 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025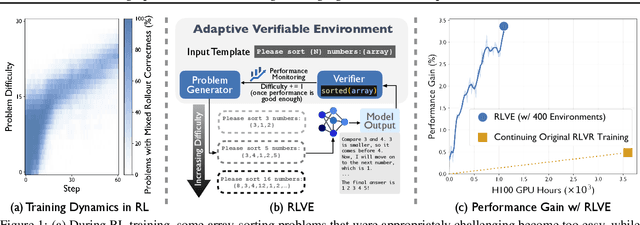

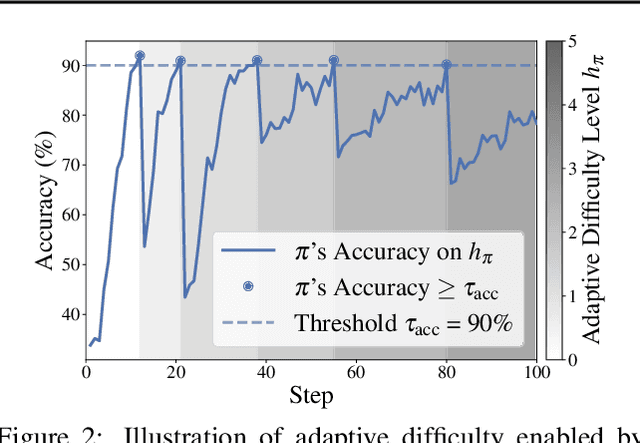
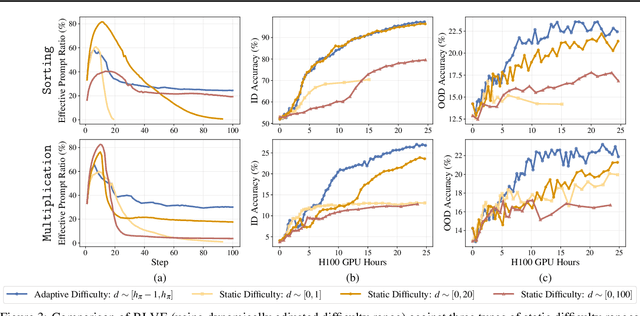
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Strategic Planning and Rationalizing on Trees Make LLMs Better Debaters
May 20, 2025Winning competitive debates requires sophisticated reasoning and argument skills. There are unique challenges in the competitive debate: (1) The time constraints force debaters to make strategic choices about which points to pursue rather than covering all possible arguments; (2) The persuasiveness of the debate relies on the back-and-forth interaction between arguments, which a single final game status cannot evaluate. To address these challenges, we propose TreeDebater, a novel debate framework that excels in competitive debate. We introduce two tree structures: the Rehearsal Tree and Debate Flow Tree. The Rehearsal Tree anticipates the attack and defenses to evaluate the strength of the claim, while the Debate Flow Tree tracks the debate status to identify the active actions. TreeDebater allocates its time budget among candidate actions and uses the speech time controller and feedback from the simulated audience to revise its statement. The human evaluation on both the stage-level and the debate-level comparison shows that our TreeDebater outperforms the state-of-the-art multi-agent debate system. Further investigation shows that TreeDebater shows better strategies in limiting time to important debate actions, aligning with the strategies of human debate experts.
Sing it, Narrate it: Quality Musical Lyrics Translation
Oct 29, 2024



Translating lyrics for musicals presents unique challenges due to the need to ensure high translation quality while adhering to singability requirements such as length and rhyme. Existing song translation approaches often prioritize these singability constraints at the expense of translation quality, which is crucial for musicals. This paper aims to enhance translation quality while maintaining key singability features. Our method consists of three main components. First, we create a dataset to train reward models for the automatic evaluation of translation quality. Second, to enhance both singability and translation quality, we implement a two-stage training process with filtering techniques. Finally, we introduce an inference-time optimization framework for translating entire songs. Extensive experiments, including both automatic and human evaluations, demonstrate significant improvements over baseline methods and validate the effectiveness of each component in our approach.
Cooperative Strategic Planning Enhances Reasoning Capabilities in Large Language Models
Oct 25, 2024



