 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Regressive Masked Diffusion Models
Jan 23, 2026Masked diffusion models (MDMs) have emerged as a promising approach for language modeling, yet they face a performance gap compared to autoregressive models (ARMs) and require more training iterations. In this work, we present the Auto-Regressive Masked Diffusion (ARMD) model, an architecture designed to close this gap by unifying the training efficiency of autoregressive models with the parallel generation capabilities of diffusion-based models. Our key insight is to reframe the masked diffusion process as a block-wise causal model. This perspective allows us to design a strictly causal, permutation-equivariant architecture that computes all conditional probabilities across multiple denoising steps in a single, parallel forward pass. The resulting architecture supports efficient, autoregressive-style decoding and a progressive permutation training scheme, allowing the model to learn both canonical left-to-right and random token orderings. Leveraging this flexibility, we introduce a novel strided parallel generation strategy that accelerates inference by generating tokens in parallel streams while maintaining global coherence. Empirical results demonstrate that ARMD achieves state-of-the-art performance on standard language modeling benchmarks, outperforming established diffusion baselines while requiring significantly fewer training steps. Furthermore, it establishes a new benchmark for parallel text generation, effectively bridging the performance gap between parallel and sequential decoding.
Trellis: Learning to Compress Key-Value Memory in Attention Models
Dec 29, 2025Transformers, while powerful, suffer from quadratic computational complexity and the ever-growing Key-Value (KV) cache of the attention mechanism. This paper introduces Trellis, a novel Transformer architecture with bounded memory that learns how to compress its key-value memory dynamically at test time. Trellis replaces the standard KV cache with a fixed-size memory and train a two-pass recurrent compression mechanism to store new keys and values into memory. To achieve this, it leverages an online gradient descent procedure with a forget gate, enabling the compressed memory to be updated recursively while learning to retain important contextual information from incoming tokens at test time. Extensive experiments on language modeling, common-sense reasoning, recall-intensive tasks, and time series show that the proposed architecture outperforms strong baselines. Notably, its performance gains increase as the sequence length grows, highlighting its potential for long-context applications.
MS-SSM: A Multi-Scale State Space Model for Efficient Sequence Modeling
Dec 29, 2025State-space models (SSMs) have recently attention as an efficient alternative to computationally expensive attention-based models for sequence modeling. They rely on linear recurrences to integrate information over time, enabling fast inference, parallelizable training, and control over recurrence stability. However, traditional SSMs often suffer from limited effective memory, requiring larger state sizes for improved recall. Moreover, existing SSMs struggle to capture multi-scale dependencies, which are essential for modeling complex structures in time series, images, and natural language. This paper introduces a multi-scale SSM framework that addresses these limitations by representing sequence dynamics across multiple resolution and processing each resolution with specialized state-space dynamics. By capturing both fine-grained, high-frequency patterns and coarse, global trends, MS-SSM enhances memory efficiency and long-range modeling. We further introduce an input-dependent scale-mixer, enabling dynamic information fusion across resolutions. The proposed approach significantly improves sequence modeling, particularly in long-range and hierarchical tasks, while maintaining computational efficiency. Extensive experiments on benchmarks, including Long Range Arena, hierarchical reasoning, time series classification, and image recognition, demonstrate that MS-SSM consistently outperforms prior SSM-based models, highlighting the benefits of multi-resolution processing in state-space architectures.
TNT: Improving Chunkwise Training for Test-Time Memorization
Nov 10, 2025Recurrent neural networks (RNNs) with deep test-time memorization modules, such as Titans and TTT, represent a promising, linearly-scaling paradigm distinct from Transformers. While these expressive models do not yet match the peak performance of state-of-the-art Transformers, their potential has been largely untapped due to prohibitively slow training and low hardware utilization. Existing parallelization methods force a fundamental conflict governed by the chunksize hyperparameter: large chunks boost speed but degrade performance, necessitating a fixed, suboptimal compromise. To solve this challenge, we introduce TNT, a novel training paradigm that decouples training efficiency from inference performance through a two-stage process. Stage one is an efficiency-focused pre-training phase utilizing a hierarchical memory. A global module processes large, hardware-friendly chunks for long-range context, while multiple parallel local modules handle fine-grained details. Crucially, by periodically resetting local memory states, we break sequential dependencies to enable massive context parallelization. Stage two is a brief fine-tuning phase where only the local memory modules are adapted to a smaller, high-resolution chunksize, maximizing accuracy with minimal overhead. Evaluated on Titans and TTT models, TNT achieves a substantial acceleration in training speed-up to 17 times faster than the most accurate baseline configuration - while simultaneously improving model accuracy. This improvement removes a critical scalability barrier, establishing a practical foundation for developing expressive RNNs and facilitating future work to close the performance gap with Transformers.
Lattice: Learning to Efficiently Compress the Memory
Apr 08, 2025Attention mechanisms have revolutionized sequence learning but suffer from quadratic computational complexity. This paper introduces Lattice, a novel recurrent neural network (RNN) mechanism that leverages the inherent low-rank structure of K-V matrices to efficiently compress the cache into a fixed number of memory slots, achieving sub-quadratic complexity. We formulate this compression as an online optimization problem and derive a dynamic memory update rule based on a single gradient descent step. The resulting recurrence features a state- and input-dependent gating mechanism, offering an interpretable memory update process. The core innovation is the orthogonal update: each memory slot is updated exclusively with information orthogonal to its current state hence incorporation of only novel, non-redundant data, which minimizes the interference with previously stored information. The experimental results show that Lattice achieves the best perplexity compared to all baselines across diverse context lengths, with performance improvement becoming more pronounced as the context length increases.
TRecViT: A Recurrent Video Transformer
Dec 18, 2024We propose a novel block for video modelling. It relies on a time-space-channel factorisation with dedicated blocks for each dimension: gated linear recurrent units (LRUs) perform information mixing over time, self-attention layers perform mixing over space, and MLPs over channels. The resulting architecture TRecViT performs well on sparse and dense tasks, trained in supervised or self-supervised regimes. Notably, our model is causal and outperforms or is on par with a pure attention model ViViT-L on large scale video datasets (SSv2, Kinetics400), while having $3\times$ less parameters, $12\times$ smaller memory footprint, and $5\times$ lower FLOPs count. Code and checkpoints will be made available online at https://github.com/google-deepmind/trecvit.
Best of Both Worlds: Advantages of Hybrid Graph Sequence Models
Nov 23, 2024Modern sequence models (e.g., Transformers, linear RNNs, etc.) emerged as dominant backbones of recent deep learning frameworks, mainly due to their efficiency, representational power, and/or ability to capture long-range dependencies. Adopting these sequence models for graph-structured data has recently gained popularity as the alternative to Message Passing Neural Networks (MPNNs). There is, however, a lack of a common foundation about what constitutes a good graph sequence model, and a mathematical description of the benefits and deficiencies in adopting different sequence models for learning on graphs. To this end, we first present Graph Sequence Model (GSM), a unifying framework for adopting sequence models for graphs, consisting of three main steps: (1) Tokenization, which translates the graph into a set of sequences; (2) Local Encoding, which encodes local neighborhoods around each node; and (3) Global Encoding, which employs a scalable sequence model to capture long-range dependencies within the sequences. This framework allows us to understand, evaluate, and compare the power of different sequence model backbones in graph tasks. Our theoretical evaluations of the representation power of Transformers and modern recurrent models through the lens of global and local graph tasks show that there are both negative and positive sides for both types of models. Building on this observation, we present GSM++, a fast hybrid model that uses the Hierarchical Affinity Clustering (HAC) algorithm to tokenize the graph into hierarchical sequences, and then employs a hybrid architecture of Transformer to encode these sequences. Our theoretical and experimental results support the design of GSM++, showing that GSM++ outperforms baselines in most benchmark evaluations.
Orchid: Flexible and Data-Dependent Convolution for Sequence Modeling
Feb 28, 2024

