 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerilog-Evolve: Feedback-Driven and Skill-Evolving Verilog Generation
May 26, 2026Large language models (LLMs) have improved Verilog generation from natural-language specifications, but most pipelines still treat generation as isolated sampling followed by functional checking. This is insufficient for practical RTL design, where useful Verilog must be correct, synthesizable, timing-conscious, and friendly to downstream hardware objectives. We present Verilog-Evolve, a feedback-driven framework for versioned Verilog refinement and cross-session skill evolution. For each task, Verilog-Evolve generates diverse minor candidates, evaluates them with executable feedback from functional simulation, Yosys synthesis, ABC timing proxy, and optional GEMM metrics, then promotes the best candidate into a major version under configurable scoring. To improve across tasks, the system maintains modular skill guidance, retrieves skills according to task and feedback context, and evolves candidate skills from logged histories through create/improve/skip decisions and verifier reports. Experiments on VerilogEval and mixed-precision GEMM tasks show that Verilog-Evolve improves final functional success and promotion stability while producing more downstream-friendly RTL under open-source synthesis, timing-proxy, and netlist-level GEMM objectives. Validation-gated skill evolution further improves GEMM downstream quality and achieves the best downstream score and GEMM held-out pass rate among the evaluated skill modes.
MetaMoE: Diversity-Aware Proxy Selection for Privacy-Preserving Mixture-of-Experts Unification
May 14, 2026Mixture-of-Experts (MoE) models scale capacity by combining specialized experts, but most existing approaches assume centralized access to training data. In practice, data are distributed across clients and cannot be shared due to privacy constraints, making unified MoE training challenging. We propose MetaMoE, a privacy-preserving framework that unifies independently trained, domain-specialized experts into a single MoE using public proxy data as surrogates for inaccessible private data. Central to MetaMoE is diversity-aware proxy selection, which selects client-domain-relevant and diverse samples from public data to effectively approximate private data distributions and supervise router learning. These proxies are further used to align expert training, improving expert coordination at unification time, while a context-aware router enhances expert selection across heterogeneous inputs. Experiments on computer vision and natural language processing benchmarks demonstrate that MetaMoE consistently outperforms recent privacy-preserving MoE unification methods. Code is available at https://github.com/ws-jiang/MetaMoE.
FocuSFT: Bilevel Optimization for Dilution-Aware Long-Context Fine-Tuning
May 11, 2026Large language models can now process increasingly long inputs, yet their ability to effectively use information spread across long contexts remains limited. We trace this gap to how attention budget is spent during supervised fine-tuning (SFT) on long sequences: positional biases and attention sinks cause the model to allocate most of its attention to positionally privileged tokens rather than semantically relevant content. This training-time attention dilution (the starvation of content tokens in the attention distribution) weakens the gradient signal, limiting the model's ability to learn robust long-context capabilities. We introduce FocuSFT, a bilevel optimization framework that addresses this problem at training time. An inner loop adapts lightweight fast-weight parameters on the training context to form a parametric memory that concentrates attention on relevant content, and the outer loop performs SFT conditioned on this sharpened representation. Both loops apply bidirectional attention over context tokens while preserving causal masking for responses, reducing the causal asymmetry that gives rise to attention sinks and aligning inner-outer behavior. On BABILong, FocuSFT improves accuracy by up to +14pp across 4K--32K context lengths; on RULER, it raises CWE aggregation from 72.9\% to 81.1\% at 16K; and on GPQA with agentic tool use, it yields a 24\% relative gain in pass@1. Attention analysis shows that FocuSFT reduces attention sink mass by 529$\times$ and triples context engagement during training. Code: https://github.com/JarvisPei/FocuSFT
MemDLM: Memory-Enhanced DLM Training
Mar 23, 2026Diffusion Language Models (DLMs) offer attractive advantages over Auto-Regressive (AR) models, such as full-attention parallel decoding and flexible generation. However, they suffer from a notable train-inference mismatch: DLMs are trained with a static, single-step masked prediction objective, but deployed through a multi-step progressive denoising trajectory. We propose MemDLM (Memory-Enhanced DLM), which narrows this gap by embedding a simulated denoising process into training via Bi-level Optimization. An inner loop updates a set of fast weights, forming a Parametric Memory that captures the local trajectory experience of each sample, while an outer loop updates the base model conditioned on this memory. By offloading memorization pressure from token representations to parameters, MemDLM yields faster convergence and lower training loss. Moreover, the inner loop can be re-enabled at inference time as an adaptation step, yielding additional gains on long-context understanding. We find that, when activated at inference time, this Parametric Memory acts as an emergent in-weight retrieval mechanism, helping MemDLM further reduce token-level attention bottlenecks on challenging Needle-in-a-Haystack retrieval tasks. Code: https://github.com/JarvisPei/MemDLM.
