 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink When Needed: Model-Aware Reasoning Routing for LLM-based Ranking
Jan 26, 2026Large language models (LLMs) are increasingly applied to ranking tasks in retrieval and recommendation. Although reasoning prompting can enhance ranking utility, our preliminary exploration reveals that its benefits are inconsistent and come at a substantial computational cost, suggesting that when to reason is as crucial as how to reason. To address this issue, we propose a reasoning routing framework that employs a lightweight, plug-and-play router head to decide whether to use direct inference (Non-Think) or reasoning (Think) for each instance before generation. The router head relies solely on pre-generation signals: i) compact ranking-aware features (e.g., candidate dispersion) and ii) model-aware difficulty signals derived from a diagnostic checklist reflecting the model's estimated need for reasoning. By leveraging these features before generation, the router outputs a controllable token that determines whether to apply the Think mode. Furthermore, the router can adaptively select its operating policy along the validation Pareto frontier during deployment, enabling dynamic allocation of computational resources toward instances most likely to benefit from Think under varying system constraints. Experiments on three public ranking datasets with different scales of open-source LLMs show consistent improvements in ranking utility with reduced token consumption (e.g., +6.3\% NDCG@10 with -49.5\% tokens on MovieLens with Qwen3-4B), demonstrating reasoning routing as a practical solution to the accuracy-efficiency trade-off.
DGH: Dynamic Gaussian Hair
Dec 18, 2025The creation of photorealistic dynamic hair remains a major challenge in digital human modeling because of the complex motions, occlusions, and light scattering. Existing methods often resort to static capture and physics-based models that do not scale as they require manual parameter fine-tuning to handle the diversity of hairstyles and motions, and heavy computation to obtain high-quality appearance. In this paper, we present Dynamic Gaussian Hair (DGH), a novel framework that efficiently learns hair dynamics and appearance. We propose: (1) a coarse-to-fine model that learns temporally coherent hair motion dynamics across diverse hairstyles; (2) a strand-guided optimization module that learns a dynamic 3D Gaussian representation for hair appearance with support for differentiable rendering, enabling gradient-based learning of view-consistent appearance under motion. Unlike prior simulation-based pipelines, our approach is fully data-driven, scales with training data, and generalizes across various hairstyles and head motion sequences. Additionally, DGH can be seamlessly integrated into a 3D Gaussian avatar framework, enabling realistic, animatable hair for high-fidelity avatar representation. DGH achieves promising geometry and appearance results, providing a scalable, data-driven alternative to physics-based simulation and rendering.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025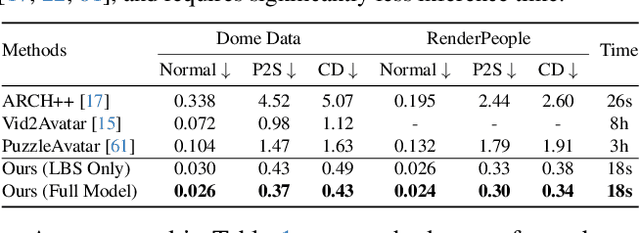
