 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
May 06, 2026SWE-bench-style agentic reinforcement learning relies on expensive stateful trajectories, yet substantial compute is wasted on sampled rollout groups with skewed pass rates, where binary rewards provide a weak contrastive signal. We frame this inefficiency as a pass-rate control problem and show that a 50% pass rate is the most informative operating point: it maximizes reward entropy, the probability of surviving group filtering, RLOO advantage energy under GRPO, and success--failure contrastive structure. Guided by this principle, we propose Prefix Sampling (PS), which replays trajectory prefixes to steer skewed groups toward this regime: successful prefixes serve as head starts for mostly failing groups, while failing prefixes serve as handicaps for mostly passing groups. In stateful agent environments, prefix states are reconstructed through replay while replayed tokens are excluded from the loss, restricting optimization to continuations generated by the current policy. On SWE-bench-style agentic RL, PS delivers end-to-end wall-clock speedups of 2.01x on Qwen3-14B and 1.55x on Qwen3-32B while preserving or improving final verified performance. For 14B, the SWE-bench Verified peak rises from the baseline peak of 0.273 to 0.295 under PS. Additional mathematical reasoning experiments on AIME 2025 show the same pass-rate control pattern and decompose the gains into replay, bidirectional coverage, and adaptive control.
SWE-Hub: A Unified Production System for Scalable, Executable Software Engineering Tasks
Feb 28, 2026Progress in software-engineering agents is increasingly constrained by the scarcity of executable, scalable, and realistic data for training and evaluation. This scarcity stems from three fundamental challenges in existing pipelines: environments are brittle and difficult to reproduce across languages; synthesizing realistic, system-level bugs at scale is computationally expensive; and existing data predominantly consists of short-horizon repairs, failing to capture long-horizon competencies like architectural consistency. We introduce \textbf{SWE-Hub}, an end-to-end system that operationalizes the data factory abstraction by unifying environment automation, scalable synthesis, and diverse task generation into a coherent production stack. At its foundation, the \textbf{Env Agent} establishes a shared execution substrate by automatically converting raw repository snapshots into reproducible, multi-language container environments with standardized interfaces. Built upon this substrate, \textbf{SWE-Scale} engine addresses the need for high-throughput generation, combining cross-language code analysis with cluster-scale validation to synthesize massive volumes of localized bug-fix instances. \textbf{Bug Agent} generates high-fidelity repair tasks by synthesizing system-level regressions involving cross-module dependencies, paired with user-like issue reports that describe observable symptoms rather than root causes. Finally, \textbf{SWE-Architect} expands the task scope from repair to creation by translating natural-language requirements into repository-scale build-a-repo tasks. By integrating these components, SWE-Hub establishes a unified production pipeline capable of continuously delivering executable tasks across the entire software engineering lifecycle.
QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning
Feb 16, 2024