Enhancing the reasoning capabilities of large language models (LLMs) is crucial for enabling them to tackle complex, multi-step problems. Multi-agent frameworks have shown great potential in enhancing LLMs' reasoning capabilities. However, the lack of effective cooperation between LLM agents hinders their performance, especially for multi-step reasoning tasks. This paper proposes a novel cooperative multi-agent reasoning framework (CoPlanner) by separating reasoning steps and assigning distinct duties to different agents. CoPlanner consists of two LLM agents: a planning agent and a reasoning agent. The planning agent provides high-level strategic hints, while the reasoning agent follows these hints and infers answers. By training the planning agent's policy through the interactive reasoning process via Proximal Policy Optimization (PPO), the LLaMA-3-8B-based CoPlanner outperforms the previous best method by 9.94\% on LogiQA and 3.09\% on BBH. Our results demonstrate that the guidance from the planning agent and the effective cooperation between the agents contribute to the superior performance of CoPlanner in tackling multi-step reasoning problems.
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Jul 22, 2024



Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Semantic Complete Scene Forecasting from a 4D Dynamic Point Cloud Sequence
Dec 15, 2023



We study a new problem of semantic complete scene forecasting (SCSF) in this work. Given a 4D dynamic point cloud sequence, our goal is to forecast the complete scene corresponding to the future next frame along with its semantic labels. To tackle this challenging problem, we properly model the synergetic relationship between future forecasting and semantic scene completion through a novel network named SCSFNet. SCSFNet leverages a hybrid geometric representation for high-resolution complete scene forecasting. To leverage multi-frame observation as well as the understanding of scene dynamics to ease the completion task, SCSFNet introduces an attention-based skip connection scheme. To ease the need to model occlusion variations and to better focus on the occluded part, SCSFNet utilizes auxiliary visibility grids to guide the forecasting task. To evaluate the effectiveness of SCSFNet, we conduct experiments on various benchmarks including two large-scale indoor benchmarks we contributed and the outdoor SemanticKITTI benchmark. Extensive experiments show SCSFNet outperforms baseline methods on multiple metrics by a large margin, and also prove the synergy between future forecasting and semantic scene completion.
