 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartGalaxy: A Dataset for Infographic Chart Understanding and Generation
May 24, 2025Infographic charts are a powerful medium for communicating abstract data by combining visual elements (e.g., charts, images) with textual information. However, their visual and structural richness poses challenges for large vision-language models (LVLMs), which are typically trained on plain charts. To bridge this gap, we introduce ChartGalaxy, a million-scale dataset designed to advance the understanding and generation of infographic charts. The dataset is constructed through an inductive process that identifies 75 chart types, 330 chart variations, and 68 layout templates from real infographic charts and uses them to create synthetic ones programmatically. We showcase the utility of this dataset through: 1) improving infographic chart understanding via fine-tuning, 2) benchmarking code generation for infographic charts, and 3) enabling example-based infographic chart generation. By capturing the visual and structural complexity of real design, ChartGalaxy provides a useful resource for enhancing multimodal reasoning and generation in LVLMs.
What Do You Want? User-centric Prompt Generation for Text-to-image Synthesis via Multi-turn Guidance
Aug 23, 2024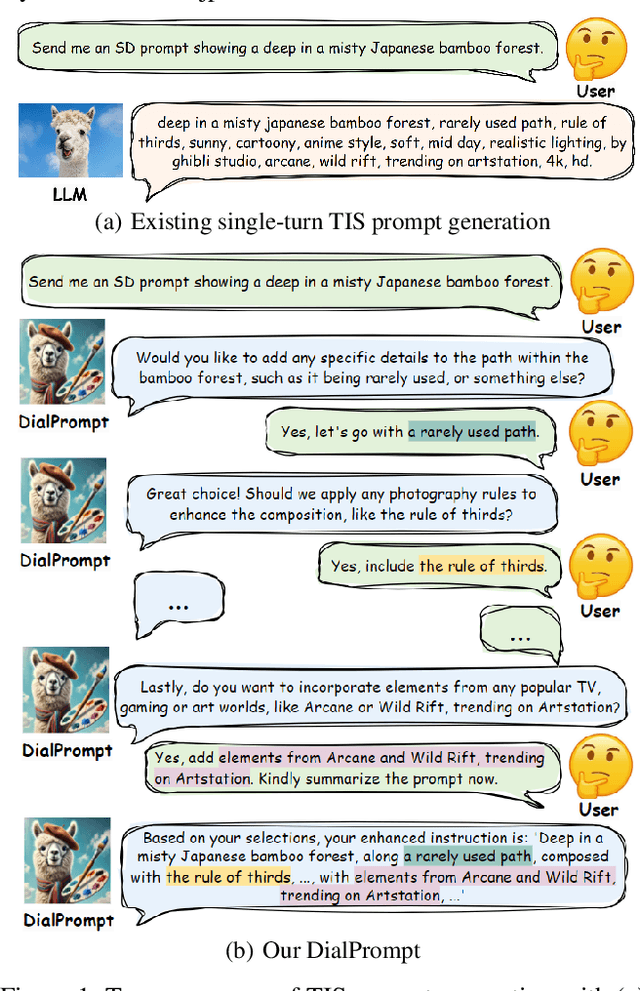
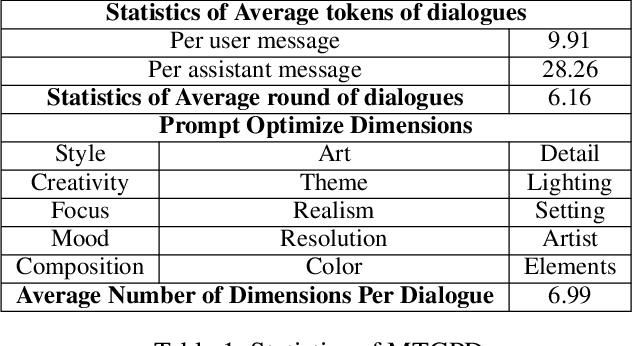
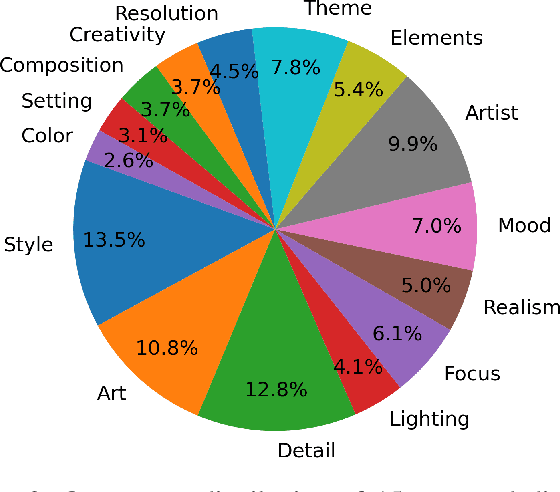
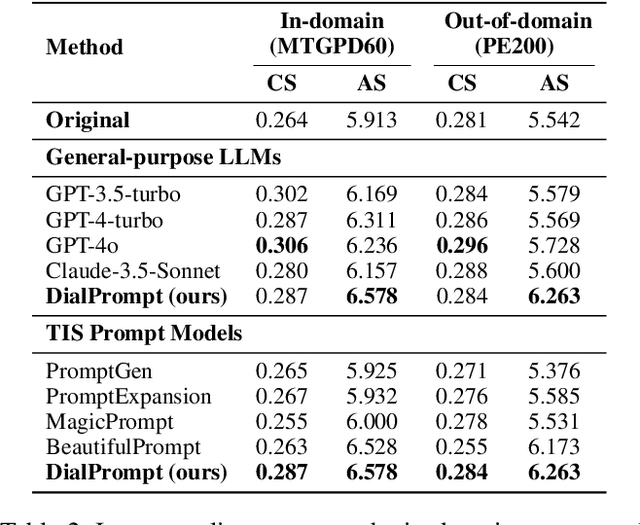
The emergence of text-to-image synthesis (TIS) models has significantly influenced digital image creation by producing high-quality visuals from written descriptions. Yet these models heavily rely on the quality and specificity of textual prompts, posing a challenge for novice users who may not be familiar with TIS-model-preferred prompt writing. Existing solutions relieve this via automatic model-preferred prompt generation from user queries. However, this single-turn manner suffers from limited user-centricity in terms of result interpretability and user interactivity. To address these issues, we propose DialPrompt, a multi-turn dialogue-based TIS prompt generation model that emphasises user-centricity. DialPrompt is designed to follow a multi-turn guidance workflow, where in each round of dialogue