 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Reinforcement Learning Achieve Expert-level Placement?
Apr 28, 2026Chip placement is a critical step in physical design. While reinforcement learning (RL)-based methods have recently emerged, their training primarily focuses on wirelength optimization, and therefore often fail to achieve expert-quality layouts. We identify the reward design as the primary cause for the performance gap with experts, and instead of formalizing intricate processes, we circumvent this by directly learning from expert layouts to derive a reward model. Our approach starts from the final expert layouts to infer step-by-step expert trajectories. Using these trajectories as demonstrations or preferences, we train a model that captures the latent implicit rewards in expert results. Experiments show that our framework can efficiently learn from even a single design and generalize well to unseen cases.
FlowPlace: Flow Matching for Chip Placement
Apr 26, 2026Chip placement plays an important role in physical design. While generative models like diffusion models offer promising learning-based solutions, current methods have the following limitations: they use random synthetic data for pre-training, require long sampling times, and often result in overlaps due to their dependence on gradient-based solvers during the sampling process. To overcome these issues, we propose FlowPlace, which features mask-guided synthetic data generation, flow-based efficient training with flexible prior injection, and hard constraint sampling for overlap-free layouts. Experiments on OpenROAD and ICCAD 2015 benchmarks show FlowPlace achieves better PPA metrics, 10-50$\times$ faster sampling efficiency, and zero overlaps.
Advancing Automated Algorithm Design via Evolutionary Stagewise Design with LLMs
Mar 09, 2026With the rapid advancement of human science and technology, problems in industrial scenarios are becoming increasingly challenging, bringing significant challenges to traditional algorithm design. Automated algorithm design with LLMs emerges as a promising solution, but the currently adopted black-box modeling deprives LLMs of any awareness of the intrinsic mechanism of the target problem, leading to hallucinated designs. In this paper, we introduce Evolutionary Stagewise Algorithm Design (EvoStage), a novel evolutionary paradigm that bridges the gap between the rigorous demands of industrial-scale algorithm design and the LLM-based algorithm design methods. Drawing inspiration from CoT, EvoStage decomposes the algorithm design process into sequential, manageable stages and integrates real-time intermediate feedback to iteratively refine algorithm design directions. To further reduce the algorithm design space and avoid falling into local optima, we introduce a multi-agent system and a "global-local perspective" mechanism. We apply EvoStage to the design of two types of common optimizers: designing parameter configuration schedules of the Adam optimizer for chip placement, and designing acquisition functions of Bayesian optimization for black-box optimization. Experimental results across open-source benchmarks demonstrate that EvoStage outperforms human-expert designs and existing LLM-based methods within only a couple of evolution steps, even achieving the historically state-of-the-art half-perimeter wire-length results on every tested chip case. Furthermore, when deployed on a commercial-grade 3D chip placement tool, EvoStage significantly surpasses the original performance metrics, achieving record-breaking efficiency. We hope EvoStage can significantly advance automated algorithm design in the real world, helping elevate human productivity.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.
Open3DBench: Open-Source Benchmark for 3D-IC Backend Implementation and PPA Evaluation
Mar 17, 2025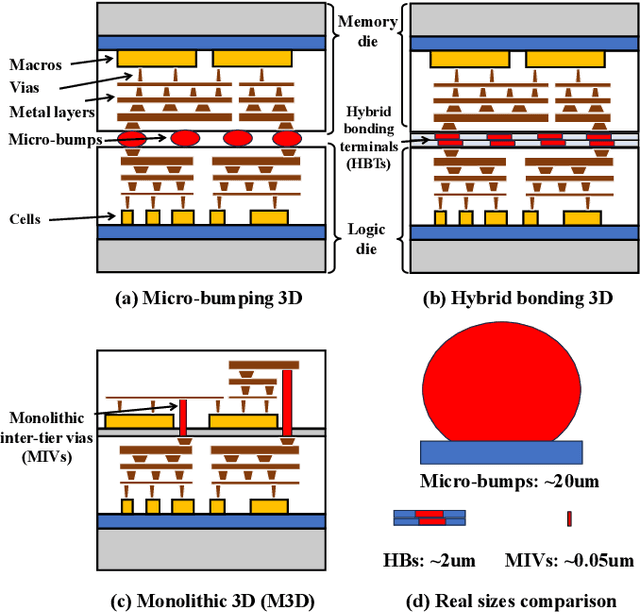
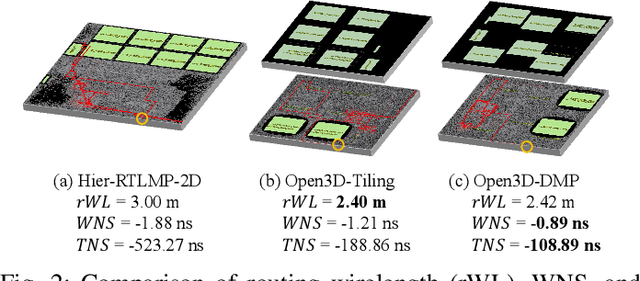
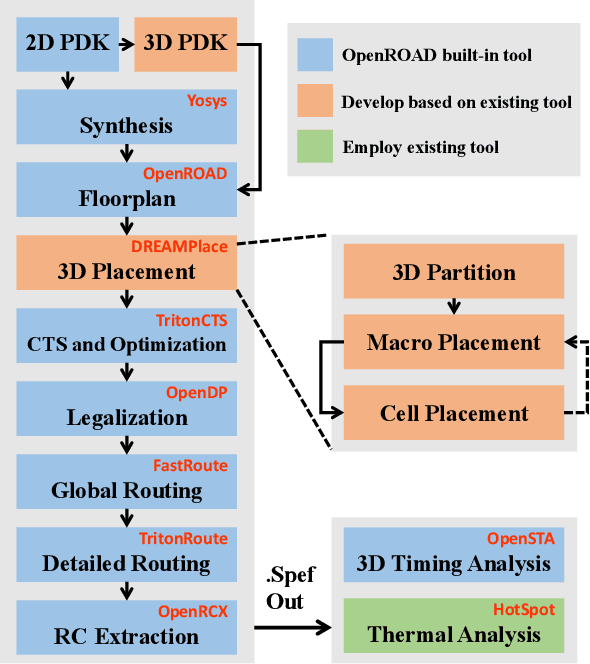

