 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
LogPurge: Log Data Purification for Anomaly Detection via Rule-Enhanced Filtering
Nov 18, 2025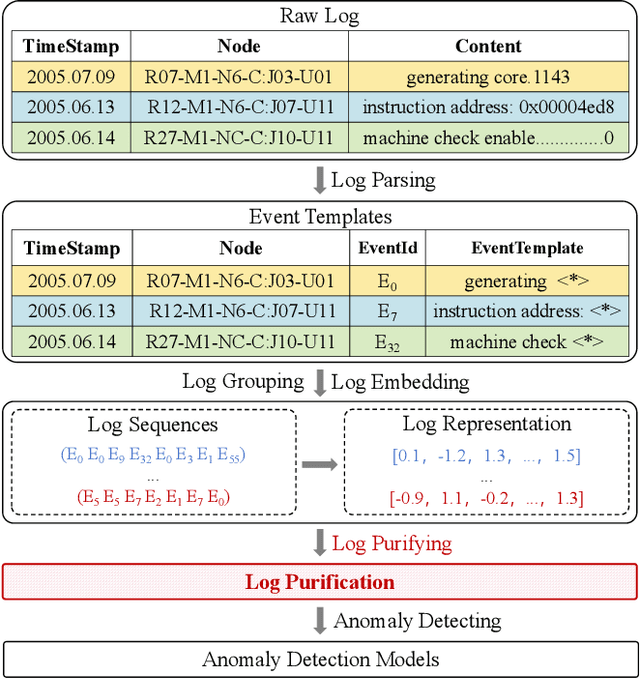
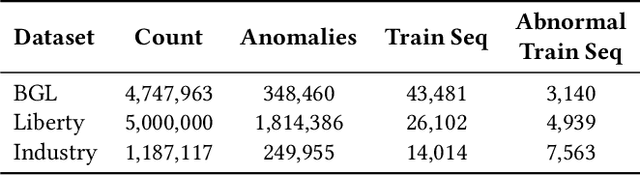
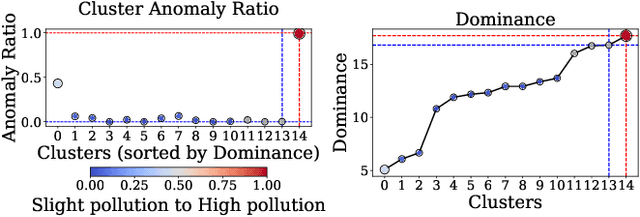
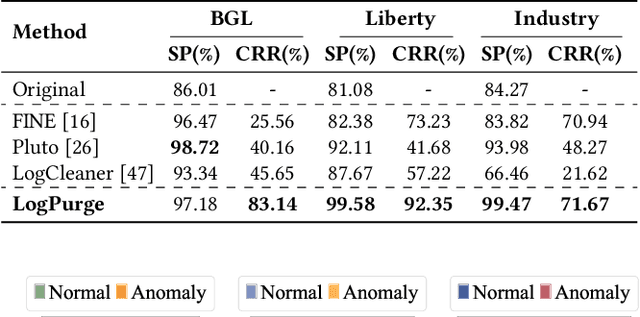
Log anomaly detection, which is critical for identifying system failures and preempting security breaches, detects irregular patterns within large volumes of log data, and impacts domains such as service reliability, performance optimization, and database log analysis. Modern log anomaly detection methods rely on training deep learning models on clean, anomaly-free log sequences. However, obtaining such clean log data requires costly and tedious human labeling, and existing automatic cleaning methods fail to fully integrate the specific characteristics and actual semantics of logs in their purification process. In this paper, we propose a cost-aware, rule-enhanced purification framework, LogPurge, that automatically selects a sufficient subset of normal log sequences from contamination log sequences to train a anomaly detection model. Our approach involves a two-stage filtering algorithm: In the first stage, we use a large language model (LLM) to remove clustered anomalous patterns and enhance system rules to improve LLM's understanding of system logs; in the second stage, we utilize a divide-and-conquer strategy that decomposes the remaining contaminated regions into smaller subproblems, allowing each to be effectively purified through the first stage procedure. Our experiments, conducted on two public datasets and one industrial dataset, show that our method significantly removes an average of 98.74% of anomalies while retaining 82.39% of normal samples. Compared to the latest unsupervised log sample selection algorithms, our method achieves F-1 score improvements of 35.7% and 84.11% on the public datasets, and an impressive 149.72% F-1 improvement on the private dataset, demonstrating the effectiveness of our approach.