 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Drop: Temporal LoRA Decoding for Efficient LLM Inference
Jan 05, 2026Autoregressive large language models (LLMs) are bottlenecked by sequential decoding, where each new token typically requires executing all transformer layers. Existing dynamic-depth and layer-skipping methods reduce this cost, but often rely on auxiliary routing mechanisms or incur accuracy degradation when bypassed layers are left uncompensated. We present \textbf{LoRA-Drop}, a plug-and-play inference framework that accelerates decoding by applying a \emph{temporal compute schedule} to a fixed subset of intermediate layers: on most decoding steps, selected layers reuse the previous-token hidden state and apply a low-rank LoRA correction, while periodic \emph{refresh} steps execute the full model to prevent drift. LoRA-Drop requires no routing network, is compatible with standard KV caching, and can reduce KV-cache footprint by skipping KV updates in droppable layers during LoRA steps and refreshing periodically. Across \textbf{LLaMA2-7B}, \textbf{LLaMA3-8B}, \textbf{Qwen2.5-7B}, and \textbf{Qwen2.5-14B}, LoRA-Drop achieves up to \textbf{2.6$\times$ faster decoding} and \textbf{45--55\% KV-cache reduction} while staying within \textbf{0.5 percentage points (pp)} of baseline accuracy. Evaluations on reasoning (GSM8K, MATH, BBH), code generation (HumanEval, MBPP), and long-context/multilingual benchmarks (LongBench, XNLI, XCOPA) identify a consistent \emph{safe zone} of scheduling configurations that preserves quality while delivering substantial efficiency gains, providing a simple path toward adaptive-capacity inference in LLMs. Codes are available at https://github.com/hosseinbv/LoRA-Drop.git.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Jan 04, 2026Scaling training compute, measured in FLOPs, has long been shown to improve the accuracy of large language models, yet training remains resource-intensive. Prior work shows that increasing test-time compute (TTC)-for example through iterative sampling-can allow smaller models to rival or surpass much larger ones at lower overall cost. We introduce TTC-aware training, where an intermediate checkpoint and a corresponding TTC configuration can together match or exceed the accuracy of a fully trained model while requiring substantially fewer training FLOPs. Building on this insight, we propose an early stopping algorithm that jointly selects a checkpoint and TTC configuration to minimize training compute without sacrificing accuracy. To make this practical, we develop an efficient TTC evaluation method that avoids exhaustive search, and we formalize a break-even bound that identifies when increased inference compute compensates for reduced training compute. Experiments demonstrate up to 92\% reductions in training FLOPs while maintaining and sometimes remarkably improving accuracy. These results highlight a new perspective for balancing training and inference compute in model development, enabling faster deployment cycles and more frequent model refreshes. Codes will be publicly released.
Bayesian Mixture of Experts For Large Language Models
Nov 12, 2025We present Bayesian Mixture of Experts (Bayesian-MoE), a post-hoc uncertainty estimation framework for fine-tuned large language models (LLMs) based on Mixture-of-Experts architectures. Our method applies a structured Laplace approximation to the second linear layer of each expert, enabling calibrated uncertainty estimation without modifying the original training procedure or introducing new parameters. Unlike prior approaches, which apply Bayesian inference to added adapter modules, Bayesian-MoE directly targets the expert pathways already present in MoE models, leveraging their modular design for tractable block-wise posterior estimation. We use Kronecker-factored low-rank approximations to model curvature and derive scalable estimates of predictive uncertainty and marginal likelihood. Experiments on common-sense reasoning benchmarks with Qwen1.5-MoE and DeepSeek-MoE demonstrate that Bayesian-MoE improves both expected calibration error (ECE) and negative log-likelihood (NLL) over baselines, confirming its effectiveness for reliable downstream decision-making.
ECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
Balcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
E2E-Swin-Unet++: An Enhanced End-to-End Swin-Unet Architecture With Dual Decoders For PTMC Segmentation
Oct 23, 2024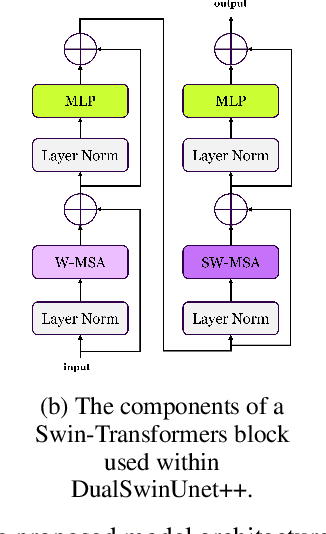
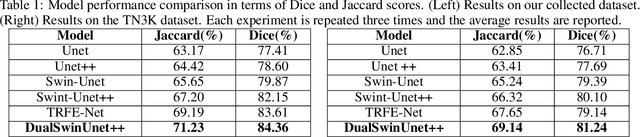
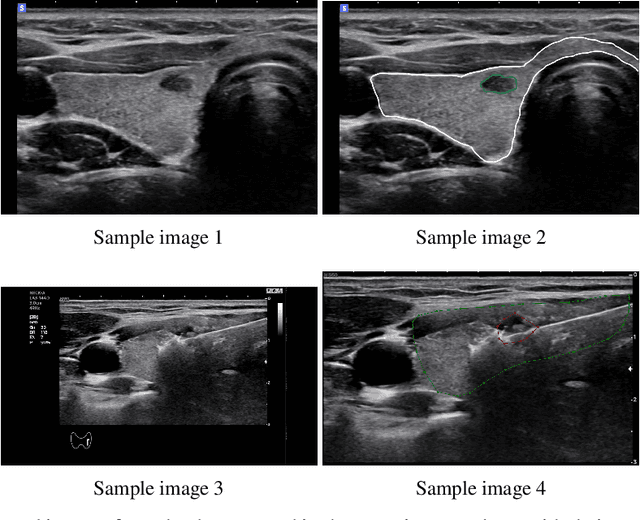
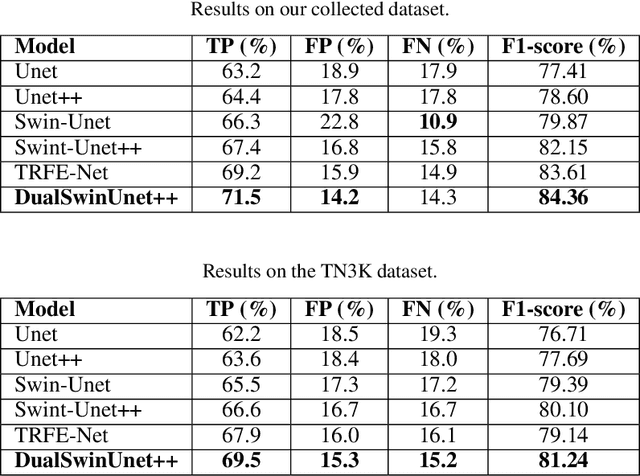
Efficiently managing papillary thyroid microcarcinoma (PTMC) while minimizing patient discomfort poses a significant clinical challenge. Radiofrequency ablation (RFA) offers a less invasive alternative to surgery and radiation therapy for PTMC treatment, characterized by shorter recovery times and reduced pain. As an image-guided procedure, RFA generates localized heat by delivering high-frequency electrical currents through electrodes to the targeted area under ultrasound imaging guidance. However, the precision and skill required by operators for accurate guidance using current ultrasound B-mode imaging technologies remain significant challenges. To address these challenges, we develop a novel AI segmentation model, E2E-Swin-Unet++. This model enhances ultrasound B-mode imaging by enabling real-time identification and segmentation of PTMC tumors and monitoring of the region of interest for precise targeting during treatment. E2E-Swin- Unet++ is an advanced end-to-end extension of the Swin-Unet architecture, incorporating thyroid region information to minimize the risk of false PTMC segmentation while providing fast inference capabilities. Experimental results on a real clinical RFA dataset demonstrate the superior performance of E2E-Swin-Unet++ compared to related models. Our proposed solution significantly improves the precision and control of RFA ablation treatment by enabling real-time identification and segmentation of PTMC margins during the procedure.
EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models
Sep 22, 2024



Large Language Models (LLMs), with their increasing depth and number of parameters, have demonstrated outstanding performance across a variety of natural language processing tasks. However, this growth in scale leads to increased computational demands, particularly during inference and fine-tuning. To address these challenges, we introduce EchoAtt, a novel framework aimed at optimizing transformer-based models by analyzing and leveraging the similarity of attention patterns across layers. Our analysis reveals that many inner layers in LLMs, especially larger ones, exhibit highly similar attention matrices. By exploiting this similarity, EchoAtt enables the sharing of attention matrices in less critical layers, significantly reducing computational requirements without compromising performance. We incorporate this approach within a knowledge distillation setup, where a pre-trained teacher model guides the training of a smaller student model. The student model selectively shares attention matrices in layers with high similarity while inheriting key parameters from the teacher. Our best results with TinyLLaMA-1.1B demonstrate that EchoAtt improves inference speed by 15\%, training speed by 25\%, and reduces the number of parameters by approximately 4\%, all while improving zero-shot performance. These findings highlight the potential of attention matrix sharing to enhance the efficiency of LLMs, making them more practical for real-time and resource-limited applications.
QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning
Feb 16, 2024



Finetuning large language models requires huge GPU memory, restricting the choice to acquire Larger models. While the quantized version of the Low-Rank Adaptation technique, named QLoRA, significantly alleviates this issue, finding the efficient LoRA rank is still challenging. Moreover, QLoRA is trained on a pre-defined rank and, therefore, cannot be reconfigured for its lower ranks without requiring further fine-tuning steps. This paper proposes QDyLoRA -Quantized Dynamic Low-Rank Adaptation-, as an efficient quantization approach for dynamic low-rank adaptation. Motivated by Dynamic LoRA, QDyLoRA is able to efficiently finetune LLMs on a set of pre-defined LoRA ranks. QDyLoRA enables fine-tuning Falcon-40b for ranks 1 to 64 on a single 32 GB V100-GPU through one round of fine-tuning. Experimental results show that QDyLoRA is competitive to QLoRA and outperforms when employing its optimal rank.
Multimodal Multi-Hop Question Answering Through a Conversation Between Tools and Efficiently Finetuned Large Language Models
Sep 16, 2023



We employ a tool-interacting divide-and-conquer strategy enabling large language models (LLMs) to answer complex multimodal multi-hop questions. In particular, we harness the power of large language models to divide a given multimodal multi-hop question into unimodal single-hop sub-questions to be answered by the appropriate tool from a predefined set of tools. After all corresponding tools provide the LLM with their answers, the LLM generates the next relevant unimodal single-hop question. To increase the reasoning ability of LLMs, we prompt chatGPT to generate a tool-interacting divide-and-conquer dataset. This dataset is then used to efficiently finetune the corresponding LLM. To assess the effectiveness of this approach, we conduct an evaluation on two recently introduced complex question-answering datasets. The experimental analysis demonstrate substantial improvements over existing state-of-the-art solutions, indicating the efficacy and generality of our strategy
SortedNet, a Place for Every Network and Every Network in its Place: Towards a Generalized Solution for Training Many-in-One Neural Networks
Sep 01, 2023As the size of deep learning models continues to grow, finding optimal models under memory and computation constraints becomes increasingly more important. Although usually the architecture and constituent building blocks of neural networks allow them to be used in a modular way, their training process is not aware of this modularity. Consequently, conventional neural network training lacks the flexibility to adapt the computational load of the model during inference. This paper proposes SortedNet, a generalized and scalable solution to harness the inherent modularity of deep neural networks across various dimensions for efficient dynamic inference. Our training considers a nested architecture for the sub-models with shared parameters and trains them together with the main model in a sorted and probabilistic manner. This sorted training of sub-networks enables us to scale the number of sub-networks to hundreds using a single round of training. We utilize a novel updating scheme during training that combines random sampling of sub-networks with gradient accumulation to improve training efficiency. Furthermore, the sorted nature of our training leads to a search-free sub-network selection at inference time; and the nested architecture of the resulting sub-networks leads to minimal storage requirement and efficient switching between sub-networks at inference. Our general dynamic training approach is demonstrated across various architectures and tasks, including large language models and pre-trained vision models. Experimental results show the efficacy of the proposed approach in achieving efficient sub-networks while outperforming state-of-the-art dynamic training approaches. Our findings demonstrate the feasibility of training up to 160 different sub-models simultaneously, showcasing the extensive scalability of our proposed method while maintaining 96% of the model performance.