 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Large Language Models to Log Analysis with Interpretable Domain Knowledge
Dec 02, 2024The increasing complexity of computer systems necessitates innovative approaches to fault and error management, going beyond traditional manual log analysis. While existing solutions using large language models (LLMs) show promise, they are limited by a gap between natural and domain-specific languages, which restricts their effectiveness in real-world applications. Our approach addresses these limitations by integrating interpretable domain knowledge into open-source LLMs through continual pre-training (CPT), enhancing performance on log tasks while retaining natural language processing capabilities. We created a comprehensive dataset, NLPLog, with over 250,000 question-answer pairs to facilitate this integration. Our model, SuperLog, trained with this dataset, achieves the best performance across four log analysis tasks, surpassing the second-best model by an average of 12.01%. Our contributions include a novel CPT paradigm that significantly improves model performance, the development of SuperLog with state-of-the-art results, and the release of a large-scale dataset to support further research in this domain.
What Do You Want? User-centric Prompt Generation for Text-to-image Synthesis via Multi-turn Guidance
Aug 23, 2024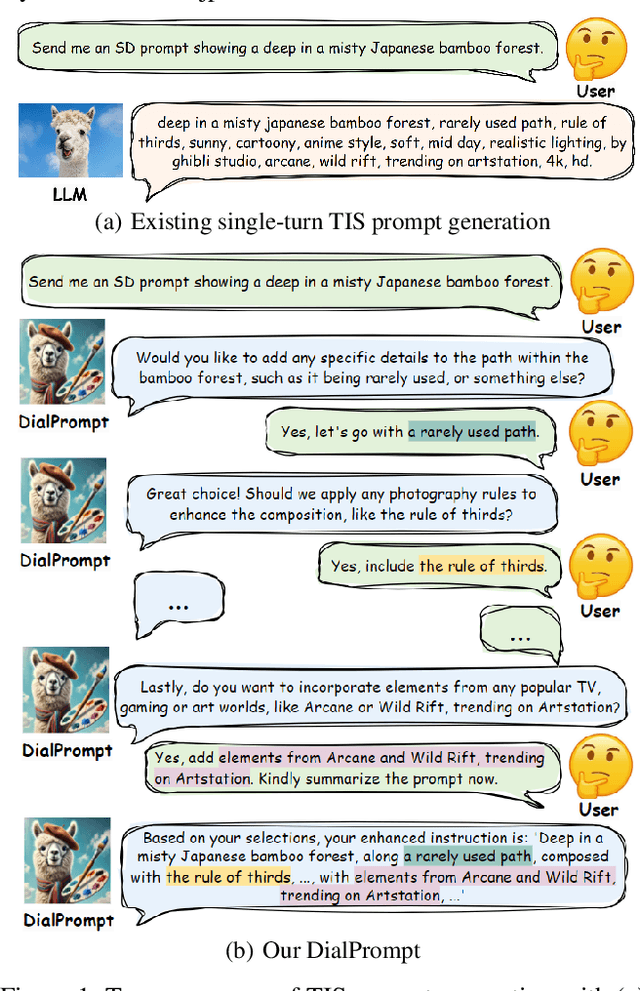
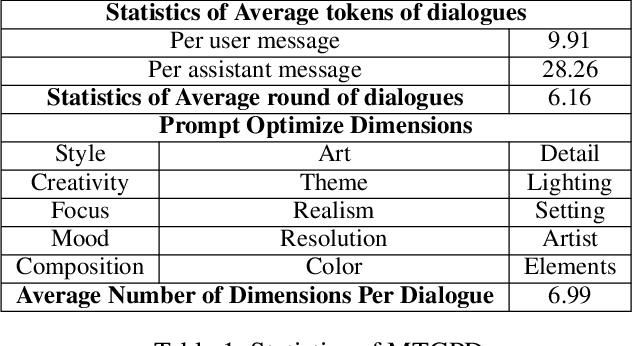
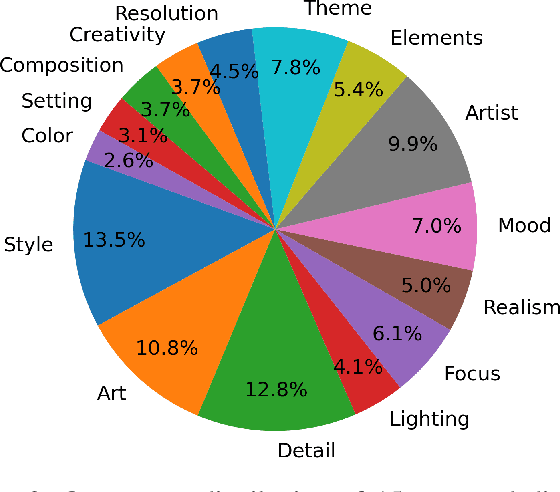
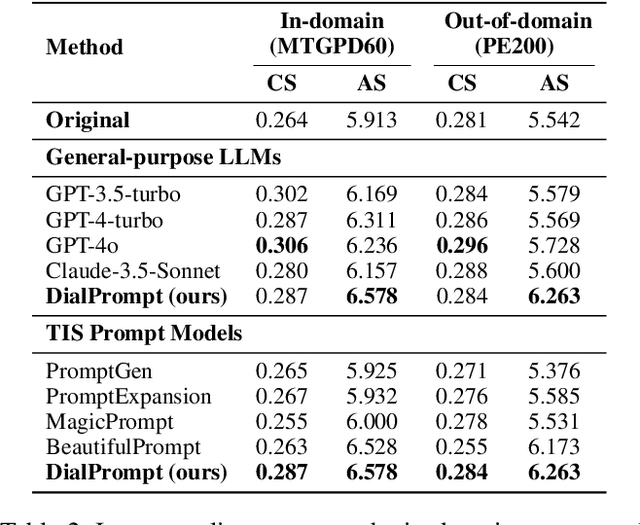
The emergence of text-to-image synthesis (TIS) models has significantly influenced digital image creation by producing high-quality visuals from written descriptions. Yet these models heavily rely on the quality and specificity of textual prompts, posing a challenge for novice users who may not be familiar with TIS-model-preferred prompt writing. Existing solutions relieve this via automatic model-preferred prompt generation from user queries. However, this single-turn manner suffers from limited user-centricity in terms of result interpretability and user interactivity. To address these issues, we propose DialPrompt, a multi-turn dialogue-based TIS prompt generation model that emphasises user-centricity. DialPrompt is designed to follow a multi-turn guidance workflow, where in each round of dialogue the model queries user with their preferences on