Autonomous Tree-search Ability of Large Language Models
Oct 14, 2023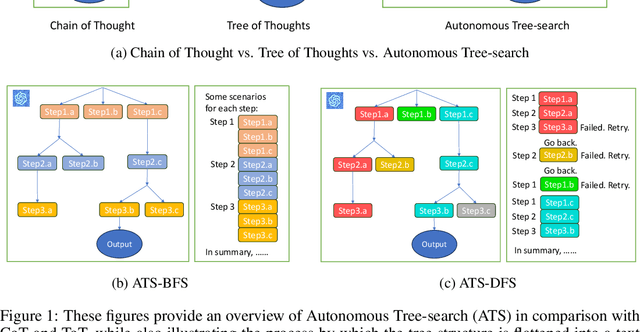
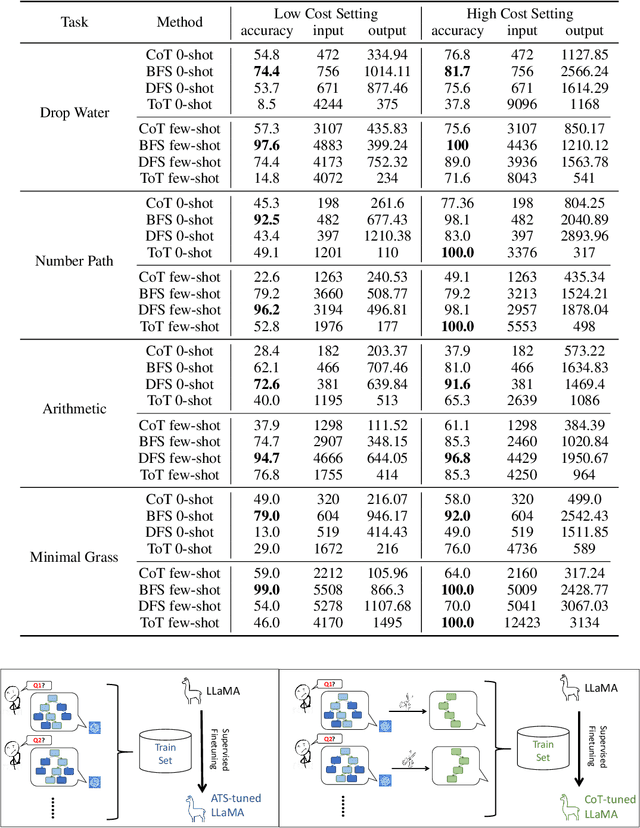
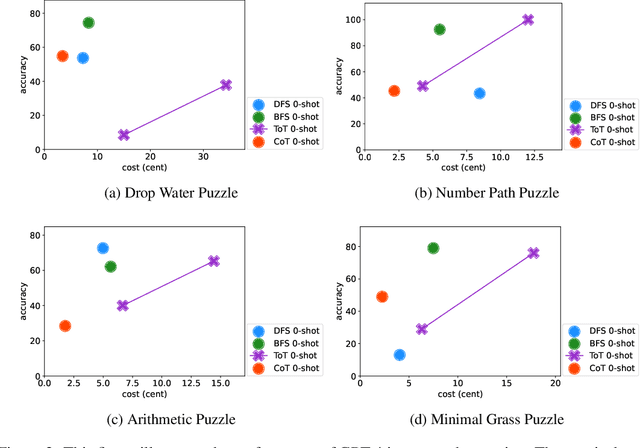
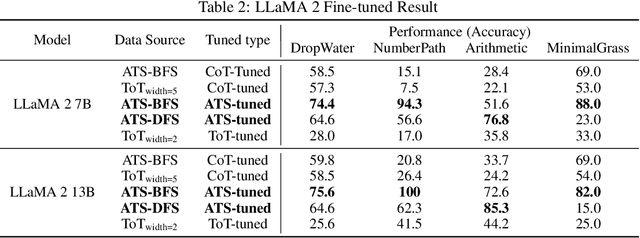
Large Language Models have excelled in remarkable reasoning capabilities with advanced prompting techniques, but they fall short on tasks that require exploration, strategic foresight, and sequential decision-making. Recent works propose to utilize external programs to define search logic, such that LLMs can perform passive tree search to solve more challenging reasoning tasks. Though impressive results have been achieved, there are several fundamental limitations of these approaches. First, passive tree searches are not efficient as they usually require multiple rounds of LLM API calls to solve one single problem. Moreover, passive search methods are not flexible since they need task-specific program designs. Then a natural question arises: can we maintain the tree-search capability of LLMs without the aid of external programs, and can still generate responses that clearly demonstrate the process of a tree-structure search? To this end, we propose a new concept called autonomous tree-search ability of LLM, which can automatically generate a response containing search trajectories for the correct answer. Concretely, we perform search trajectories using capable LLM API via a fixed system prompt, allowing them to perform autonomous tree-search (ATS) right out of the box. Experiments on 4 puzzle games demonstrate our method can achieve huge improvements. The ATS-BFS method outperforms the Chain of Thought approach by achieving an average accuracy improvement of 33%. Compared to Tree of Thoughts, it requires 65.6% or 47.7% less GPT-api cost to attain a comparable level of accuracy. Moreover, we have collected data using the ATS prompt method and fine-tuned LLaMA. This approach yield a greater improvement compared to the ones fine-tuned on CoT data. Specifically, it outperforms CoT-tuned LLaMAs by an average of 40.6% and 38.5% for LLaMA2-7B and LLaMA2-13B, respectively.