 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPAS: Efficient Training with Progressive Activation Sharing
Jan 27, 2026We present a novel method for Efficient training with Progressive Activation Sharing (EPAS). This method bridges progressive training paradigm with the phenomenon of redundant QK (or KV ) activations across deeper layers of transformers. EPAS gradually grows a sharing region during training by switching decoder layers to activation sharing mode. This results in throughput increase due to reduced compute. To utilize deeper layer redundancy, the sharing region starts from the deep end of the model and grows towards the shallow end. The EPAS trained models allow for variable region lengths of activation sharing for different compute budgets during inference. Empirical evaluations with QK activation sharing in LLaMA models ranging from 125M to 7B parameters show up to an 11.1% improvement in training throughput and up to a 29% improvement in inference throughput while maintaining similar loss curve to the baseline models. Furthermore, applying EPAS in continual pretraining to transform TinyLLaMA into an attention-sharing model yields up to a 10% improvement in average accuracy over state-of-the-art methods, emphasizing the significance of progressive training in cross layer activation sharing models.
Thinking Long, but Short: Stable Sequential Test-Time Scaling for Large Reasoning Models
Jan 14, 2026Sequential test-time scaling is a promising training-free method to improve large reasoning model accuracy, but as currently implemented, significant limitations have been observed. Inducing models to think for longer can increase their accuracy, but as the length of reasoning is further extended, it has also been shown to result in accuracy degradation and model instability. This work presents a novel sequential test-time scaling method, Min-Seek, which improves model accuracy significantly over a wide range of induced thoughts, stabilizing the accuracy of sequential scaling, and removing the need for reasoning length fine-tuning. Beyond improving model accuracy over a variety of reasoning tasks, our method is inherently efficient, as only the KV pairs of one additional induced thought are kept in the KV cache during reasoning. With a custom KV cache which stores keys without position embeddings, by dynamically encoding them contiguously before each new generated thought, our method can continue to reason well beyond a model's maximum context length, and under mild conditions has linear computational complexity.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
Nested-ReFT: Efficient Reinforcement Learning for Large Language Model Fine-Tuning via Off-Policy Rollouts
Aug 13, 2025Advanced reasoning in LLMs on challenging domains like mathematical reasoning can be tackled using verifiable rewards based reinforced fine-tuning (ReFT). In standard ReFT frameworks, a behavior model generates multiple completions with answers per problem, for the answer to be then scored by a reward function. While such RL post-training methods demonstrate significant performance improvements across challenging reasoning domains, the computational cost of generating completions during training with multiple inference steps makes the training cost non-trivial. To address this, we draw inspiration from off-policy RL, and speculative decoding to introduce a novel ReFT framework, dubbed Nested-ReFT, where a subset of layers of the target model acts as the behavior model to generate off-policy completions during training. The behavior model configured with dynamic layer skipping per batch during training decreases the inference cost compared to the standard ReFT frameworks. Our theoretical analysis shows that Nested-ReFT yields unbiased gradient estimates with controlled variance. Our empirical analysis demonstrates improved computational efficiency measured as tokens/sec across multiple math reasoning benchmarks and model sizes. Additionally, we explore three variants of bias mitigation to minimize the off-policyness in the gradient updates that allows for maintaining performance that matches the baseline ReFT performance.