possible optimization dimensions before generating the final TIS prompt. To achieve this, we mined 15 essential dimensions for high-quality prompts from advanced users and curated a multi-turn dataset. Through training on this dataset, DialPrompt can improve interpretability by allowing users to understand the correlation between specific phrases and image attributes. Additionally, it enables greater user control and engagement in the prompt generation process, leading to more personalized and visually satisfying outputs. Experiments indicate that DialPrompt achieves a competitive result in the quality of synthesized images, outperforming existing prompt engineering approaches by 5.7%. Furthermore, in our user evaluation, DialPrompt outperforms existing approaches by 46.5% in user-centricity score and is rated 7.9/10 by 19 human reviewers.
Full-Body Motion Reconstruction with Sparse Sensing from Graph Perspective
Jan 22, 2024Estimating 3D full-body pose from sparse sensor data is a pivotal technique employed for the reconstruction of realistic human motions in Augmented Reality and Virtual Reality. However, translating sparse sensor signals into comprehensive human motion remains a challenge since the sparsely distributed sensors in common VR systems fail to capture the motion of full human body. In this paper, we use well-designed Body Pose Graph (BPG) to represent the human body and translate the challenge into a prediction problem of graph missing nodes. Then, we propose a novel full-body motion reconstruction framework based on BPG. To establish BPG, nodes are initially endowed with features extracted from sparse sensor signals. Features from identifiable joint nodes across diverse sensors are amalgamated and processed from both temporal and spatial perspectives. Temporal dynamics are captured using the Temporal Pyramid Structure, while spatial relations in joint movements inform the spatial attributes. The resultant features serve as the foundational elements of the BPG nodes. To further refine the BPG, node features are updated through a graph neural network that incorporates edge reflecting varying joint relations. Our method's effectiveness is evidenced by the attained state-of-the-art performance, particularly in lower body motion, outperforming other baseline methods. Additionally, an ablation study validates the efficacy of each module in our proposed framework.
