 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
Why Attention Patterns Exist: A Unifying Temporal Perspective Analysis
Jan 29, 2026Attention patterns play a crucial role in both training and inference of large language models (LLMs). Prior works have identified individual patterns such as retrieval heads, sink heads, and diagonal traces, yet these observations remain fragmented and lack a unifying explanation. To bridge this gap, we introduce \textbf{Temporal Attention Pattern Predictability Analysis (TAPPA), a unifying framework that explains diverse attention patterns by analyzing their underlying mathematical formulations} from a temporally continuous perspective. TAPPA both deepens the understanding of attention behavior and guides inference acceleration approaches. Specifically, TAPPA characterizes attention patterns as predictable patterns with clear regularities and unpredictable patterns that appear effectively random. Our analysis further reveals that this distinction can be explained by the degree of query self-similarity along the temporal dimension. Focusing on the predictable patterns, we further provide a detailed mathematical analysis of three representative cases through the joint effect of queries, keys, and Rotary Positional Embeddings (RoPE). We validate TAPPA by applying its insights to KV cache compression and LLM pruning tasks. Across these tasks, a simple metric motivated by TAPPA consistently improves performance over baseline methods. The code is available at https://github.com/MIRALab-USTC/LLM-TAPPA.
Beyond Speedup -- Utilizing KV Cache for Sampling and Reasoning
Jan 28, 2026KV caches, typically used only to speed up autoregressive decoding, encode contextual information that can be reused for downstream tasks at no extra cost. We propose treating the KV cache as a lightweight representation, eliminating the need to recompute or store full hidden states. Despite being weaker than dedicated embeddings, KV-derived representations are shown to be sufficient for two key applications: \textbf{(i) Chain-of-Embedding}, where they achieve competitive or superior performance on Llama-3.1-8B-Instruct and Qwen2-7B-Instruct; and \textbf{(ii) Fast/Slow Thinking Switching}, where they enable adaptive reasoning on Qwen3-8B and DeepSeek-R1-Distil-Qwen-14B, reducing token generation by up to $5.7\times$ with minimal accuracy loss. Our findings establish KV caches as a free, effective substrate for sampling and reasoning, opening new directions for representation reuse in LLM inference. Code: https://github.com/cmd2001/ICLR2026_KV-Embedding.
RIFT: Repurposing Negative Samples via Reward-Informed Fine-Tuning
Jan 14, 2026While Supervised Fine-Tuning (SFT) and Rejection Sampling Fine-Tuning (RFT) are standard for LLM alignment, they either rely on costly expert data or discard valuable negative samples, leading to data inefficiency. To address this, we propose Reward Informed Fine-Tuning (RIFT), a simple yet effective framework that utilizes all self-generated samples. Unlike the hard thresholding of RFT, RIFT repurposes negative trajectories, reweighting the loss with scalar rewards to learn from both the positive and negative trajectories from the model outputs. To overcome the training collapse caused by naive reward integration, where direct multiplication yields an unbounded loss, we introduce a stabilized loss formulation that ensures numerical robustness and optimization efficiency. Extensive experiments on mathematical benchmarks across various base models show that RIFT consistently outperforms RFT. Our results demonstrate that RIFT is a robust and data-efficient alternative for alignment using mixed-quality, self-generated data.
SwiftMem: Fast Agentic Memory via Query-aware Indexing
Jan 13, 2026Agentic memory systems have become critical for enabling LLM agents to maintain long-term context and retrieve relevant information efficiently. However, existing memory frameworks suffer from a fundamental limitation: they perform exhaustive retrieval across the entire storage layer regardless of query characteristics. This brute-force approach creates severe latency bottlenecks as memory grows, hindering real-time agent interactions. We propose SwiftMem, a query-aware agentic memory system that achieves sub-linear retrieval through specialized indexing over temporal and semantic dimensions. Our temporal index enables logarithmic-time range queries for time-sensitive retrieval, while the semantic DAG-Tag index maps queries to relevant topics through hierarchical tag structures. To address memory fragmentation during growth, we introduce an embedding-tag co-consolidation mechanism that reorganizes storage based on semantic clusters to improve cache locality. Experiments on LoCoMo and LongMemEval benchmarks demonstrate that SwiftMem achieves 47$\times$ faster search compared to state-of-the-art baselines while maintaining competitive accuracy, enabling practical deployment of memory-augmented LLM agents.
Revisiting Judge Decoding from First Principles via Training-Free Distributional Divergence
Jan 08, 2026Judge Decoding accelerates LLM inference by relaxing the strict verification of Speculative Decoding, yet it typically relies on expensive and noisy supervision. In this work, we revisit this paradigm from first principles, revealing that the ``criticality'' scores learned via costly supervision are intrinsically encoded in the draft-target distributional divergence. We theoretically prove a structural correspondence between learned linear judges and Kullback-Leibler (KL) divergence, demonstrating they rely on the same underlying logit primitives. Guided by this, we propose a simple, training-free verification mechanism based on KL divergence. Extensive experiments across reasoning and coding benchmarks show that our method matches or outperforms complex trained judges (e.g., AutoJudge), offering superior robustness to domain shifts and eliminating the supervision bottleneck entirely.
