 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
RescueLens: LLM-Powered Triage and Action on Volunteer Feedback for Food Rescue
Nov 19, 2025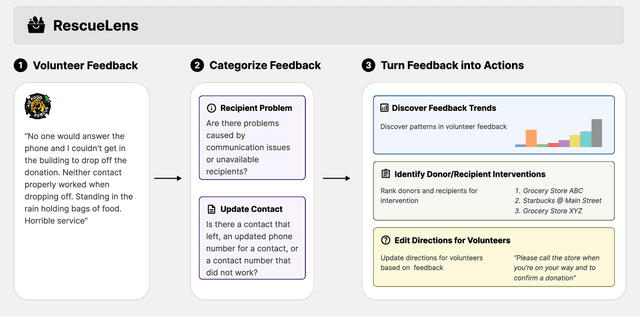
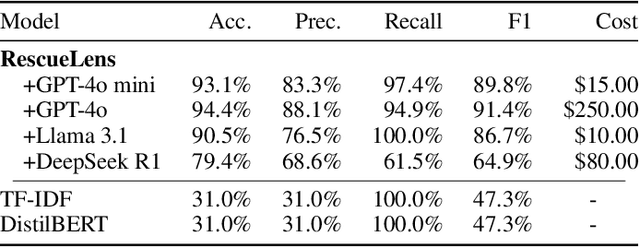
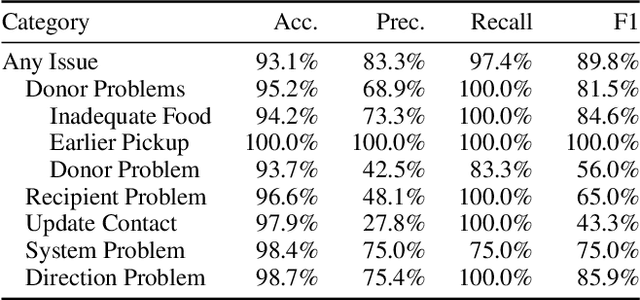
Food rescue organizations simultaneously tackle food insecurity and waste by working with volunteers to redistribute food from donors who have excess to recipients who need it. Volunteer feedback allows food rescue organizations to identify issues early and ensure volunteer satisfaction. However, food rescue organizations monitor feedback manually, which can be cumbersome and labor-intensive, making it difficult to prioritize which issues are most important. In this work, we investigate how large language models (LLMs) assist food rescue organizers in understanding and taking action based on volunteer experiences. We work with 412 Food Rescue, a large food rescue organization based in Pittsburgh, Pennsylvania, to design RescueLens, an LLM-powered tool that automatically categorizes volunteer feedback, suggests donors and recipients to follow up with, and updates volunteer directions based on feedback. We evaluate the performance of RescueLens on an annotated dataset, and show that it can recover 96% of volunteer issues at 71% precision. Moreover, by ranking donors and recipients according to their rates of volunteer issues, RescueLens allows organizers to focus on 0.5% of donors responsible for more than 30% of volunteer issues. RescueLens is now deployed at 412 Food Rescue and through semi-structured interviews with organizers, we find that RescueLens streamlines the feedback process so organizers better allocate their time.
Strategic Planning and Rationalizing on Trees Make LLMs Better Debaters
May 20, 2025Winning competitive debates requires sophisticated reasoning and argument skills. There are unique challenges in the competitive debate: (1) The time constraints force debaters to make strategic choices about which points to pursue rather than covering all possible arguments; (2) The persuasiveness of the debate relies on the back-and-forth interaction between arguments, which a single final game status cannot evaluate. To address these challenges, we propose TreeDebater, a novel debate framework that excels in competitive debate. We introduce two tree structures: the Rehearsal Tree and Debate Flow Tree. The Rehearsal Tree anticipates the attack and defenses to evaluate the strength of the claim, while the Debate Flow Tree tracks the debate status to identify the active actions. TreeDebater allocates its time budget among candidate actions and uses the speech time controller and feedback from the simulated audience to revise its statement. The human evaluation on both the stage-level and the debate-level comparison shows that our TreeDebater outperforms the state-of-the-art multi-agent debate system. Further investigation shows that TreeDebater shows better strategies in limiting time to important debate actions, aligning with the strategies of human debate experts.
GenTorrent: Scaling Large Language Model Serving with An Overley Network
Apr 30, 2025While significant progress has been made in research and development on open-source and cost-efficient large-language models (LLMs), serving scalability remains a critical challenge, particularly for small organizations and individuals seeking to deploy and test their LLM innovations. Inspired by peer-to-peer networks that leverage decentralized overlay nodes to increase throughput and availability, we propose GenTorrent, an LLM serving overlay that harnesses computing resources from decentralized contributors. We identify four key research problems inherent to enabling such a decentralized infrastructure: 1) overlay network organization; 2) LLM communication privacy; 3) overlay forwarding for resource efficiency; and 4) verification of serving quality. This work presents the first systematic study of these fundamental problems in the context of decentralized LLM serving. Evaluation results from a prototype implemented on a set of decentralized nodes demonstrate that GenTorrent achieves a latency reduction of over 50% compared to the baseline design without overlay forwarding. Furthermore, the security features introduce minimal overhead to serving latency and throughput. We believe this work pioneers a new direction for democratizing and scaling future AI serving capabilities.