Finetuning large language models requires huge GPU memory, restricting the choice to acquire Larger models. While the quantized version of the Low-Rank Adaptation technique, named QLoRA, significantly alleviates this issue, finding the efficient LoRA rank is still challenging. Moreover, QLoRA is trained on a pre-defined rank and, therefore, cannot be reconfigured for its lower ranks without requiring further fine-tuning steps. This paper proposes QDyLoRA -Quantized Dynamic Low-Rank Adaptation-, as an efficient quantization approach for dynamic low-rank adaptation. Motivated by Dynamic LoRA, QDyLoRA is able to efficiently finetune LLMs on a set of pre-defined LoRA ranks. QDyLoRA enables fine-tuning Falcon-40b for ranks 1 to 64 on a single 32 GB V100-GPU through one round of fine-tuning. Experimental results show that QDyLoRA is competitive to QLoRA and outperforms when employing its optimal rank.
HiCu: Leveraging Hierarchy for Curriculum Learning in Automated ICD Coding
Aug 03, 2022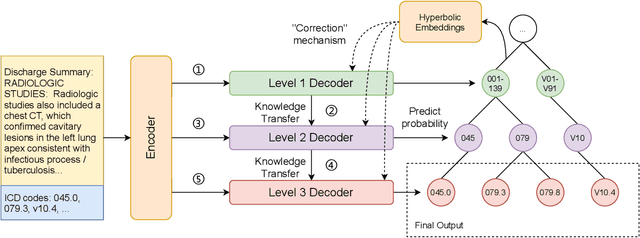
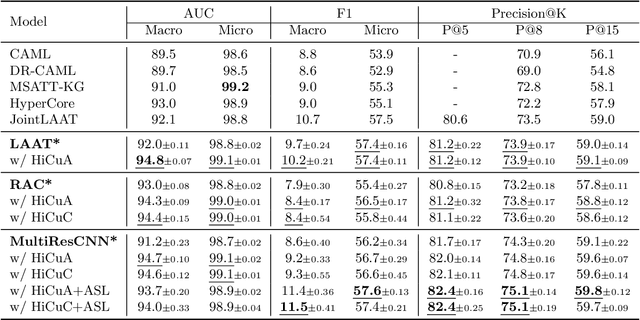
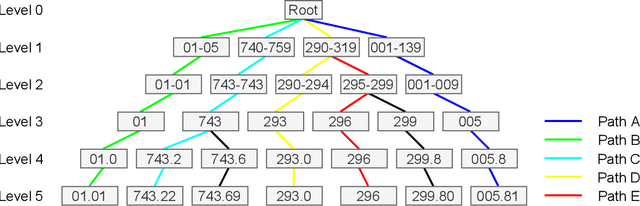
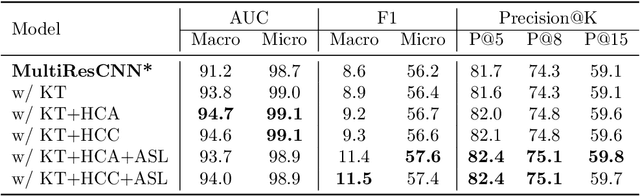
There are several opportunities for automation in healthcare that can improve clinician throughput. One such example is assistive tools to document diagnosis codes when clinicians write notes. We study the automation of medical code prediction using curriculum learning, which is a training strategy for machine learning models that gradually increases the hardness of the learning tasks from easy to difficult. One of the challenges in curriculum learning is the design of curricula -- i.e., in the sequential design of tasks that gradually increase in difficulty. We propose Hierarchical Curriculum Learning (HiCu), an algorithm that uses graph structure in the space of outputs to design curricula for multi-label classification. We create curricula for multi-label classification models that predict ICD diagnosis and procedure codes from natural language descriptions of patients. By leveraging the hierarchy of ICD codes, which groups diagnosis codes based on various organ systems in the human body, we find that our proposed curricula improve the generalization of neural network-based predictive models across recurrent, convolutional, and transformer-based architectures. Our code is available at https://github.com/wren93/HiCu-ICD.
EAANet: Efficient Attention Augmented Convolutional Networks
Jun 03, 2022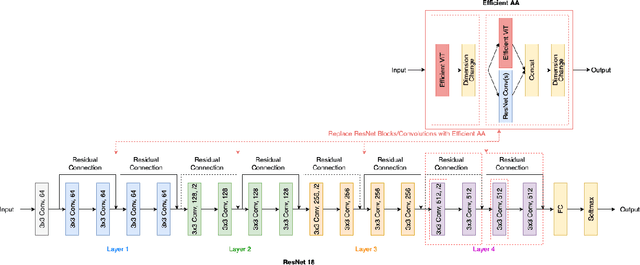

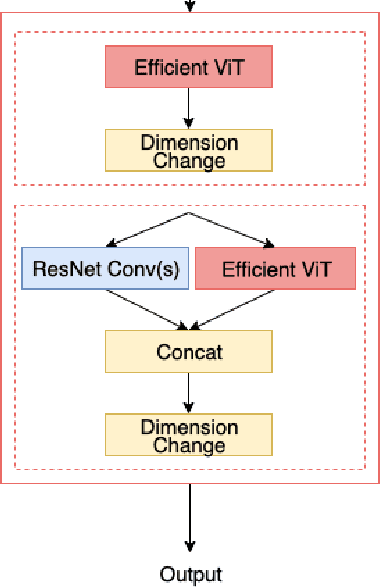

Humans can effectively find salient regions in complex scenes. Self-attention mechanisms were introduced into Computer Vision (CV) to achieve this. Attention Augmented Convolutional Network (AANet) is a mixture of convolution and self-attention, which increases the accuracy of a typical ResNet. However, The complexity of self-attention is O(n2) in terms of computation and memory usage with respect to the number of input tokens. In this project, we propose EAANet: Efficient Attention Augmented Convolutional Networks, which incorporates efficient self-attention mechanisms in a convolution and self-attention hybrid architecture to reduce the model's memory footprint. Our best model show performance improvement over AA-Net and ResNet18. We also explore different methods to augment Convolutional Network with self-attention mechanisms and show the difficulty of training those methods compared to ResNet. Finally, we show that augmenting efficient self-attention mechanisms with ResNet scales better with input size than normal self-attention mechanisms. Therefore, our EAANet is more capable of working with high-resolution images.