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
ELSPR: Evaluator LLM Training Data Self-Purification on Non-Transitive Preferences via Tournament Graph Reconstruction
May 23, 2025Large language models (LLMs) are widely used as evaluators for open-ended tasks, while previous research has emphasized biases in LLM evaluations, the issue of non-transitivity in pairwise comparisons remains unresolved: non-transitive preferences for pairwise comparisons, where evaluators prefer A over B, B over C, but C over A. Our results suggest that low-quality training data may reduce the transitivity of preferences generated by the Evaluator LLM. To address this, We propose a graph-theoretic framework to analyze and mitigate this problem by modeling pairwise preferences as tournament graphs. We quantify non-transitivity and introduce directed graph structural entropy to measure the overall clarity of preferences. Our analysis reveals significant non-transitivity in advanced Evaluator LLMs (with Qwen2.5-Max exhibiting 67.96%), as well as high entropy values (0.8095 for Qwen2.5-Max), reflecting low overall clarity of preferences. To address this issue, we designed a filtering strategy, ELSPR, to eliminate preference data that induces non-transitivity, retaining only consistent and transitive preference data for model fine-tuning. Experiments demonstrate that models fine-tuned with filtered data reduce non-transitivity by 13.78% (from 64.28% to 50.50%), decrease structural entropy by 0.0879 (from 0.8113 to 0.7234), and align more closely with human evaluators (human agreement rate improves by 0.6% and Spearman correlation increases by 0.01).
