 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Large Language Models to Log Analysis with Interpretable Domain Knowledge
Dec 02, 2024The increasing complexity of computer systems necessitates innovative approaches to fault and error management, going beyond traditional manual log analysis. While existing solutions using large language models (LLMs) show promise, they are limited by a gap between natural and domain-specific languages, which restricts their effectiveness in real-world applications. Our approach addresses these limitations by integrating interpretable domain knowledge into open-source LLMs through continual pre-training (CPT), enhancing performance on log tasks while retaining natural language processing capabilities. We created a comprehensive dataset, NLPLog, with over 250,000 question-answer pairs to facilitate this integration. Our model, SuperLog, trained with this dataset, achieves the best performance across four log analysis tasks, surpassing the second-best model by an average of 12.01%. Our contributions include a novel CPT paradigm that significantly improves model performance, the development of SuperLog with state-of-the-art results, and the release of a large-scale dataset to support further research in this domain.
Improvement of K Mean Clustering Algorithm Based on Density
Oct 09, 2018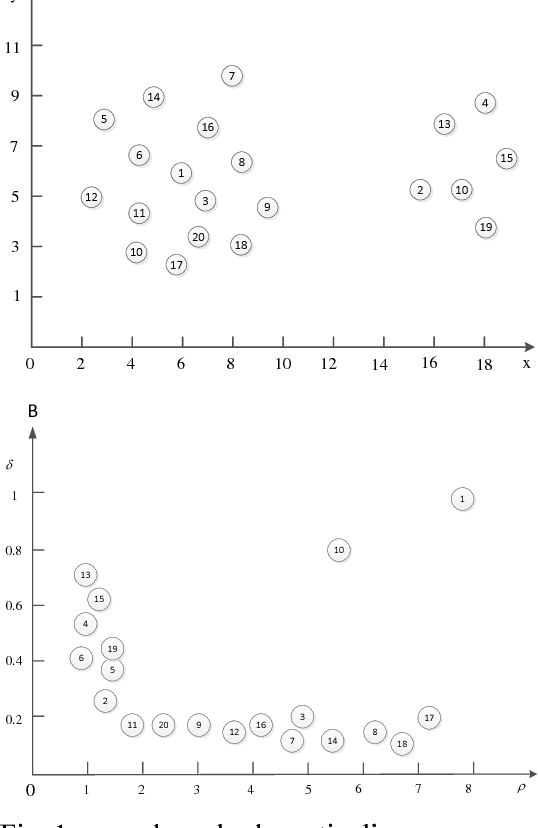
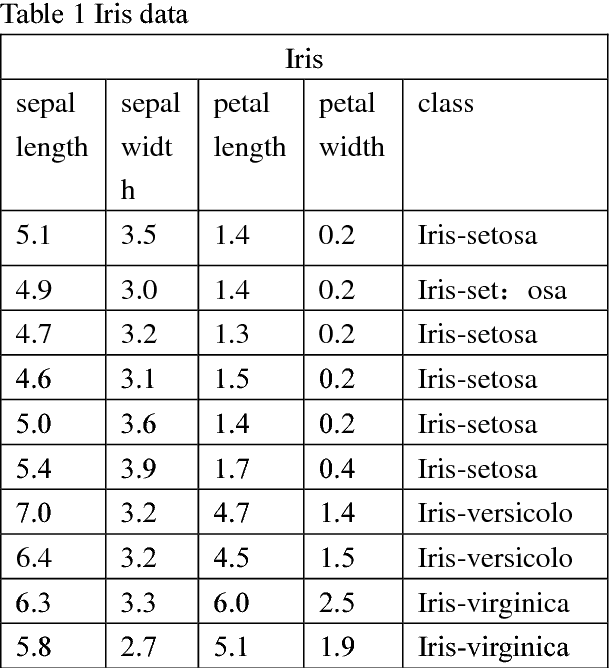
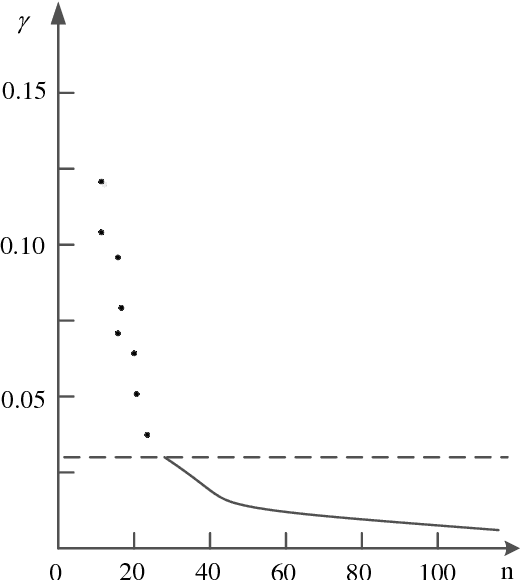
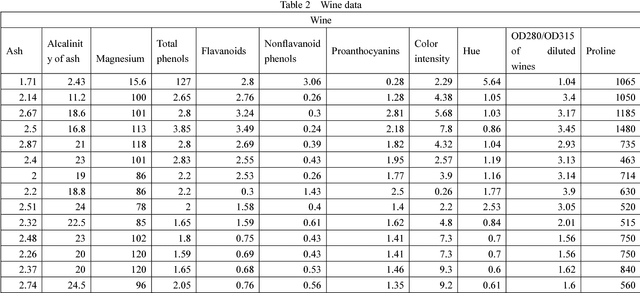
The purpose of this paper is to improve the traditional K-means algorithm. In the traditional K mean clustering algorithm, the initial clustering centers are generated randomly in the data set. It is easy to fall into the local minimum solution when the initial cluster centers are randomly generated. The initial clustering center selected by K-means clustering algorithm which based on density is more representative. The experimental results show that the improved K clustering algorithm can eliminate the dependence on the initial cluster, and the accuracy of clustering is improved.