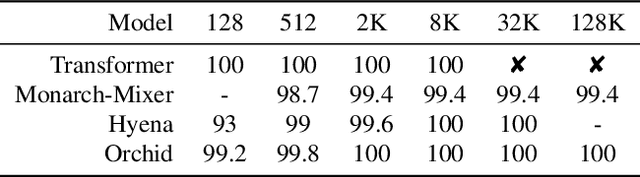

In the rapidly evolving landscape of deep learning, the quest for models that balance expressivity with computational efficiency has never been more critical. This paper introduces Orchid, a novel architecture that reimagines sequence modeling by incorporating a new data-dependent convolution mechanism. Orchid is designed to address the inherent limitations of traditional attention mechanisms, particularly their quadratic complexity, without compromising the ability to capture long-range dependencies and in-context learning. At the core of Orchid lies the data-dependent convolution layer, which dynamically adjusts its kernel conditioned on input data using a dedicated conditioning neural network. We design two simple conditioning networks that maintain shift equivariance in the adaptive convolution operation. The dynamic nature of data-dependent convolution kernel, coupled with gating operations, grants Orchid high expressivity while maintaining efficiency and quasilinear scalability for long sequences. We rigorously evaluate Orchid across multiple domains, including language modeling and image classification, to showcase its performance and generality. Our experiments demonstrate that Orchid architecture not only outperforms traditional attention-based architectures such as BERT and Vision Transformers with smaller model sizes, but also extends the feasible sequence length beyond the limitations of the dense attention layers. This achievement represents a significant step towards more efficient and scalable deep learning models for sequence modeling.
HiGen: Hierarchical Graph Generative Networks
May 30, 2023Most real-world graphs exhibit a hierarchical structure, which is often overlooked by existing graph generation methods. To address this limitation, we propose a novel graph generative network that captures the hierarchical nature of graphs and successively generates the graph sub-structures in a coarse-to-fine fashion. At each level of hierarchy, this model generates communities in parallel, followed by the prediction of cross-edges between communities using a separate model. This modular approach results in a highly scalable graph generative network. Moreover, we model the output distribution of edges in the hierarchical graph with a multinomial distribution and derive a recursive factorization for this distribution, enabling us to generate sub-graphs with integer-valued edge weights in an autoregressive approach. Empirical studies demonstrate that the proposed generative model can effectively capture both local and global properties of graphs and achieves state-of-the-art performance in terms of graph quality on various benchmarks.
HiGeN: Hierarchical Multi-Resolution Graph Generative Networks
Mar 06, 2023



In real world domains, most graphs naturally exhibit a hierarchical structure. However, data-driven graph generation is yet to effectively capture such structures. To address this, we propose a novel approach that recursively generates community structures at multiple resolutions, with the generated structures conforming to training data distribution at each level of the hierarchy. The graphs generation is designed as a sequence of coarse-to-fine generative models allowing for parallel generation of all sub-structures, resulting in a high degree of scalability. Furthermore, we model the output distribution of edges with a more expressive multinomial distribution and derive a recursive factorization for this distribution, making it a suitable choice for graph generative models. This allows for the generation of graphs with integer-valued edge weights. Our method achieves state-of-the-art performance in both accuracy and efficiency on multiple datasets.