 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Reinforcement Learning Achieve Expert-level Placement?
Apr 28, 2026Chip placement is a critical step in physical design. While reinforcement learning (RL)-based methods have recently emerged, their training primarily focuses on wirelength optimization, and therefore often fail to achieve expert-quality layouts. We identify the reward design as the primary cause for the performance gap with experts, and instead of formalizing intricate processes, we circumvent this by directly learning from expert layouts to derive a reward model. Our approach starts from the final expert layouts to infer step-by-step expert trajectories. Using these trajectories as demonstrations or preferences, we train a model that captures the latent implicit rewards in expert results. Experiments show that our framework can efficiently learn from even a single design and generalize well to unseen cases.
FlowPlace: Flow Matching for Chip Placement
Apr 26, 2026Chip placement plays an important role in physical design. While generative models like diffusion models offer promising learning-based solutions, current methods have the following limitations: they use random synthetic data for pre-training, require long sampling times, and often result in overlaps due to their dependence on gradient-based solvers during the sampling process. To overcome these issues, we propose FlowPlace, which features mask-guided synthetic data generation, flow-based efficient training with flexible prior injection, and hard constraint sampling for overlap-free layouts. Experiments on OpenROAD and ICCAD 2015 benchmarks show FlowPlace achieves better PPA metrics, 10-50$\times$ faster sampling efficiency, and zero overlaps.
Robust Length Prediction: A Perspective from Heavy-Tailed Prompt-Conditioned Distributions
Apr 09, 2026Output-length prediction is important for efficient LLM serving, as it directly affects batching, memory reservation, and scheduling. For prompt-only length prediction, most existing methods use a one-shot sampled length as the label, implicitly treating each prompt as if it had one true target length. We show that this is unreliable: even under a fixed model and decoding setup, the same prompt induces a \emph{prompt-conditioned output length distribution}, not a deterministic scalar, and this distribution is consistent with \emph{heavy-tailed} behavior. Motivated by this, we cast length prediction as robust estimation from heavy-tailed prompt-conditioned length distributions. We propose prompt-conditioned length distribution (ProD) methods, which construct training targets from multiple independent generations of the same prompt. Two variants are developed to reuse the served LLM's hidden states: \mbox{ProD-M}, which uses a median-based target for robust point prediction, and ProD-D, which uses a distributional target that preserves prompt-conditioned uncertainty. We provide theoretical justifications by analyzing the estimation error under a surrogate model. Experiments across diverse scenarios show consistent gains in prediction quality.
Advancing Automated Algorithm Design via Evolutionary Stagewise Design with LLMs
Mar 09, 2026With the rapid advancement of human science and technology, problems in industrial scenarios are becoming increasingly challenging, bringing significant challenges to traditional algorithm design. Automated algorithm design with LLMs emerges as a promising solution, but the currently adopted black-box modeling deprives LLMs of any awareness of the intrinsic mechanism of the target problem, leading to hallucinated designs. In this paper, we introduce Evolutionary Stagewise Algorithm Design (EvoStage), a novel evolutionary paradigm that bridges the gap between the rigorous demands of industrial-scale algorithm design and the LLM-based algorithm design methods. Drawing inspiration from CoT, EvoStage decomposes the algorithm design process into sequential, manageable stages and integrates real-time intermediate feedback to iteratively refine algorithm design directions. To further reduce the algorithm design space and avoid falling into local optima, we introduce a multi-agent system and a "global-local perspective" mechanism. We apply EvoStage to the design of two types of common optimizers: designing parameter configuration schedules of the Adam optimizer for chip placement, and designing acquisition functions of Bayesian optimization for black-box optimization. Experimental results across open-source benchmarks demonstrate that EvoStage outperforms human-expert designs and existing LLM-based methods within only a couple of evolution steps, even achieving the historically state-of-the-art half-perimeter wire-length results on every tested chip case. Furthermore, when deployed on a commercial-grade 3D chip placement tool, EvoStage significantly surpasses the original performance metrics, achieving record-breaking efficiency. We hope EvoStage can significantly advance automated algorithm design in the real world, helping elevate human productivity.
On the Learnability of Offline Model-Based Optimization: A Ranking Perspective
Mar 04, 2026Offline model-based optimization (MBO) seeks to discover high-performing designs using only a fixed dataset of past evaluations. Most existing methods rely on learning a surrogate model via regression and implicitly assume that good predictive accuracy leads to good optimization performance. In this work, we challenge this assumption and study offline MBO from a learnability perspective. We argue that offline optimization is fundamentally a problem of ranking high-quality designs rather than accurate value prediction. Specifically, we introduce an optimization-oriented risk based on ranking between near-optimal and suboptimal designs, and develop a unified theoretical framework that connects surrogate learning to final optimization. We prove the theoretical advantages of ranking over regression, and identify distributional mismatch between the training data and near-optimal designs as the dominant error. Inspired by this, we design a distribution-aware ranking method to reduce this mismatch. Empirical results across various tasks show that our approach outperforms twenty existing methods, validating our theoretical findings. Additionally, both theoretical and empirical results reveal intrinsic limitations in offline MBO, showing a regime in which no offline method can avoid over-optimistic extrapolation.