This work introduces Open3DBench, an open-source 3D-IC backend implementation benchmark built upon the OpenROAD-flow-scripts framework, enabling comprehensive evaluation of power, performance, area, and thermal metrics. Our proposed flow supports modular integration of 3D partitioning, placement, 3D routing, RC extraction, and thermal simulation, aligning with advanced 3D flows that rely on commercial tools and in-house scripts. We present two foundational 3D placement algorithms: Open3D-Tiling, which emphasizes regular macro placement, and Open3D-DMP, which enhances wirelength optimization through cross-die co-placement with analytical placer DREAMPlace. Experimental results show significant improvements in area (51.19%), wirelength (24.06%), timing (30.84%), and power (5.72%) compared to 2D flows. The results also highlight that better wirelength does not necessarily lead to PPA gain, emphasizing the need of developing PPA-driven methods. Open3DBench offers a standardized, reproducible platform for evaluating 3D EDA methods, effectively bridging the gap between open-source tools and commercial solutions in 3D-IC design.
Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer
Dec 10, 2024



In modern chip design, placement aims at placing millions of circuit modules, which is an essential step that significantly influences power, performance, and area (PPA) metrics. Recently, reinforcement learning (RL) has emerged as a promising technique for improving placement quality, especially macro placement. However, current RL-based placement methods suffer from long training times, low generalization ability, and inability to guarantee PPA results. A key issue lies in the problem formulation, i.e., using RL to place from scratch, which results in limits useful information and inaccurate rewards during the training process. In this work, we propose an approach that utilizes RL for the refinement stage, which allows the RL policy to learn how to adjust existing placement layouts, thereby receiving sufficient information for the policy to act and obtain relatively dense and precise rewards. Additionally, we introduce the concept of regularity during training, which is considered an important metric in the chip design industry but is often overlooked in current RL placement methods. We evaluate our approach on the ISPD 2005 and ICCAD 2015 benchmark, comparing the global half-perimeter wirelength and regularity of our proposed method against several competitive approaches. Besides, we test the PPA performance using commercial software, showing that RL as a regulator can achieve significant PPA improvements. Our RL regulator can fine-tune placements from any method and enhance their quality. Our work opens up new possibilities for the application of RL in placement, providing a more effective and efficient approach to optimizing chip design. Our code is available at \url{https://github.com/lamda-bbo/macro-regulator}.
Escaping Local Optima in Global Placement
Feb 28, 2024Placement is crucial in the physical design, as it greatly affects power, performance, and area metrics. Recent advancements in analytical methods, such as DREAMPlace, have demonstrated impressive performance in global placement. However, DREAMPlace has some limitations, e.g., may not guarantee legalizable placements under the same settings, leading to fragile and unpredictable results. This paper highlights the main issue as being stuck in local optima, and proposes a hybrid optimization framework to efficiently escape the local optima, by perturbing the placement result iteratively. The proposed framework achieves significant improvements compared to state-of-the-art methods on two popular benchmarks.
Macro Placement by Wire-Mask-Guided Black-Box Optimization
Jul 18, 2023



The development of very large-scale integration (VLSI) technology has posed new challenges for electronic design automation (EDA) techniques in chip floorplanning. During this process, macro placement is an important subproblem, which tries to determine the positions of all macros with the aim of minimizing half-perimeter wirelength (HPWL) and avoiding overlapping. Previous methods include packing-based, analytical and reinforcement learning methods. In this paper, we propose a new black-box optimization (BBO) framework (called WireMask-BBO) for macro placement, by using a wire-mask-guided greedy procedure for objective evaluation. Equipped with different BBO algorithms, WireMask-BBO empirically achieves significant improvements over previous methods, i.e., achieves significantly shorter HPWL by using much less time. Furthermore, it can fine-tune existing placements by treating them as initial solutions, which can bring up to 50% improvement in HPWL. WireMask-BBO has the potential to significantly improve the quality and efficiency of chip floorplanning, which makes it appealing to researchers and practitioners in EDA and will also promote the application of BBO.