Beyond Speedup -- Utilizing KV Cache for Sampling and Reasoning
Jan 28, 2026KV caches, typically used only to speed up autoregressive decoding, encode contextual information that can be reused for downstream tasks at no extra cost. We propose treating the KV cache as a lightweight representation, eliminating the need to recompute or store full hidden states. Despite being weaker than dedicated embeddings, KV-derived representations are shown to be sufficient for two key applications: \textbf{(i) Chain-of-Embedding}, where they achieve competitive or superior performance on Llama-3.1-8B-Instruct and Qwen2-7B-Instruct; and \textbf{(ii) Fast/Slow Thinking Switching}, where they enable adaptive reasoning on Qwen3-8B and DeepSeek-R1-Distil-Qwen-14B, reducing token generation by up to $5.7\times$ with minimal accuracy loss. Our findings establish KV caches as a free, effective substrate for sampling and reasoning, opening new directions for representation reuse in LLM inference. Code: https://github.com/cmd2001/ICLR2026_KV-Embedding.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025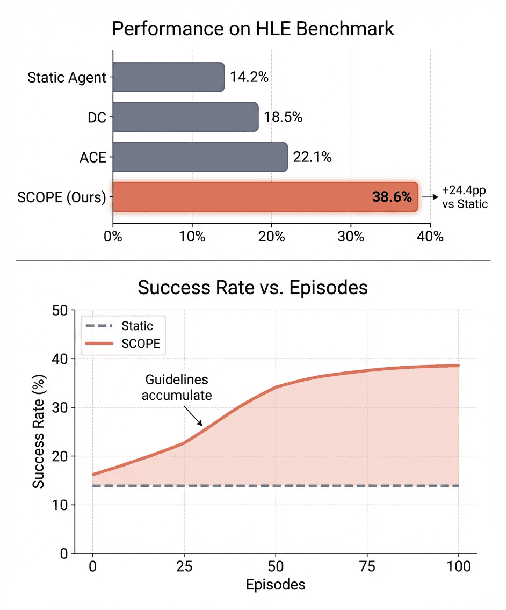
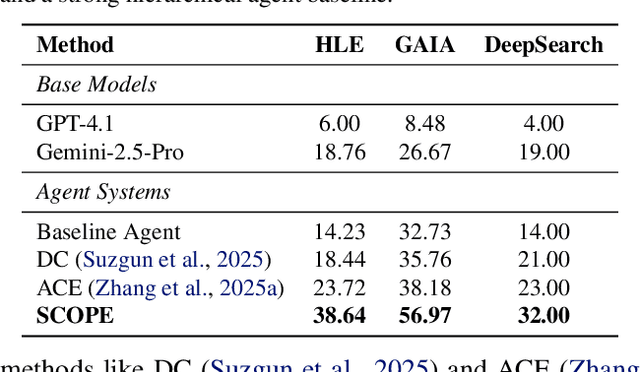
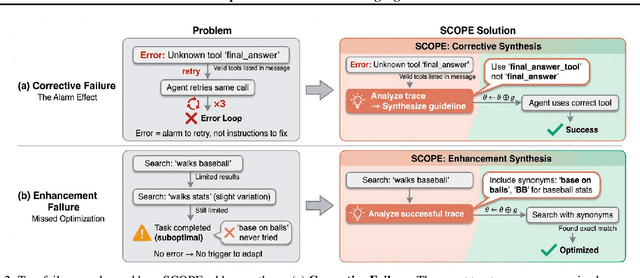
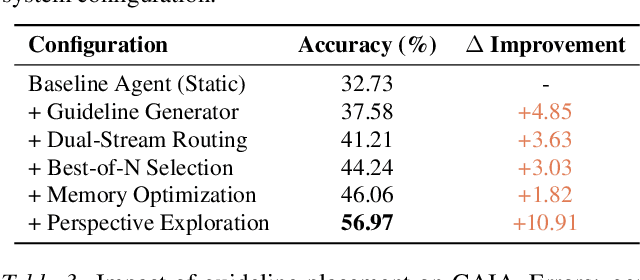
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
MetaDefense: Defending Finetuning-based Jailbreak Attack Before and During Generation