MIDB: Multilingual Instruction Data Booster for Enhancing Multilingual Instruction Synthesis
May 23, 2025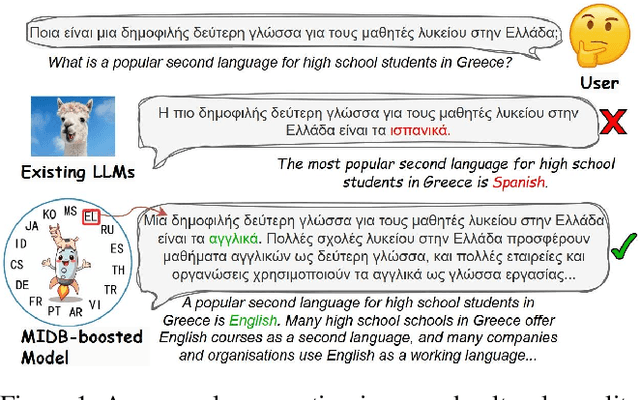
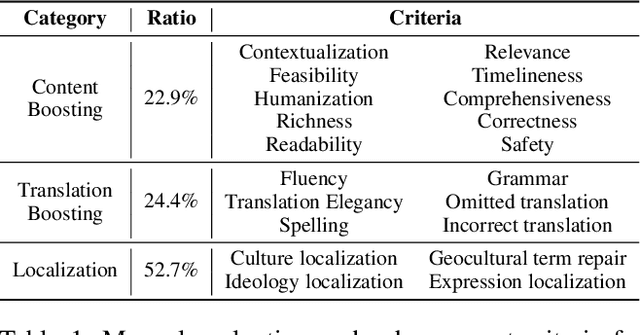
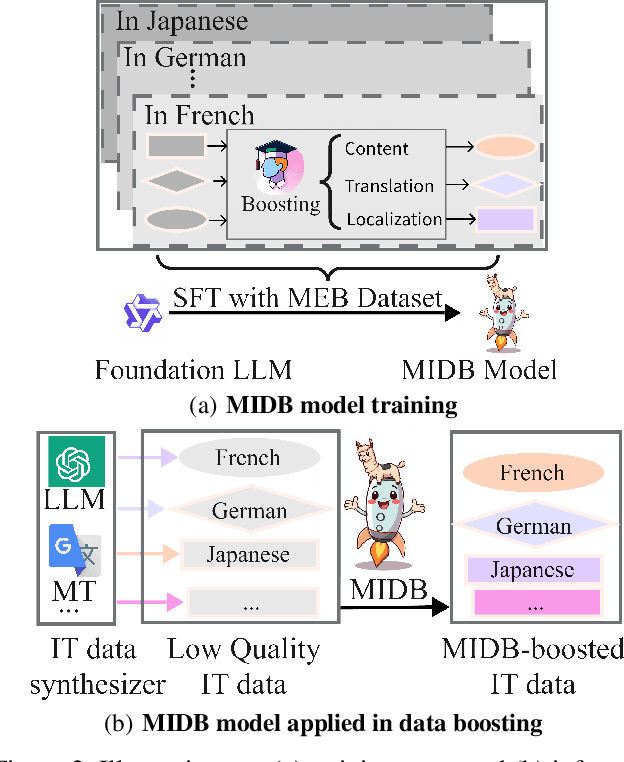
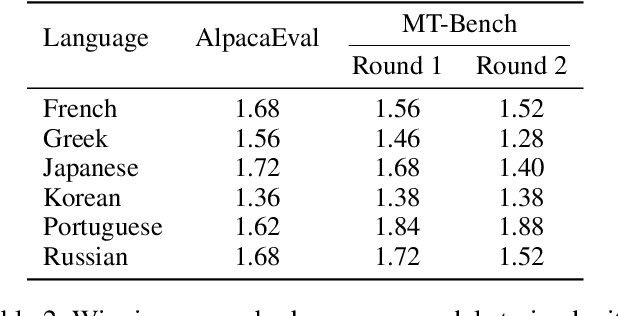
Despite doubts on data quality, instruction synthesis has been widely applied into instruction tuning (IT) of LLMs as an economic and rapid alternative. Recent endeavors focus on improving data quality for synthesized instruction pairs in English and have facilitated IT of English-centric LLMs. However, data quality issues in multilingual synthesized instruction pairs are even more severe, since the common synthesizing practice is to translate English synthesized data into other languages using machine translation (MT). Besides the known content errors in these English synthesized data, multilingual synthesized instruction data are further exposed to defects introduced by MT and face insufficient localization of the target languages. In this paper, we propose MIDB, a Multilingual Instruction Data Booster to automatically address the quality issues in multilingual synthesized data. MIDB is trained on around 36.8k revision examples across 16 languages by human linguistic experts, thereby can boost the low-quality data by addressing content errors and MT defects, and improving localization in these synthesized data. Both automatic and human evaluation indicate that not only MIDB steadily improved instruction data quality in 16 languages, but also the instruction-following and cultural-understanding abilities of multilingual LLMs fine-tuned on MIDB-boosted data were significantly enhanced.