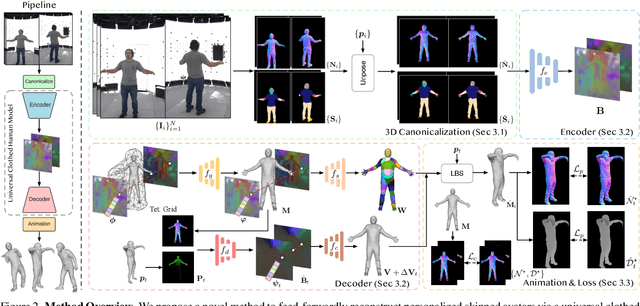
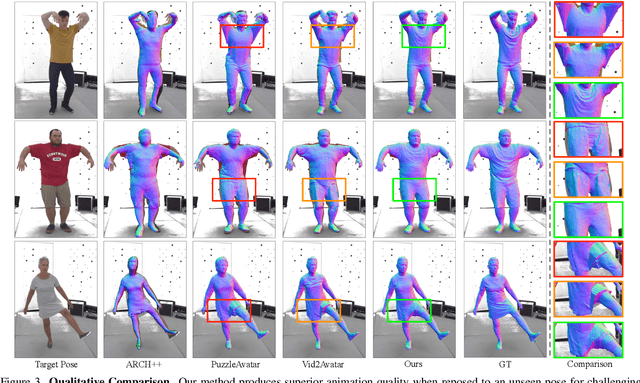
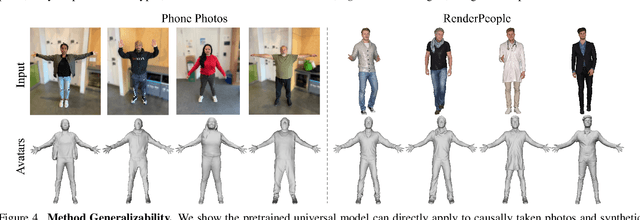
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 06, 2025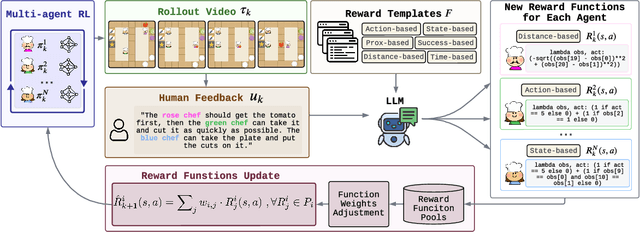
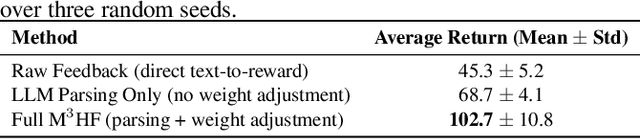
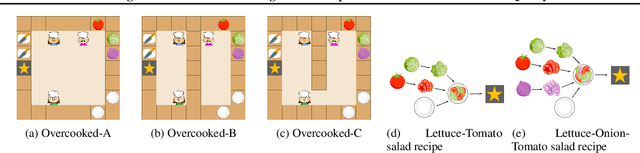
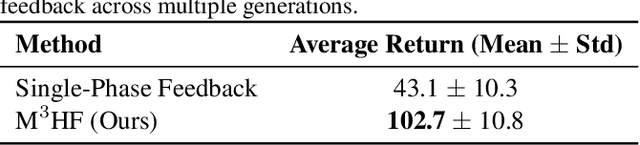
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
$\text{M}^3\text{HF}$: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 03, 2025Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality ($\text{M}^3\text{HF}$), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, $\text{M}^3\text{HF}$ leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that $\text{M}^3\text{HF}$ significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
Probe Pruning: Accelerating LLMs through Dynamic Pruning via Model-Probing
Feb 21, 2025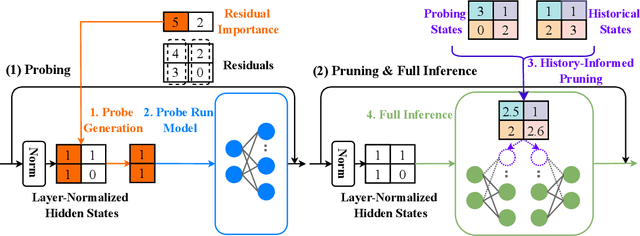


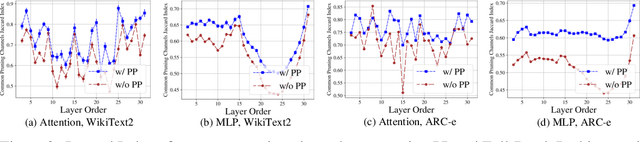
We introduce Probe Pruning (PP), a novel framework for online, dynamic, structured pruning of Large Language Models (LLMs) applied in a batch-wise manner. PP leverages the insight that not all samples and tokens contribute equally to the model's output, and probing a small portion of each batch effectively identifies crucial weights, enabling tailored dynamic pruning for different batches. It comprises three main stages: probing, history-informed pruning, and full inference. In the probing stage, PP selects a small yet crucial set of hidden states, based on residual importance, to run a few model layers ahead. During the history-informed pruning stage, PP strategically integrates the probing states with historical states. Subsequently, it structurally prunes weights based on the integrated states and the PP importance score, a metric developed specifically to assess the importance of each weight channel in maintaining performance. In the final stage, full inference is conducted on the remaining weights. A major advantage of PP is its compatibility with existing models, as it operates without requiring additional neural network modules or fine-tuning. Comprehensive evaluations of PP on LLaMA-2/3 and OPT models reveal that even minimal probing-using just 1.5% of FLOPs-can substantially enhance the efficiency of structured pruning of LLMs. For instance, when evaluated on LLaMA-2-7B with WikiText2, PP achieves a 2.56 times lower ratio of performance degradation per unit of runtime reduction compared to the state-of-the-art method at a 40% pruning ratio. Our code is available at https://github.com/Qi-Le1/Probe_Pruning.