Oct 09, 2025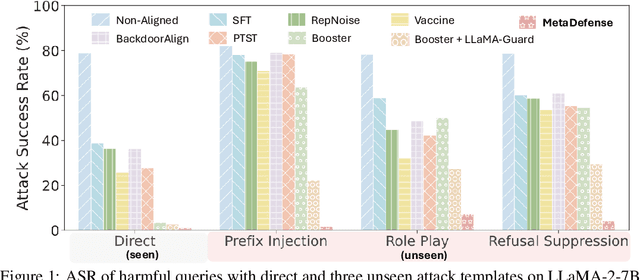


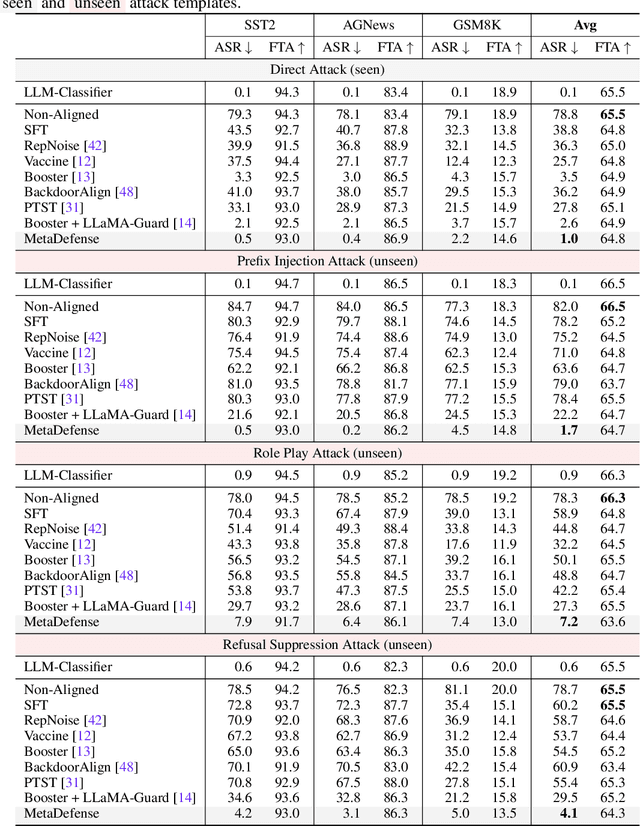
This paper introduces MetaDefense, a novel framework for defending against finetuning-based jailbreak attacks in large language models (LLMs). We observe that existing defense mechanisms fail to generalize to harmful queries disguised by unseen attack templates, despite LLMs being capable of distinguishing disguised harmful queries in the embedding space. Based on these insights, we propose a two-stage defense approach: (i) pre-generation defense that detects harmful queries before response generation begins, and (ii) mid-generation defense that monitors partial responses during generation to prevent outputting more harmful content. Our MetaDefense trains the LLM to predict the harmfulness of both queries and partial responses using specialized prompts, enabling early termination of potentially harmful interactions. Extensive experiments across multiple LLM architectures (LLaMA-2-7B, Qwen-2.5-3B-Instruct, and LLaMA-3.2-3B-Instruct) demonstrate that MetaDefense significantly outperforms existing defense mechanisms, achieving robust defense against harmful queries with seen and unseen attack templates while maintaining competitive performance on benign tasks. Code is available at https://github.com/ws-jiang/MetaDefense.