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning
Feb 27, 2025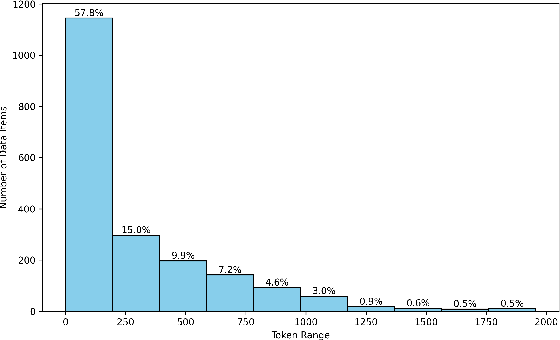

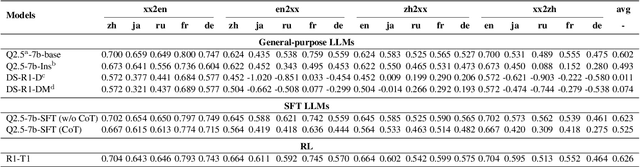
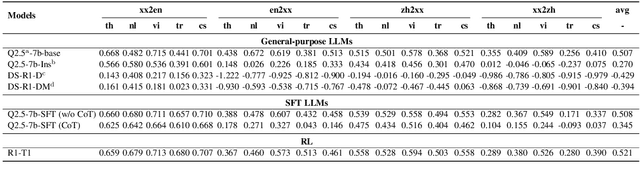
Despite recent breakthroughs in reasoning-enhanced large language models (LLMs) like DeepSeek-R1, incorporating inference-time reasoning into machine translation (MT), where human translators naturally employ structured, multi-layered reasoning chain-of-thoughts (CoTs), is yet underexplored. Existing methods either design a fixed CoT tailored for a specific MT sub-task (e.g., literature translation), or rely on synthesizing CoTs unaligned with humans and supervised fine-tuning (SFT) prone to catastrophic forgetting, limiting their adaptability to diverse translation scenarios. This paper introduces R1-Translator (R1-T1), a novel framework to achieve inference-time reasoning for general MT via reinforcement learning (RL) with human-aligned CoTs comprising six common patterns. Our approach pioneers three innovations: (1) extending reasoning-based translation beyond MT sub-tasks to six languages and diverse tasks (e.g., legal/medical domain adaptation, idiom resolution); (2) formalizing six expert-curated CoT templates that mirror hybrid human strategies like context-aware paraphrasing and back translation; and (3) enabling self-evolving CoT discovery and anti-forgetting adaptation through RL with KL-constrained rewards. Experimental results indicate a steady translation performance improvement in 21 languages and 80 translation directions on Flores-101 test set, especially on the 15 languages unseen from training, with its general multilingual abilities preserved compared with plain SFT.
Adapting Large Language Models to Log Analysis with Interpretable Domain Knowledge
Dec 02, 2024The increasing complexity of computer systems necessitates innovative approaches to fault and error management, going beyond traditional manual log analysis. While existing solutions using large language models (LLMs) show promise, they are limited by a gap between natural and domain-specific languages, which restricts their effectiveness in real-world applications. Our approach addresses these limitations by integrating interpretable domain knowledge into open-source LLMs through continual pre-training (CPT), enhancing performance on log tasks while retaining natural language processing capabilities. We created a comprehensive dataset, NLPLog, with over 250,000 question-answer pairs to facilitate this integration. Our model, SuperLog, trained with this dataset, achieves the best performance across four log analysis tasks, surpassing the second-best model by an average of 12.01%. Our contributions include a novel CPT paradigm that significantly improves model performance, the development of SuperLog with state-of-the-art results, and the release of a large-scale dataset to support further research in this domain.
PERFT: Parameter-Efficient Routed Fine-Tuning for Mixture-of-Expert Model
Nov 12, 2024
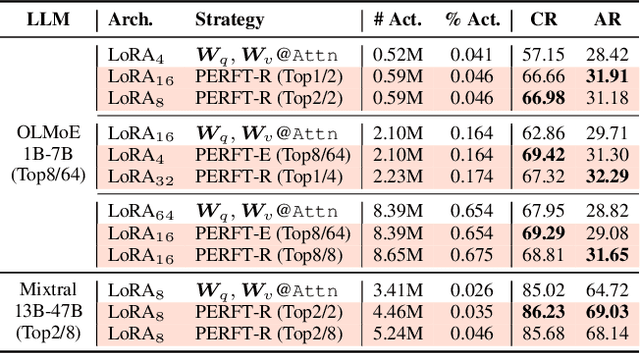


The Mixture-of-Experts (MoE) paradigm has emerged as a powerful approach for scaling transformers with improved resource utilization. However, efficiently fine-tuning MoE models remains largely underexplored. Inspired by recent works on Parameter-Efficient Fine-Tuning (PEFT), we present a unified framework for integrating PEFT modules directly into the MoE mechanism. Aligning with the core principles and architecture of MoE, our framework encompasses a set of design dimensions including various functional and composition strategies. By combining design choices within our framework, we introduce Parameter-Efficient Routed Fine-Tuning (PERFT) as a flexible and scalable family of PEFT strategies tailored for MoE models. Extensive experiments on adapting OLMoE-1B-7B and Mixtral-8$\times$7B for commonsense and arithmetic reasoning tasks demonstrate the effectiveness, scalability, and intriguing dynamics of PERFT. Additionally, we provide empirical findings for each specific design choice to facilitate better application of MoE and PEFT.