Dual-View Predictive Diffusion: Lightweight Speech Enhancement via Spectrogram-Image Synergy
Jan 31, 2026Diffusion models have recently set new benchmarks in Speech Enhancement (SE). However, most existing score-based models treat speech spectrograms merely as generic 2D images, applying uniform processing that ignores the intrinsic structural sparsity of audio, which results in inefficient spectral representation and prohibitive computational complexity. To bridge this gap, we propose DVPD, an extremely lightweight Dual-View Predictive Diffusion model, which uniquely exploits the dual nature of spectrograms as both visual textures and physical frequency-domain representations across both training and inference stages. Specifically, during training, we optimize spectral utilization via the Frequency-Adaptive Non-uniform Compression (FANC) encoder, which preserves critical low-frequency harmonics while pruning high-frequency redundancies. Simultaneously, we introduce a Lightweight Image-based Spectro-Awareness (LISA) module to capture features from a visual perspective with minimal overhead. During inference, we propose a Training-free Lossless Boost (TLB) strategy that leverages the same dual-view priors to refine generation quality without any additional fine-tuning. Extensive experiments across various benchmarks demonstrate that DVPD achieves state-of-the-art performance while requiring only 35% of the parameters and 40% of the inference MACs compared to SOTA lightweight model, PGUSE. These results highlight DVPD's superior ability to balance high-fidelity speech quality with extreme architectural efficiency. Code and audio samples are available at the anonymous website: {https://anonymous.4open.science/r/dvpd_demo-E630}
Omni-directional attention mechanism based on Mamba for speech separation
Jan 23, 2026Mamba, a selective state-space model (SSM), has emerged as an efficient alternative to Transformers for speech modeling, enabling long-sequence processing with linear complexity. While effective in speech separation, existing approaches, whether in the time or time-frequency domain, typically decompose the input along a single dimension into short one-dimensional sequences before processing them with Mamba, which restricts it to local 1D modeling and limits its ability to capture global dependencies across the 2D spectrogram. In this work, we propose an efficient omni-directional attention (OA) mechanism built upon unidirectional Mamba, which models global dependencies from ten different directions on the spectrogram. We expand the proposed mechanism into two baseline separation models and evaluate on three public datasets. Experimental results show that our approach consistently achieves significant performance gains over the baselines while preserving linear complexity, outperforming existing state-of-the-art (SOTA) systems.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025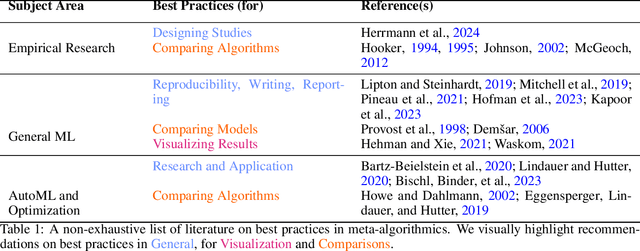
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.
Quality-Diversity Red-Teaming: Automated Generation of High-Quality and Diverse Attackers for Large Language Models
Jun 08, 2025Ensuring safety of large language models (LLMs) is important. Red teaming--a systematic approach to identifying adversarial prompts that elicit harmful responses from target LLMs--has emerged as a crucial safety evaluation method. Within this framework, the diversity of adversarial prompts is essential for comprehensive safety assessments. We find that previous approaches to red-teaming may suffer from two key limitations. First, they often pursue diversity through simplistic metrics like word frequency or sentence embedding similarity, which may not capture meaningful variation in attack strategies. Second, the common practice of training a single attacker model restricts coverage across potential attack styles and risk categories. This paper introduces Quality-Diversity Red-Teaming (QDRT), a new framework designed to address these limitations. QDRT achieves goal-driven diversity through behavior-conditioned training and implements a behavioral replay buffer in an open-ended manner. Additionally, it trains multiple specialized attackers capable of generating high-quality attacks across diverse styles and risk categories. Our empirical evaluation demonstrates that QDRT generates attacks that are both more diverse and more effective against a wide range of target LLMs, including GPT-2, Llama-3, Gemma-2, and Qwen2.5. This work advances the field of LLM safety by providing a systematic and effective approach to automated red-teaming, ultimately supporting the responsible deployment of LLMs.