PoGDiff: Product-of-Gaussians Diffusion Models for Imbalanced Text-to-Image Generation
Feb 12, 2025Diffusion models have made significant advancements in recent years. However, their performance often deteriorates when trained or fine-tuned on imbalanced datasets. This degradation is largely due to the disproportionate representation of majority and minority data in image-text pairs. In this paper, we propose a general fine-tuning approach, dubbed PoGDiff, to address this challenge. Rather than directly minimizing the KL divergence between the predicted and ground-truth distributions, PoGDiff replaces the ground-truth distribution with a Product of Gaussians (PoG), which is constructed by combining the original ground-truth targets with the predicted distribution conditioned on a neighboring text embedding. Experiments on real-world datasets demonstrate that our method effectively addresses the imbalance problem in diffusion models, improving both generation accuracy and quality.
Boolean Product Graph Neural Networks
Sep 21, 2024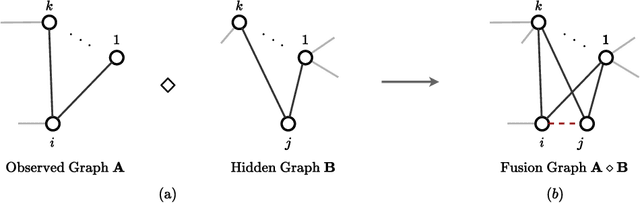
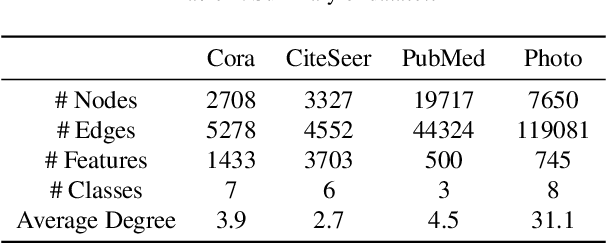
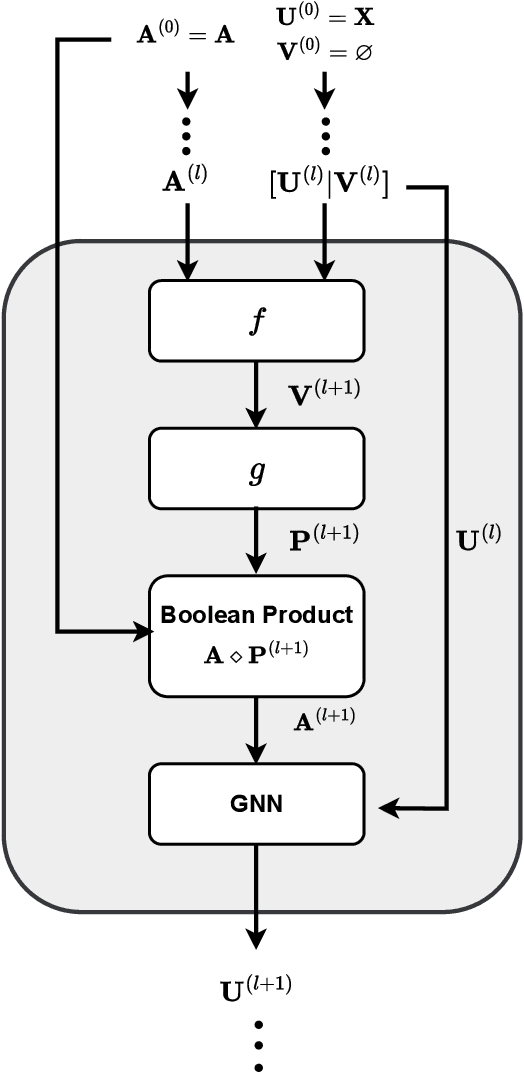
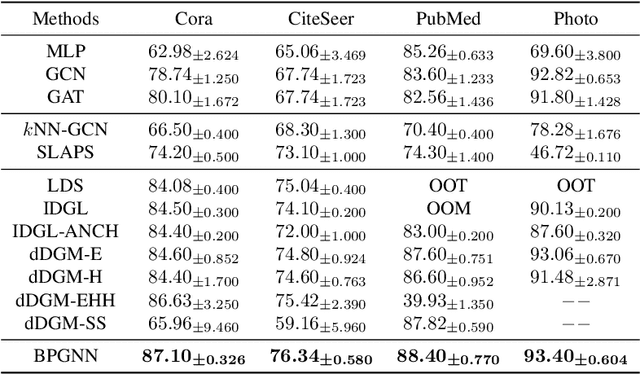
Graph Neural Networks (GNNs) have recently achieved significant success, with a key operation involving the aggregation of information from neighboring nodes. Substantial researchers have focused on defining neighbors for aggregation, predominantly based on observed adjacency matrices. However, in many scenarios, the explicitly given graphs contain noise, which can be amplified during the messages-passing process. Therefore, many researchers have turned their attention to latent graph inference, specifically learning a parametric graph. To mitigate fluctuations in latent graph structure learning, this paper proposes a novel Boolean product-based graph residual connection in GNNs to link the latent graph and the original graph. It computes the Boolean product between the latent graph and the original graph at each layer to correct the learning process. The Boolean product between two adjacency matrices is equivalent to triangle detection. Accordingly, the proposed Boolean product graph neural networks can be interpreted as discovering triangular cliques from the original and the latent graph. We validate the proposed method in benchmark datasets and demonstrate its ability to enhance the performance and robustness of GNNs.
Probability Passing for Graph Neural Networks: Graph Structure and Representations Joint Learning
Jul 15, 2024