LogLM: From Task-based to Instruction-based Automated Log Analysis
Oct 12, 2024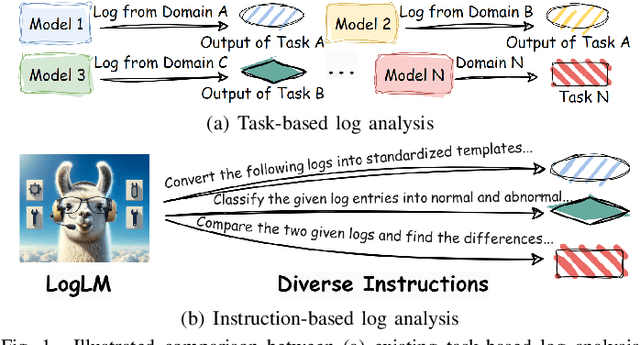
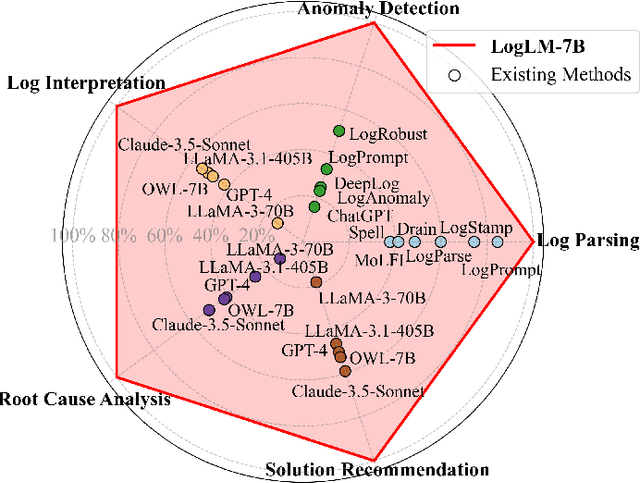

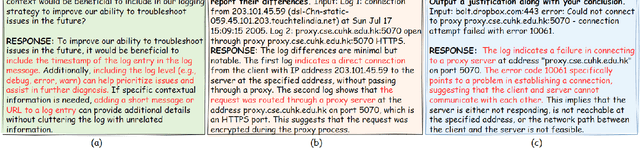
Automatic log analysis is essential for the efficient Operation and Maintenance (O&M) of software systems, providing critical insights into system behaviors. However, existing approaches mostly treat log analysis as training a model to perform an isolated task, using task-specific log-label pairs. These task-based approaches are inflexible in generalizing to complex scenarios, depend on task-specific training data, and cost significantly when deploying multiple models. In this paper, we propose an instruction-based training approach that transforms log-label pairs from multiple tasks and domains into a unified format of instruction-response pairs. Our trained model, LogLM, can follow complex user instructions and generalize better across different tasks, thereby increasing flexibility and reducing the dependence on task-specific training data. By integrating major log analysis tasks into a single model, our approach also relieves model deployment burden. Experimentally, LogLM outperforms existing approaches across five log analysis capabilities, and exhibits strong generalization abilities on complex instructions and unseen tasks.