient framework for dynamic CoT compression to trim reasoning and enhance test-time scaling, explicitly tailored for production-level deployment. Our method employs a lightweight, pretrained, instruction-tuned verifier to detect and truncate redundant intermediate thoughts of LRMs without any LRM or verifier fine-tuning. We present both the core algorithm and asynchronous online system engineered for high-throughput industrial applications. Empirical evaluations on Ascend NPUs and vLLM show that our framework delivers substantial gains in inference efficiency under large-batch workloads. In particular, on the four MATH500, AIME24, AIME25, and GPQA benchmarks, the reasoning runtime of Pangu-R-38B, QwQ-32B, and DeepSeek-R1-Distill-Qwen-32B is improved by up to 70% with negligible impact on accuracy.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
NavG: Risk-Aware Navigation in Crowded Environments Based on Reinforcement Learning with Guidance Points
Mar 03, 2025
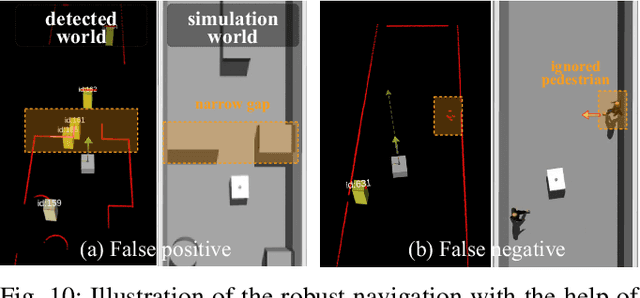
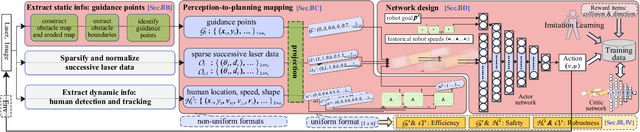

Motion planning in navigation systems is highly susceptible to upstream perceptual errors, particularly in human detection and tracking. To mitigate this issue, the concept of guidance points--a novel directional cue within a reinforcement learning-based framework--is introduced. A structured method for identifying guidance points is developed, consisting of obstacle boundary extraction, potential guidance point detection, and redundancy elimination. To integrate guidance points into the navigation pipeline, a perception-to-planning mapping strategy is proposed, unifying guidance points with other perceptual inputs and enabling the RL agent to effectively leverage the complementary relationships among raw laser data, human detection and tracking, and guidance points. Qualitative and quantitative simulations demonstrate that the proposed approach achieves the highest success rate and near-optimal travel times, greatly improving both safety and efficiency. Furthermore, real-world experiments in dynamic corridors and lobbies validate the robot's ability to confidently navigate around obstacles and robustly avoid pedestrians.
Offline Model-Based Optimization by Learning to Rank
Oct 15, 2024


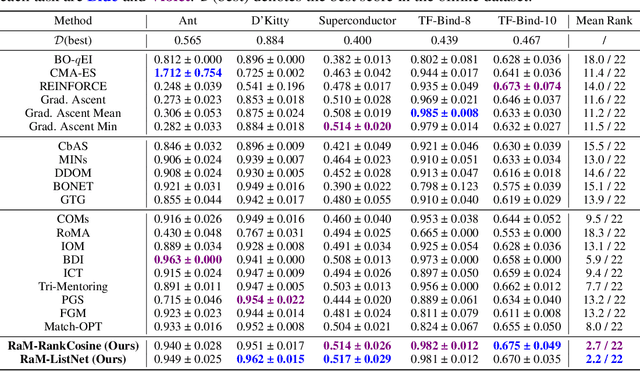
Offline model-based optimization (MBO) aims to identify a design that maximizes a black-box function using only a fixed, pre-collected dataset of designs and their corresponding scores. A common approach in offline MBO is to train a regression-based surrogate model by minimizing mean squared error (MSE) and then find the best design within this surrogate model by different optimizers (e.g., gradient ascent). However, a critical challenge is the risk of out-of-distribution errors, i.e., the surrogate model may typically overestimate the scores and mislead the optimizers into suboptimal regions. Prior works have attempted to address this issue in various ways, such as using regularization techniques and ensemble learning to enhance the robustness of the model, but it still remains. In this paper, we argue that regression models trained with MSE are not well-aligned with the primary goal of offline MBO, which is to select promising designs rather than to predict their scores precisely. Notably, if a surrogate model can maintain the order of candidate designs based on their relative score relationships, it can produce the best designs even without precise predictions. To validate it, we conduct experiments to compare the relationship between the quality of the final designs and MSE, finding that the correlation is really very weak. In contrast, a metric that measures order-maintaining quality shows a significantly stronger correlation. Based on this observation, we propose learning a ranking-based model that leverages learning to rank techniques to prioritize promising designs based on their relative scores. We show that the generalization error on ranking loss can be well bounded. Empirical results across diverse tasks demonstrate the superior performance of our proposed ranking-based models than twenty existing methods.