Graph Neural Networks (GNNs) have achieved notable success in the analysis of non-Euclidean data across a wide range of domains. However, their applicability is constrained by the dependence on the observed graph structure. To solve this problem, Latent Graph Inference (LGI) is proposed to infer a task-specific latent structure by computing similarity or edge probability of node features and then apply a GNN to produce predictions. Even so, existing approaches neglect the noise from node features, which affects generated graph structure and performance. In this work, we introduce a novel method called Probability Passing to refine the generated graph structure by aggregating edge probabilities of neighboring nodes based on observed graph. Furthermore, we continue to utilize the LGI framework, inputting the refined graph structure and node features into GNNs to obtain predictions. We name the proposed scheme as Probability Passing-based Graph Neural Network (PPGNN). Moreover, the anchor-based technique is employed to reduce complexity and improve efficiency. Experimental results demonstrate the effectiveness of the proposed method.
ZeroDDI: A Zero-Shot Drug-Drug Interaction Event Prediction Method with Semantic Enhanced Learning and Dual-Modal Uniform Alignment
Jul 01, 2024



Drug-drug interactions (DDIs) can result in various pharmacological changes, which can be categorized into different classes known as DDI events (DDIEs). In recent years, previously unobserved/unseen DDIEs have been emerging, posing a new classification task when unseen classes have no labelled instances in the training stage, which is formulated as a zero-shot DDIE prediction (ZS-DDIE) task. However, existing computational methods are not directly applicable to ZS-DDIE, which has two primary challenges: obtaining suitable DDIE representations and handling the class imbalance issue. To overcome these challenges, we propose a novel method named ZeroDDI for the ZS-DDIE task. Specifically, we design a biological semantic enhanced DDIE representation learning module, which emphasizes the key biological semantics and distills discriminative molecular substructure-related semantics for DDIE representation learning. Furthermore, we propose a dual-modal uniform alignment strategy to distribute drug pair representations and DDIE semantic representations uniformly in a unit sphere and align the matched ones, which can mitigate the issue of class imbalance. Extensive experiments showed that ZeroDDI surpasses the baselines and indicate that it is a promising tool for detecting unseen DDIEs. Our code has been released in https://github.com/wzy-Sarah/ZeroDDI.