 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetacognition as Reward: Reinforcing LLM Reasoning via Knowledge and Regulation Signals
May 22, 2026Recent RL methods have substantially improved the reasoning abilities of LLMs. Existing reward designs mainly follow two paradigms: (1) Reinforcement learning with verifiable rewards (RLVR) derives outcome signals from executable checks or ground-truth answers, but provides limited guidance for intermediate reasoning behaviors. (2) Rubrics-as-reward (RaR) goes beyond final-answer checking by using natural-language rubrics to assess reasoning quality and task compliance, but often requires instance-specific rubrics and substantial design effort. To address these issues, we introduce Metacognition-as-Reward (MaR), a metacognition-inspired RL framework that guides LLM reasoning through two general process dimensions: i) metacognitive knowledge, which identifies task-relevant information without hand-crafted instance-specific rubrics, and ii) metacognitive regulation, which plans and adjusts the reasoning process to provide reward guidance beyond final-answer outcomes. MaR scaffolds model rollouts into explicit metacognitive components and optimizes them with a trajectory-level reward over task knowledge coverage, regulation fidelity, and final-answer correctness. In this way, MaR extends reward feedback to reasoning trajectories while grounding the reward signals in general metacognitive dimensions. Experiments on 22 benchmarks show that MaR consistently improves model performance, achieving up to a 7.7% gain over the base model and up to an 11.0% gain over vanilla DAPO. Notably, Qwen3.5-9B + MaR narrows the gap to frontier models, surpassing GPT-OSS-120B on overall average and outperforming stronger models on several individual benchmarks. Process-level analysis further shows substantial improvements in reasoning process quality. MaR also generalizes to out-of-domain datasets, where MaR-trained models improve over their corresponding base models on average.
AnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
Apr 21, 2026Sparse-view 3D reconstruction is essential for modeling scenes from casual captures, but remain challenging for non-generative reconstruction. Existing diffusion-based approaches mitigates this issues by synthesizing novel views, but they often condition on only one or two capture frames, which restricts geometric consistency and limits scalability to large or diverse scenes. We propose AnyRecon, a scalable framework for reconstruction from arbitrary and unordered sparse inputs that preserves explicit geometric control while supporting flexible conditioning cardinality. To support long-range conditioning, our method constructs a persistent global scene memory via a prepended capture view cache, and removes temporal compression to maintain frame-level correspondence under large viewpoint changes. Beyond better generative model, we also find that the interplay between generation and reconstruction is crucial for large-scale 3D scenes. Thus, we introduce a geometry-aware conditioning strategy that couples generation and reconstruction through an explicit 3D geometric memory and geometry-driven capture-view retrieval. To ensure efficiency, we combine 4-step diffusion distillation with context-window sparse attention to reduce quadratic complexity. Extensive experiments demonstrate robust and scalable reconstruction across irregular inputs, large viewpoint gaps, and long trajectories.
HiVLA: A Visual-Grounded-Centric Hierarchical Embodied Manipulation System
Apr 15, 2026While end-to-end Vision-Language-Action (VLA) models offer a promising paradigm for robotic manipulation, fine-tuning them on narrow control data often compromises the profound reasoning capabilities inherited from their base Vision-Language Models (VLMs). To resolve this fundamental trade-off, we propose HiVLA, a visual-grounded-centric hierarchical framework that explicitly decouples high-level semantic planning from low-level motor control. In high-level part, a VLM planner first performs task decomposition and visual grounding to generate structured plans, comprising a subtask instruction and a precise target bounding box. Then, to translate this plan into physical actions, we introduce a flow-matching Diffusion Transformer (DiT) action expert in low-level part equipped with a novel cascaded cross-attention mechanism. This design sequentially fuses global context, high-resolution object-centric crops and skill semantics, enabling the DiT to focus purely on robust execution. Our decoupled architecture preserves the VLM's zero-shot reasoning while allowing independent improvement of both components. Extensive experiments in simulation and the real world demonstrate that HiVLA significantly outperforms state-of-the-art end-to-end baselines, particularly excelling in long-horizon skill composition and the fine-grained manipulation of small objects in cluttered scenes.
ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
Mar 26, 2026Multi-shot video generation is crucial for long narrative storytelling, yet current bidirectional architectures suffer from limited interactivity and high latency. We propose ShotStream, a novel causal multi-shot architecture that enables interactive storytelling and efficient on-the-fly frame generation. By reformulating the task as next-shot generation conditioned on historical context, ShotStream allows users to dynamically instruct ongoing narratives via streaming prompts. We achieve this by first fine-tuning a text-to-video model into a bidirectional next-shot generator, which is then distilled into a causal student via Distribution Matching Distillation. To overcome the challenges of inter-shot consistency and error accumulation inherent in autoregressive generation, we introduce two key innovations. First, a dual-cache memory mechanism preserves visual coherence: a global context cache retains conditional frames for inter-shot consistency, while a local context cache holds generated frames within the current shot for intra-shot consistency. And a RoPE discontinuity indicator is employed to explicitly distinguish the two caches to eliminate ambiguity. Second, to mitigate error accumulation, we propose a two-stage distillation strategy. This begins with intra-shot self-forcing conditioned on ground-truth historical shots and progressively extends to inter-shot self-forcing using self-generated histories, effectively bridging the train-test gap. Extensive experiments demonstrate that ShotStream generates coherent multi-shot videos with sub-second latency, achieving 16 FPS on a single GPU. It matches or exceeds the quality of slower bidirectional models, paving the way for real-time interactive storytelling. Training and inference code, as well as the models, are available on our
Attention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers
Nov 18, 2025We propose Confidence-Guided Token Merging (Co-Me), an acceleration mechanism for visual geometric transformers without retraining or finetuning the base model. Co-Me distilled a light-weight confidence predictor to rank tokens by uncertainty and selectively merge low-confidence ones, effectively reducing computation while maintaining spatial coverage. Compared to similarity-based merging or pruning, the confidence signal in Co-Me reliably indicates regions emphasized by the transformer, enabling substantial acceleration without degrading performance. Co-Me applies seamlessly to various multi-view and streaming visual geometric transformers, achieving speedups that scale with sequence length. When applied to VGGT and MapAnything, Co-Me achieves up to $11.3\times$ and $7.2\times$ speedup, making visual geometric transformers practical for real-time 3D perception and reconstruction.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Virtual Community: An Open World for Humans, Robots, and Society
Aug 20, 2025

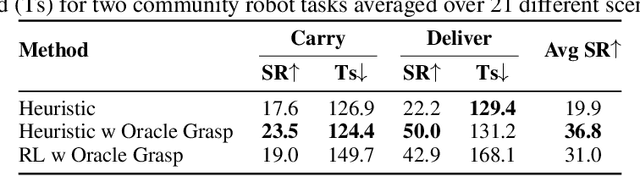

The rapid progress in AI and Robotics may lead to a profound societal transformation, as humans and robots begin to coexist within shared communities, introducing both opportunities and challenges. To explore this future, we present Virtual Community-an open-world platform for humans, robots, and society-built on a universal physics engine and grounded in real-world 3D scenes. With Virtual Community, we aim to study embodied social intelligence at scale: 1) How robots can intelligently cooperate or compete; 2) How humans develop social relations and build community; 3) More importantly, how intelligent robots and humans can co-exist in an open world. To support these, Virtual Community features: 1) An open-source multi-agent physics simulator that supports robots, humans, and their interactions within a society; 2) A large-scale, real-world aligned community generation pipeline, including vast outdoor space, diverse indoor scenes, and a community of grounded agents with rich characters and appearances. Leveraging Virtual Community, we propose two novel challenges. The Community Planning Challenge evaluates multi-agent reasoning and planning ability in open-world settings, such as cooperating to help agents with daily activities and efficiently connecting other agents. The Community Robot Challenge requires multiple heterogeneous robots to collaborate in solving complex open-world tasks. We evaluate various baselines on these tasks and demonstrate the challenges in both high-level open-world task planning and low-level cooperation controls. We hope that Virtual Community will unlock further study of human-robot coexistence within open-world environments.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.