 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Regressive Masked Diffusion Models
Jan 23, 2026Masked diffusion models (MDMs) have emerged as a promising approach for language modeling, yet they face a performance gap compared to autoregressive models (ARMs) and require more training iterations. In this work, we present the Auto-Regressive Masked Diffusion (ARMD) model, an architecture designed to close this gap by unifying the training efficiency of autoregressive models with the parallel generation capabilities of diffusion-based models. Our key insight is to reframe the masked diffusion process as a block-wise causal model. This perspective allows us to design a strictly causal, permutation-equivariant architecture that computes all conditional probabilities across multiple denoising steps in a single, parallel forward pass. The resulting architecture supports efficient, autoregressive-style decoding and a progressive permutation training scheme, allowing the model to learn both canonical left-to-right and random token orderings. Leveraging this flexibility, we introduce a novel strided parallel generation strategy that accelerates inference by generating tokens in parallel streams while maintaining global coherence. Empirical results demonstrate that ARMD achieves state-of-the-art performance on standard language modeling benchmarks, outperforming established diffusion baselines while requiring significantly fewer training steps. Furthermore, it establishes a new benchmark for parallel text generation, effectively bridging the performance gap between parallel and sequential decoding.
How Many Heads Make an SSM? A Unified Framework for Attention and State Space Models
Dec 17, 2025Sequence modeling has produced diverse architectures -- from classical recurrent neural networks to modern Transformers and state space models (SSMs) -- yet a unified theoretical understanding of expressivity and trainability trade-offs remains limited. We introduce a unified framework that represents a broad class of sequence maps via an input-dependent effective interaction operator $W_{ij}(X)$, making explicit two recurring construction patterns: (i) the Unified Factorized Framework (Explicit) (attention-style mixing), in which $W_{ij}(X)$ varies through scalar coefficients applied to shared value maps, and (ii) Structured Dynamics (Implicit) (state-space recurrences), in which $W_{ij}$ is induced by a latent dynamical system. Using this framework, we derive three theoretical results. First, we establish the Interaction Rank Gap: models in the Unified Factorized Framework, such as single-head attention, are constrained to a low-dimensional operator span and cannot represent certain structured dynamical maps. Second, we prove an Equivalence (Head-Count) Theorem showing that, within our multi-head factorized class, representing a linear SSM whose lag operators span a $k$-dimensional subspace on length-$n$ sequences requires and is achievable with $H=k$ heads. Third, we prove a Gradient Highway Result, showing that attention layers admit inputs with distance-independent gradient paths, whereas stable linear dynamics exhibit distance-dependent gradient attenuation. Together, these results formalize a fundamental trade-off between algebraic expressivity (interaction/operator span) and long-range gradient propagation, providing theoretical grounding for modern sequence architecture design.
Disentangling the Complex Multiplexed DIA Spectra in De Novo Peptide Sequencing
Nov 24, 2024Data-Independent Acquisition (DIA) was introduced to improve sensitivity to cover all peptides in a range rather than only sampling high-intensity peaks as in Data-Dependent Acquisition (DDA) mass spectrometry. However, it is not very clear how useful DIA data is for de novo peptide sequencing as the DIA data are marred with coeluted peptides, high noises, and varying data quality. We present a new deep learning method DIANovo, and address each of these difficulties, and improves the previous established system DeepNovo-DIA by from 25% to 81%, averaging 48%, for amino acid recall, and by from 27% to 89%, averaging 57%, for peptide recall, by equipping the model with a deeper understanding of coeluted DIA spectra. This paper also provides criteria about when DIA data could be used for de novo peptide sequencing and when not to by providing a comparison between DDA and DIA, in both de novo and database search mode. We find that while DIA excels with narrow isolation windows on older-generation instruments, it loses its advantage with wider windows. However, with Orbitrap Astral, DIA consistently outperforms DDA due to narrow window mode enabled. We also provide a theoretical explanation of this phenomenon, emphasizing the critical role of the signal-to-noise profile in the successful application of de novo sequencing.
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Sep 22, 2024



Large Language Models (LLMs), with their increasing depth and number of parameters, have demonstrated outstanding performance across a variety of natural language processing tasks. However, this growth in scale leads to increased computational demands, particularly during inference and fine-tuning. To address these challenges, we introduce EchoAtt, a novel framework aimed at optimizing transformer-based models by analyzing and leveraging the similarity of attention patterns across layers. Our analysis reveals that many inner layers in LLMs, especially larger ones, exhibit highly similar attention matrices. By exploiting this similarity, EchoAtt enables the sharing of attention matrices in less critical layers, significantly reducing computational requirements without compromising performance. We incorporate this approach within a knowledge distillation setup, where a pre-trained teacher model guides the training of a smaller student model. The student model selectively shares attention matrices in layers with high similarity while inheriting key parameters from the teacher. Our best results with TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15\%, training speed by 25\%, and reduces the number of parameters by approximately 4\%, all while improving zero-shot performance. These findings highlight the potential of attention matrix sharing to enhance the efficiency of LLMs, making them more practical for real-time and resource-limited applications.
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Jul 02, 2024