the model queries user with their preferences on possible optimization dimensions before generating the final TIS prompt. To achieve this, we mined 15 essential dimensions for high-quality prompts from advanced users and curated a multi-turn dataset. Through training on this dataset, DialPrompt can improve interpretability by allowing users to understand the correlation between specific phrases and image attributes. Additionally, it enables greater user control and engagement in the prompt generation process, leading to more personalized and visually satisfying outputs. Experiments indicate that DialPrompt achieves a competitive result in the quality of synthesized images, outperforming existing prompt engineering approaches by 5.7%. Furthermore, in our user evaluation, DialPrompt outperforms existing approaches by 46.5% in user-centricity score and is rated 7.9/10 by 19 human reviewers.
Revised Progressive-Hedging-Algorithm Based Two-layer Solution Scheme for Bayesian Reinforcement Learning
Jun 21, 2019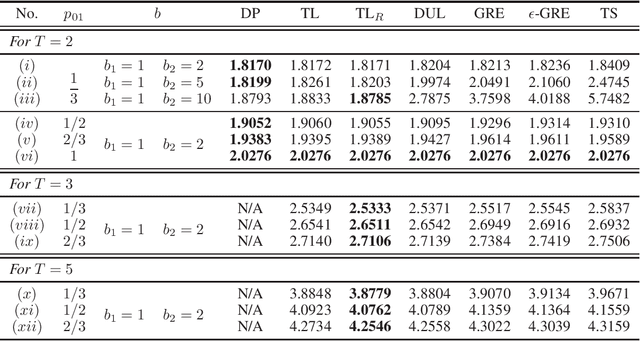
Stochastic control with both inherent random system noise and lack of knowledge on system parameters constitutes the core and fundamental topic in reinforcement learning (RL), especially under non-episodic situations where online learning is much more demanding. This challenge has been notably addressed in Bayesian RL recently where some approximation techniques have been developed to find suboptimal policies. While existing approaches mainly focus on approximating the value function, or on involving Thompson sampling, we propose a novel two-layer solution scheme in this paper to approximate the optimal policy directly, by combining the time-decomposition based dynamic programming (DP) at the lower layer and the scenario-decomposition based revised progressive hedging algorithm (PHA) at the upper layer, for a type of Bayesian RL problem. The key feature of our approach is to separate reducible system uncertainty from irreducible one at two different layers, thus decomposing and conquering. We demonstrate our solution framework more especially via the linear-quadratic-Gaussian problem with unknown gain, which, although seemingly simple, has been a notorious subject over more than half century in dual control.