What Matters For Safety Alignment?
Jan 07, 2026This paper presents a comprehensive empirical study on the safety alignment capabilities. We evaluate what matters for safety alignment in LLMs and LRMs to provide essential insights for developing more secure and reliable AI systems. We systematically investigate and compare the influence of six critical intrinsic model characteristics and three external attack techniques. Our large-scale evaluation is conducted using 32 recent, popular LLMs and LRMs across thirteen distinct model families, spanning a parameter scale from 3B to 235B. The assessment leverages five established safety datasets and probes model vulnerabilities with 56 jailbreak techniques and four CoT attack strategies, resulting in 4.6M API calls. Our key empirical findings are fourfold. First, we identify the LRMs GPT-OSS-20B, Qwen3-Next-80B-A3B-Thinking, and GPT-OSS-120B as the top-three safest models, which substantiates the significant advantage of integrated reasoning and self-reflection mechanisms for robust safety alignment. Second, post-training and knowledge distillation may lead to a systematic degradation of safety alignment. We thus argue that safety must be treated as an explicit constraint or a core optimization objective during these stages, not merely subordinated to the pursuit of general capability. Third, we reveal a pronounced vulnerability: employing a CoT attack via a response prefix can elevate the attack success rate by 3.34x on average and from 0.6% to 96.3% for Seed-OSS-36B-Instruct. This critical finding underscores the safety risks inherent in text-completion interfaces and features that allow user-defined response prefixes in LLM services, highlighting an urgent need for architectural and deployment safeguards. Fourth, roleplay, prompt injection, and gradient-based search for adversarial prompts are the predominant methodologies for eliciting unaligned behaviors in modern models.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025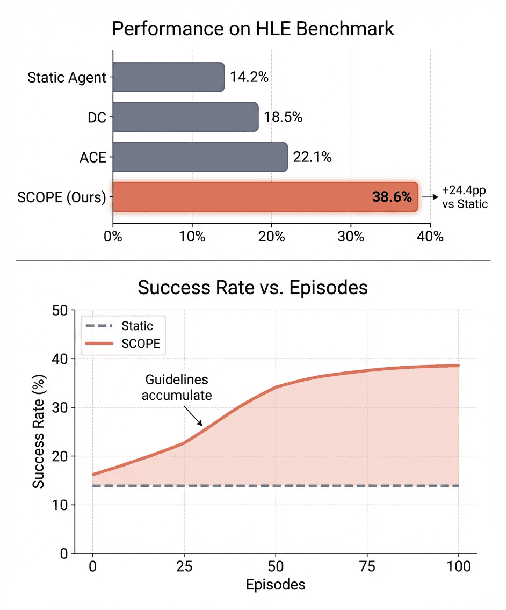
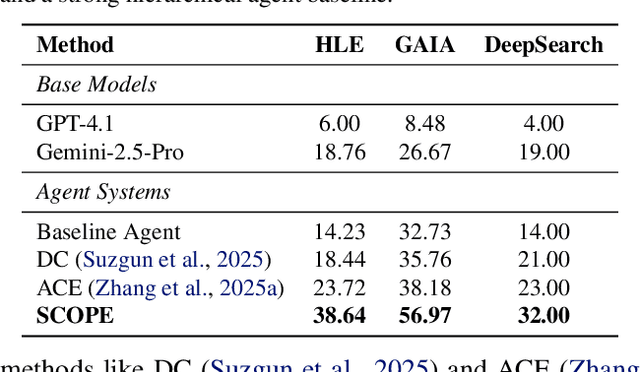
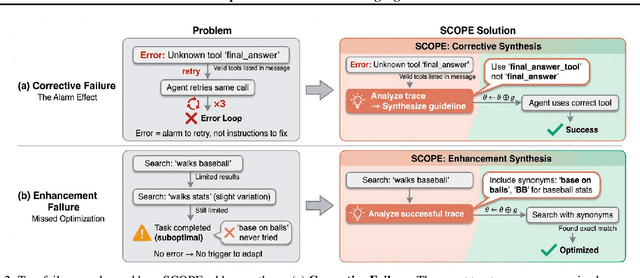
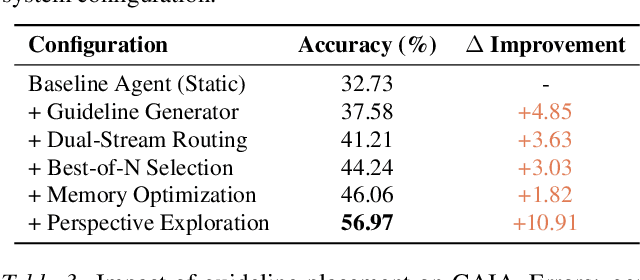
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.