Deployment of autoregressive large language models (LLMs) is costly, and as these models increase in size, the associated costs will become even more considerable. Consequently, different methods have been proposed to accelerate the token generation process and reduce costs. Speculative decoding (SD) is among the most promising approaches to speed up the LLM decoding process by verifying multiple tokens in parallel and using an auxiliary smaller draft model to generate the possible tokens. In SD, usually, one draft model is used to serve a specific target model; however, in practice, LLMs are diverse, and we might need to deal with many target models or more than one target model simultaneously. In this scenario, it is not clear which draft model should be used for which target model, and searching among different draft models or training customized draft models can further increase deployment costs. In this paper, we first introduce a novel multi-target scenario for the deployment of draft models for faster inference. Then, we present a novel, more efficient sorted speculative decoding mechanism that outperforms regular baselines in multi-target settings. We evaluated our method on Spec-Bench in different settings, including base models such as Vicuna 7B, 13B, and LLama Chat 70B. Our results suggest that our draft models perform better than baselines for multiple target models at the same time.
Learning Chemotherapy Drug Action via Universal Physics-Informed Neural Networks
Apr 11, 2024Quantitative systems pharmacology (QSP) is widely used to assess drug effects and toxicity before the drug goes to clinical trial. However, significant manual distillation of the literature is needed in order to construct a QSP model. Parameters may need to be fit, and simplifying assumptions of the model need to be made. In this work, we apply Universal Physics-Informed Neural Networks (UPINNs) to learn unknown components of various differential equations that model chemotherapy pharmacodynamics. We learn three commonly employed chemotherapeutic drug actions (log-kill, Norton-Simon, and E_max) from synthetic data. Then, we use the UPINN method to fit the parameters for several synthetic datasets simultaneously. Finally, we learn the net proliferation rate in a model of doxorubicin (a chemotherapeutic) pharmacodynamics. As these are only toy examples, we highlight the usefulness of UPINNs in learning unknown terms in pharmacodynamic and pharmacokinetic models.
Orchid: Flexible and Data-Dependent Convolution for Sequence Modeling
Feb 28, 2024

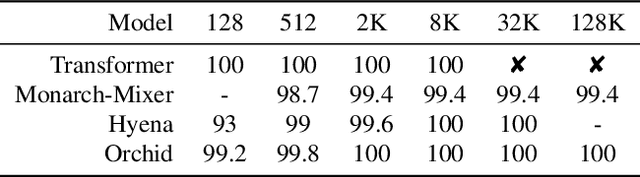

In the rapidly evolving landscape of deep learning, the quest for models that balance expressivity with computational efficiency has never been more critical. This paper introduces Orchid, a novel architecture that reimagines sequence modeling by incorporating a new data-dependent convolution mechanism. Orchid is designed to address the inherent limitations of traditional attention mechanisms, particularly their quadratic complexity, without compromising the ability to capture long-range dependencies and in-context learning. At the core of Orchid lies the data-dependent convolution layer, which dynamically adjusts its kernel conditioned on input data using a dedicated conditioning neural network. We design two simple conditioning networks that maintain shift equivariance in the adaptive convolution operation. The dynamic nature of data-dependent convolution kernel, coupled with gating operations, grants Orchid high expressivity while maintaining efficiency and quasilinear scalability for long sequences. We rigorously evaluate Orchid across multiple domains, including language modeling and image classification, to showcase its performance and generality. Our experiments demonstrate that Orchid architecture not only outperforms traditional attention-based architectures such as BERT and Vision Transformers with smaller model sizes, but also extends the feasible sequence length beyond the limitations of the dense attention layers. This achievement represents a significant step towards more efficient and scalable deep learning models for sequence modeling.
QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning
Feb 16, 2024