Graph based Environment Representation for Vision-and-Language Navigation in Continuous Environments
Jan 11, 2023



Vision-and-Language Navigation in Continuous Environments (VLN-CE) is a navigation task that requires an agent to follow a language instruction in a realistic environment. The understanding of environments is a crucial part of the VLN-CE task, but existing methods are relatively simple and direct in understanding the environment, without delving into the relationship between language instructions and visual environments. Therefore, we propose a new environment representation in order to solve the above problems. First, we propose an Environment Representation Graph (ERG) through object detection to express the environment in semantic level. This operation enhances the relationship between language and environment. Then, the relational representations of object-object, object-agent in ERG are learned through GCN, so as to obtain a continuous expression about ERG. Sequentially, we combine the ERG expression with object label embeddings to obtain the environment representation. Finally, a new cross-modal attention navigation framework is proposed, incorporating our environment representation and a special loss function dedicated to training ERG. Experimental result shows that our method achieves satisfactory performance in terms of success rate on VLN-CE tasks. Further analysis explains that our method attains better cross-modal matching and strong generalization ability.
Few-shot Domain Adaptation for IMU Denoising
Jan 05, 2022
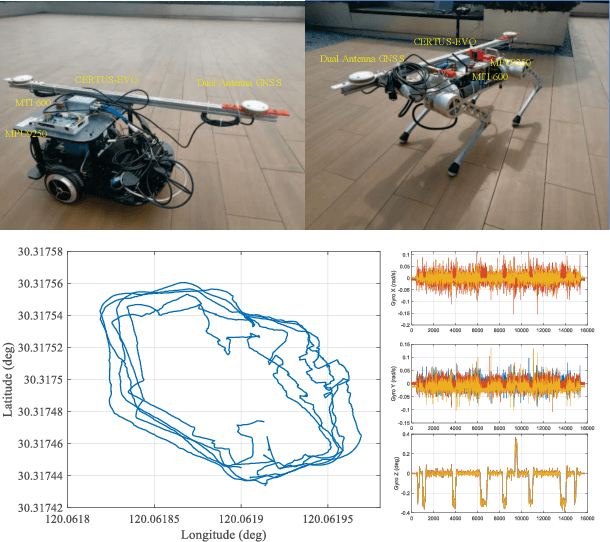
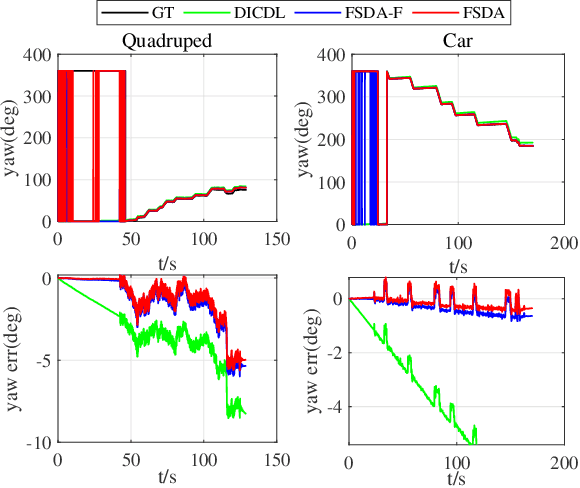
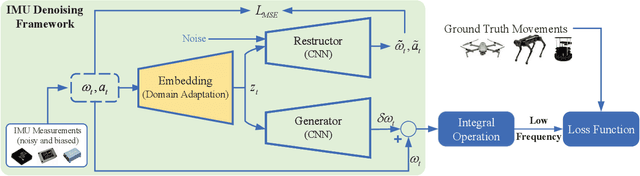
Different application scenarios will cause IMU to exhibit different error characteristics which will cause trouble to robot application. However, most data processing methods need to be designed for specific scenario. To solve this problem, we propose a few-shot domain adaptation method. In this work, a domain adaptation framework is considered for denoising the IMU, a reconstitution loss is designed to improve domain adaptability. In addition, in order to further improve the adaptability in the case of limited data, a few-shot training strategy is adopted. In the experiment, we quantify our method on two datasets (EuRoC and TUM-VI) and two real robots (car and quadruped robot) with three different precision IMUs. According to the experimental results, the adaptability of our framework is verified by t-SNE. In orientation results, our proposed method shows the great denoising performance.