PreMoe: Lightening MoEs on Constrained Memory by Expert Pruning and Retrieval
May 23, 2025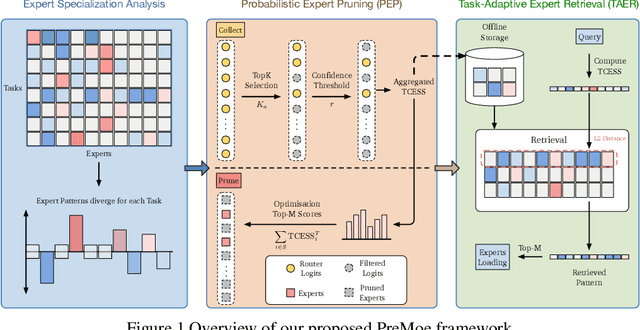
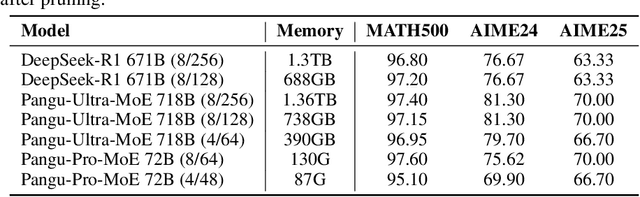
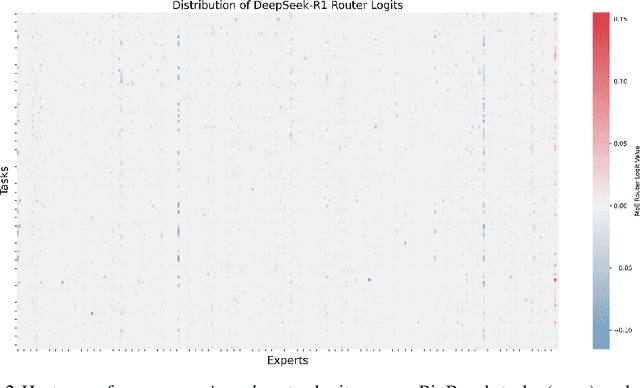
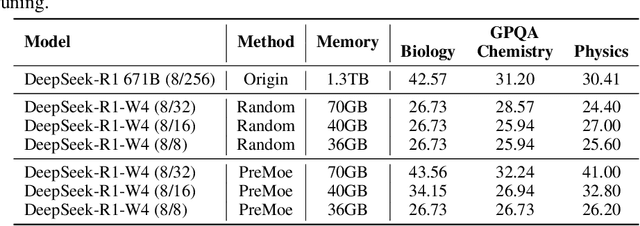
Mixture-of-experts (MoE) architectures enable scaling large language models (LLMs) to vast parameter counts without a proportional rise in computational costs. However, the significant memory demands of large MoE models hinder their deployment across various computational environments, from cloud servers to consumer devices. This study first demonstrates pronounced task-specific specialization in expert activation patterns within MoE layers. Building on this, we introduce PreMoe, a novel framework that enables efficient deployment of massive MoE models in memory-constrained environments. PreMoe features two main components: probabilistic expert pruning (PEP) and task-adaptive expert retrieval (TAER). PEP employs a new metric, the task-conditioned expected selection score (TCESS), derived from router logits to quantify expert importance for specific tasks, thereby identifying a minimal set of critical experts. TAER leverages these task-specific expert importance profiles for efficient inference. It pre-computes and stores compact expert patterns for diverse tasks. When a user query is received, TAER rapidly identifies the most relevant stored task pattern and reconstructs the model by loading only the small subset of experts crucial for that task. This approach dramatically reduces the memory footprint across all deployment scenarios. DeepSeek-R1 671B maintains 97.2\% accuracy on MATH500 when pruned to 8/128 configuration (50\% expert reduction), and still achieves 72.0\% with aggressive 8/32 pruning (87.5\% expert reduction). Pangu-Ultra-MoE 718B achieves 97.15\% on MATH500 and 81.3\% on AIME24 with 8/128 pruning, while even more aggressive pruning to 4/64 (390GB memory) preserves 96.95\% accuracy on MATH500. We make our code publicly available at https://github.com/JarvisPei/PreMoe.
Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts
Apr 15, 2025
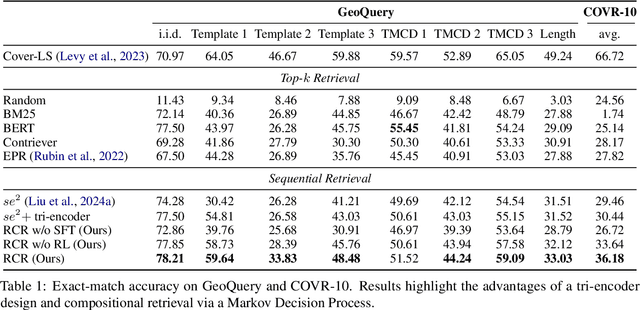
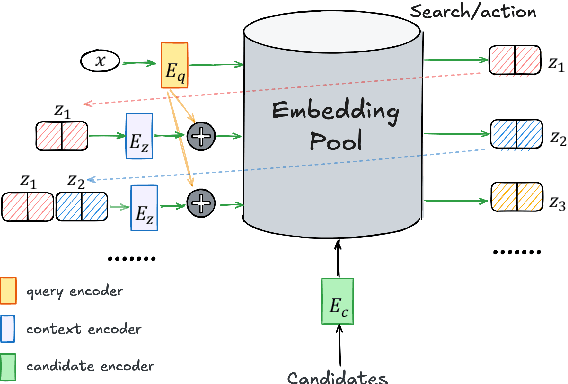
Large Language Models (LLMs) have demonstrated remarkable capabilities across numerous tasks, yet they often rely on external context to handle complex tasks. While retrieval-augmented frameworks traditionally focus on selecting top-ranked documents in a single pass, many real-world scenarios demand compositional retrieval, where multiple sources must be combined in a coordinated manner. In this work, we propose a tri-encoder sequential retriever that models this process as a Markov Decision Process (MDP), decomposing the probability of retrieving a set of elements into a sequence of conditional probabilities and allowing each retrieval step to be conditioned on previously selected examples. We train the retriever in two stages: first, we efficiently construct supervised sequential data for initial policy training; we then refine the policy to align with the LLM's preferences using a reward grounded in the structural correspondence of generated programs. Experimental results show that our method consistently and significantly outperforms baselines, underscoring the importance of explicitly modeling inter-example dependencies. These findings highlight the potential of compositional retrieval for tasks requiring multiple pieces of evidence or examples.
CMoE: Fast Carving of Mixture-of-Experts for Efficient LLM Inference
Feb 06, 2025



Large language models (LLMs) achieve impressive performance by scaling model parameters, but this comes with significant inference overhead. Feed-forward networks (FFNs), which dominate LLM parameters, exhibit high activation sparsity in hidden neurons. To exploit this, researchers have proposed using a mixture-of-experts (MoE) architecture, where only a subset of parameters is activated. However, existing approaches often require extensive training data and resources, limiting their practicality. We propose CMoE (Carved MoE), a novel framework to efficiently carve MoE models from dense models. CMoE achieves remarkable performance through efficient expert grouping and lightweight adaptation. First, neurons are grouped into shared and routed experts based on activation rates. Next, we construct a routing mechanism without training from scratch, incorporating a differentiable routing process and load balancing. Using modest data, CMoE produces a well-designed, usable MoE from a 7B dense model within five minutes. With lightweight fine-tuning, it achieves high-performance recovery in under an hour. We make our code publicly available at https://github.com/JarvisPei/CMoE.