Finetuning large language models requires huge GPU memory, restricting the choice to acquire Larger models. While the quantized version of the Low-Rank Adaptation technique, named QLoRA, significantly alleviates this issue, finding the efficient LoRA rank is still challenging. Moreover, QLoRA is trained on a pre-defined rank and, therefore, cannot be reconfigured for its lower ranks without requiring further fine-tuning steps. This paper proposes QDyLoRA -Quantized Dynamic Low-Rank Adaptation-, as an efficient quantization approach for dynamic low-rank adaptation. Motivated by Dynamic LoRA, QDyLoRA is able to efficiently finetune LLMs on a set of pre-defined LoRA ranks. QDyLoRA enables fine-tuning Falcon-40b for ranks 1 to 64 on a single 32 GB V100-GPU through one round of fine-tuning. Experimental results show that QDyLoRA is competitive to QLoRA and outperforms when employing its optimal rank.
WERank: Towards Rank Degradation Prevention for Self-Supervised Learning Using Weight Regularization
Feb 14, 2024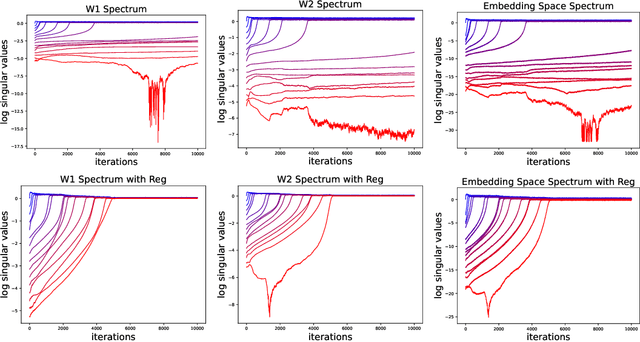
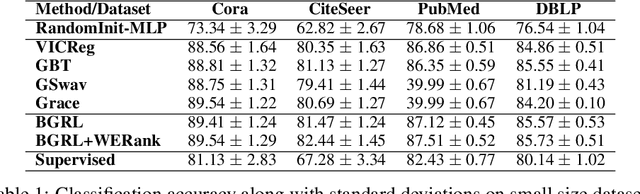
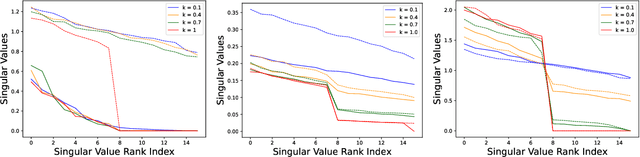
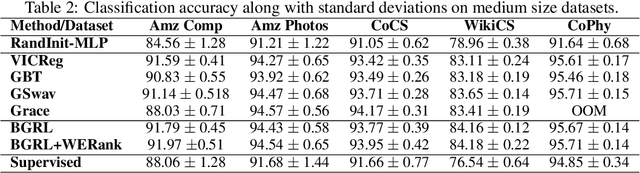
A common phenomena confining the representation quality in Self-Supervised Learning (SSL) is dimensional collapse (also known as rank degeneration), where the learned representations are mapped to a low dimensional subspace of the representation space. The State-of-the-Art SSL methods have shown to suffer from dimensional collapse and fall behind maintaining full rank. Recent approaches to prevent this problem have proposed using contrastive losses, regularization techniques, or architectural tricks. We propose WERank, a new regularizer on the weight parameters of the network to prevent rank degeneration at different layers of the network. We provide empirical evidence and mathematical justification to demonstrate the effectiveness of the proposed regularization method in preventing dimensional collapse. We verify the impact of WERank on graph SSL where dimensional collapse is more pronounced due to the lack of proper data augmentation. We empirically demonstrate that WERank is effective in helping BYOL to achieve higher rank during SSL pre-training and consequently downstream accuracy during evaluation probing. Ablation studies and experimental analysis shed lights on the underlying factors behind the performance gains of the proposed approach.
Scalable Graph Self-Supervised Learning
Feb 14, 2024



In regularization Self-Supervised Learning (SSL) methods for graphs, computational complexity increases with the number of nodes in graphs and embedding dimensions. To mitigate the scalability of non-contrastive graph SSL, we propose a novel approach to reduce the cost of computing the covariance matrix for the pre-training loss function with volume-maximization terms. Our work focuses on reducing the cost associated with the loss computation via graph node or dimension sampling. We provide theoretical insight into why dimension sampling would result in accurate loss computations and support it with mathematical derivation of the novel approach. We develop our experimental setup on the node-level graph prediction tasks, where SSL pre-training has shown to be difficult due to the large size of real world graphs. Our experiments demonstrate that the cost associated with the loss computation can be reduced via node or dimension sampling without lowering the downstream performance. Our results demonstrate that sampling mostly results in improved downstream performance. Ablation studies and experimental analysis are provided to untangle the role of the different factors in the experimental setup.