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Apr 18, 2025Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing reasoning capabilities in large language models, but faces a fundamental asymmetry in computation and memory requirements: inference is embarrassingly parallel with a minimal memory footprint, while policy updates require extensive synchronization and are memory-intensive. To address this asymmetry, we introduce PODS (Policy Optimization with Down-Sampling), a framework that strategically decouples these phases by generating numerous rollouts in parallel but updating only on an informative subset. Within this framework, we develop max-variance down-sampling, a theoretically motivated method that selects rollouts with maximally diverse reward signals. We prove that this approach has an efficient algorithmic solution, and empirically demonstrate that GRPO with PODS using max-variance down-sampling achieves superior performance over standard GRPO on the GSM8K benchmark.
REALM: A Dataset of Real-World LLM Use Cases
Mar 24, 2025Large Language Models, such as the GPT series, have driven significant industrial applications, leading to economic and societal transformations. However, a comprehensive understanding of their real-world applications remains limited. To address this, we introduce REALM, a dataset of over 94,000 LLM use cases collected from Reddit and news articles. REALM captures two key dimensions: the diverse applications of LLMs and the demographics of their users. It categorizes LLM applications and explores how users' occupations relate to the types of applications they use. By integrating real-world data, REALM offers insights into LLM adoption across different domains, providing a foundation for future research on their evolving societal roles. A dedicated dashboard https://realm-e7682.web.app/ presents the data.
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 06, 2025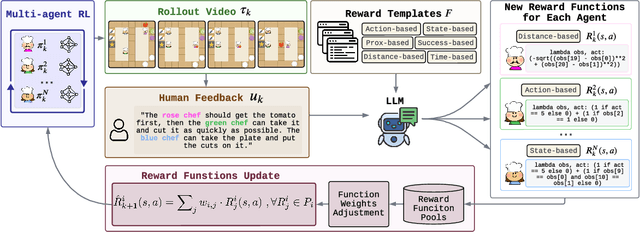
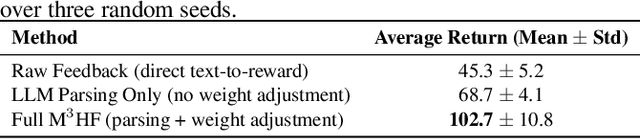
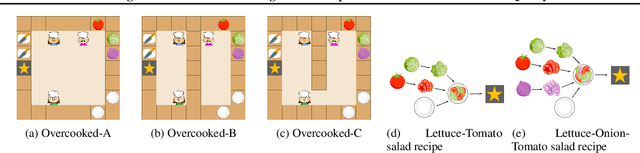
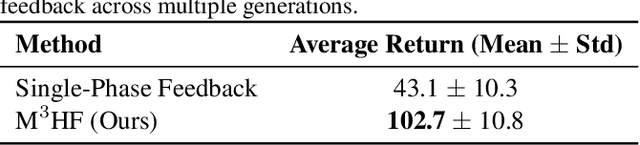
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
$\text{M}^3\text{HF}$: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 03, 2025Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality ($\text{M}^3\text{HF}$), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, $\text{M}^3\text{HF}$ leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that $\text{M}^3\text{HF}$ significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
Grounded Persuasive Language Generation for Automated Marketing
Feb 24, 2025



This paper develops an agentic framework that employs large language models (LLMs) to automate the generation of persuasive and grounded marketing content, using real estate listing descriptions as our focal application domain. Our method is designed to align the generated content with user preferences while highlighting useful factual attributes. This agent consists of three key modules: (1) Grounding Module, mimicking expert human behavior to predict marketable features; (2) Personalization Module, aligning content with user preferences; (3) Marketing Module, ensuring factual accuracy and the inclusion of localized features. We conduct systematic human-subject experiments in the domain of real estate marketing, with a focus group of potential house buyers. The results demonstrate that marketing descriptions generated by our approach are preferred over those written by human experts by a clear margin. Our findings suggest a promising LLM-based agentic framework to automate large-scale targeted marketing while ensuring responsible generation using only facts.
Cooperative Strategic Planning Enhances Reasoning Capabilities in Large Language Models
Oct 25, 2024



Enhancing the reasoning capabilities of large language models (LLMs) is crucial for enabling them to tackle complex, multi-step problems. Multi-agent frameworks have shown great potential in enhancing LLMs' reasoning capabilities. However, the lack of effective cooperation between LLM agents hinders their performance, especially for multi-step reasoning tasks. This paper proposes a novel cooperative multi-agent reasoning framework (CoPlanner) by separating reasoning steps and assigning distinct duties to different agents. CoPlanner consists of two LLM agents: a planning agent and a reasoning agent. The planning agent provides high-level strategic hints, while the reasoning agent follows these hints and infers answers. By training the planning agent's policy through the interactive reasoning process via Proximal Policy Optimization (PPO), the LLaMA-3-8B-based CoPlanner outperforms the previous best method by 9.94\% on LogiQA and 3.09\% on BBH. Our results demonstrate that the guidance from the planning agent and the effective cooperation between the agents contribute to the superior performance of CoPlanner in tackling multi-step reasoning problems.