PoTPTQ: A Two-step Power-of-Two Post-training for LLMs
Jul 16, 2025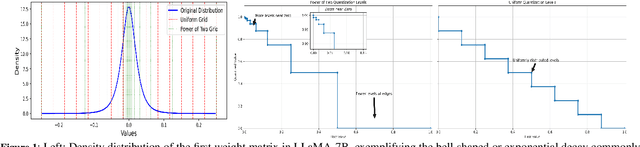
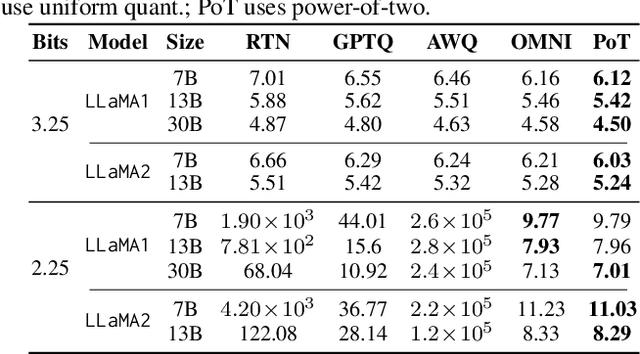
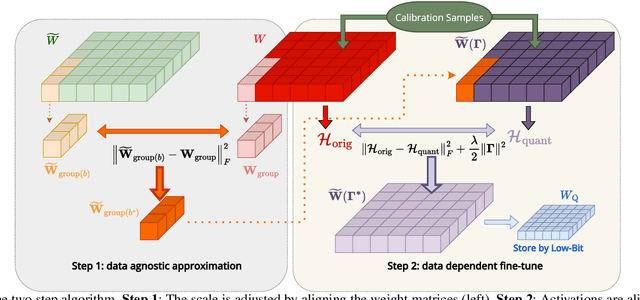
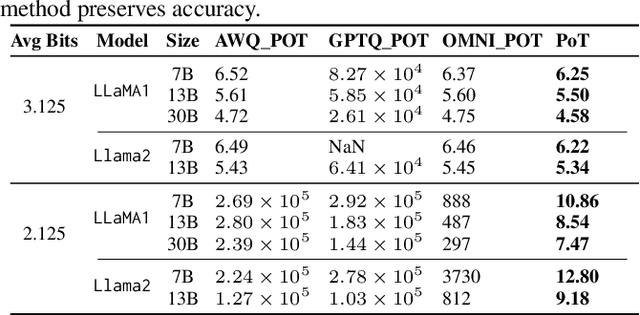
Large Language Models (LLMs) have demonstrated remarkable performance across various natural language processing (NLP) tasks. However, their deployment is challenging due to the substantial computational resources required. Power-of-two (PoT) quantization is a general tool to counteract this difficulty. Albeit previous works on PoT quantization can be efficiently dequantized on CPUs using fixed-point addition, it showed less effectiveness on GPUs. The reason is entanglement of the sign bit and sequential bit manipulations needed for dequantization. We propose a novel POT quantization framework for LLM weights that (i) outperforms state-of-the-art accuracy in extremely low-precision number formats, and (ii) enables faster inference through more efficient dequantization. To maintain the accuracy of the quantized model, we introduce a two-step post-training algorithm: (i) initialize the quantization scales with a robust starting point, and (ii) refine these scales using a minimal calibration set. The performance of our PoT post-training algorithm surpasses the current state-of-the-art in integer quantization, particularly at low precisions such as 2- and 3-bit formats. Our PoT quantization accelerates the dequantization step required for the floating point inference and leads to $3.67\times$ speed up on a NVIDIA V100, and $1.63\times$ on a NVIDIA RTX 4090, compared to uniform integer dequantization.
ECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
Resona: Improving Context Copying in Linear Recurrence Models with Retrieval
Mar 28, 2025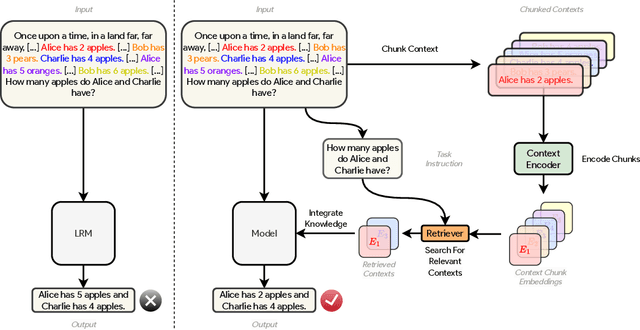

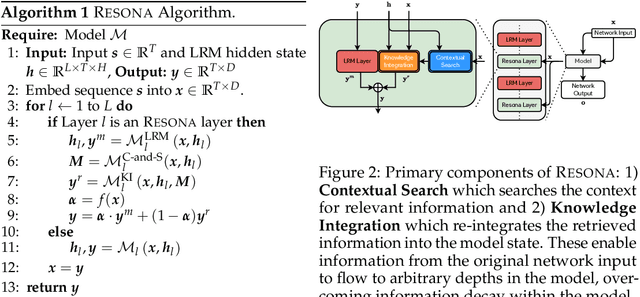
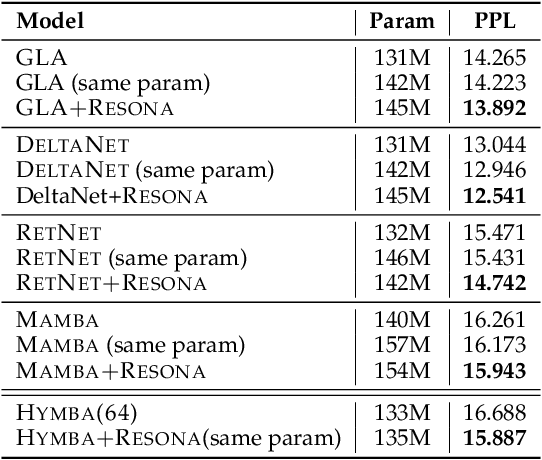
Recent shifts in the space of large language model (LLM) research have shown an increasing focus on novel architectures to compete with prototypical Transformer-based models that have long dominated this space. Linear recurrent models have proven to be a viable competitor due to their computational efficiency. However, such models still demonstrate a sizable gap compared to Transformers in terms of in-context learning among other tasks that require recalling information from a context. In this work, we introduce __Resona__, a simple and scalable framework for augmenting linear recurrent models with retrieval. __Resona__~augments models with the ability to integrate retrieved information from the provided input context, enabling tailored behavior to diverse task requirements. Experiments on a variety of linear recurrent models demonstrate that __Resona__-augmented models observe significant performance gains on a variety of synthetic as well as real-world natural language tasks, highlighting its ability to act as a general purpose method to improve the in-context learning and language modeling abilities of linear recurrent LLMs.
