Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement of K Mean Clustering Algorithm Based on Density
Oct 09, 2018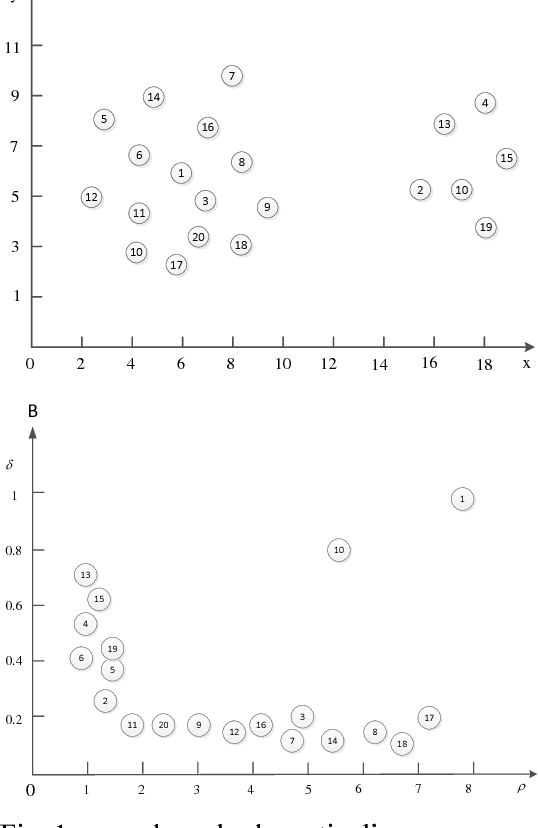
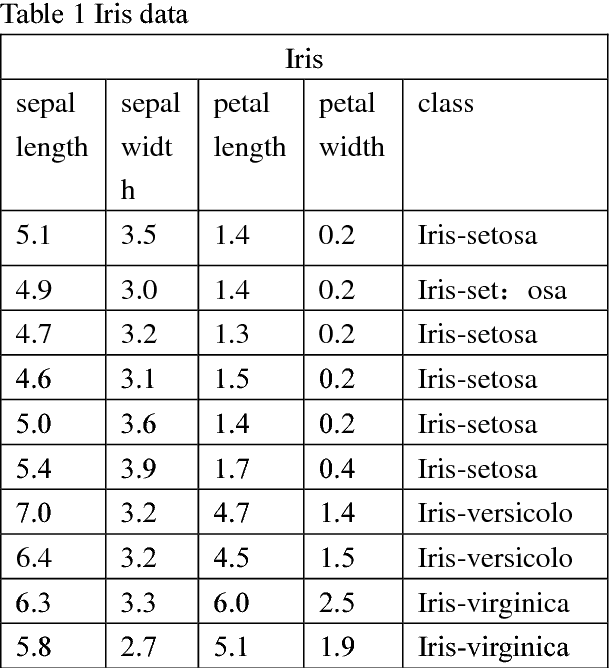
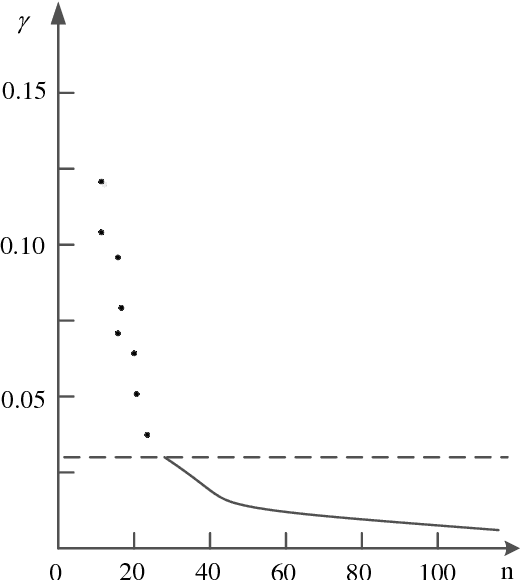
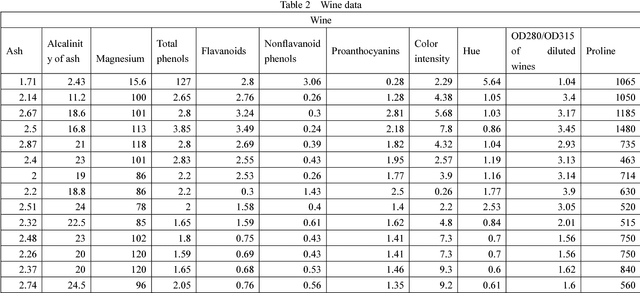
The purpose of this paper is to improve the traditional K-means algorithm. In the traditional K mean clustering algorithm, the initial clustering centers are generated randomly in the data set. It is easy to fall into the local minimum solution when the initial cluster centers are randomly generated. The initial clustering center selected by K-means clustering algorithm which based on density is more representative. The experimental results show that the improved K clustering algorithm can eliminate the dependence on the initial cluster, and the accuracy of clustering is improved.
Via