Balcony: A Lightweight Approach to Dynamic Inference of Generative Language Models
Mar 06, 2025Deploying large language models (LLMs) in real-world applications is often hindered by strict computational and latency constraints. While dynamic inference offers the flexibility to adjust model behavior based on varying resource budgets, existing methods are frequently limited by hardware inefficiencies or performance degradation. In this paper, we introduce Balcony, a simple yet highly effective framework for depth-based dynamic inference. By freezing the pretrained LLM and inserting additional transformer layers at selected exit points, Balcony maintains the full model's performance while enabling real-time adaptation to different computational budgets. These additional layers are trained using a straightforward self-distillation loss, aligning the sub-model outputs with those of the full model. This approach requires significantly fewer training tokens and tunable parameters, drastically reducing computational costs compared to prior methods. When applied to the LLaMA3-8B model, using only 0.2% of the original pretraining data, Balcony achieves minimal performance degradation while enabling significant speedups. Remarkably, we show that Balcony outperforms state-of-the-art methods such as Flextron and Layerskip as well as other leading compression techniques on multiple models and at various scales, across a variety of benchmarks.
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning
Feb 27, 2025

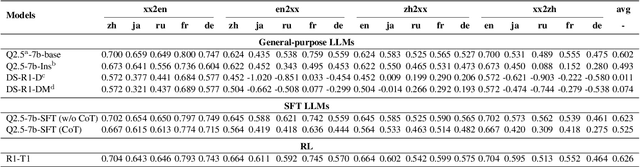
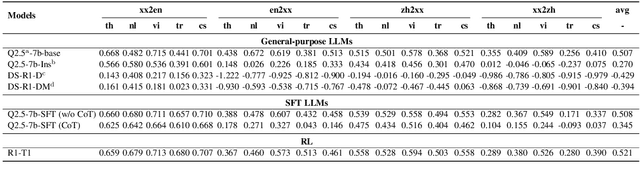
Despite recent breakthroughs in reasoning-enhanced large language models (LLMs) like DeepSeek-R1, incorporating inference-time reasoning into machine translation (MT), where human translators naturally employ structured, multi-layered reasoning chain-of-thoughts (CoTs), is yet underexplored. Existing methods either design a fixed CoT tailored for a specific MT sub-task (e.g., literature translation), or rely on synthesizing CoTs unaligned with humans and supervised fine-tuning (SFT) prone to catastrophic forgetting, limiting their adaptability to diverse translation scenarios. This paper introduces R1-Translator (R1-T1), a novel framework to achieve inference-time reasoning for general MT via reinforcement learning (RL) with human-aligned CoTs comprising six common patterns. Our approach pioneers three innovations: (1) extending reasoning-based translation beyond MT sub-tasks to six languages and diverse tasks (e.g., legal/medical domain adaptation, idiom resolution); (2) formalizing six expert-curated CoT templates that mirror hybrid human strategies like context-aware paraphrasing and back translation; and (3) enabling self-evolving CoT discovery and anti-forgetting adaptation through RL with KL-constrained rewards. Experimental results indicate a steady translation performance improvement in 21 languages and 80 translation directions on Flores-101 test set, especially on the 15 languages unseen from training, with its general multilingual abilities preserved compared with plain SFT.