 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaKase-8B: Legal Case Retrieval via Knowledge and Reasoning Representations with LLMs
Oct 30, 2025Legal case retrieval (LCR) is a cornerstone of real-world legal decision making, as it enables practitioners to identify precedents for a given query case. Existing approaches mainly rely on traditional lexical models and pretrained language models to encode the texts of legal cases. Yet there are rich information in the relations among different legal entities as well as the crucial reasoning process that uncovers how legal facts and legal issues can lead to judicial decisions. Such relational reasoning process reflects the distinctive characteristics of each case that can distinguish one from another, mirroring the real-world judicial process. Naturally, incorporating such information into the precise case embedding could further enhance the accuracy of case retrieval. In this paper, a novel ReaKase-8B framework is proposed to leverage extracted legal facts, legal issues, legal relation triplets and legal reasoning for effective legal case retrieval. ReaKase-8B designs an in-context legal case representation learning paradigm with a fine-tuned large language model. Extensive experiments on two benchmark datasets from COLIEE 2022 and COLIEE 2023 demonstrate that our knowledge and reasoning augmented embeddings substantially improve retrieval performance over baseline models, highlighting the potential of integrating legal reasoning into legal case retrieval systems. The code has been released on https://github.com/yanran-tang/ReaKase-8B.
Does Homophily Help in Robust Test-time Node Classification?
Oct 25, 2025Homophily, the tendency of nodes from the same class to connect, is a fundamental property of real-world graphs, underpinning structural and semantic patterns in domains such as citation networks and social networks. Existing methods exploit homophily through designing homophily-aware GNN architectures or graph structure learning strategies, yet they primarily focus on GNN learning with training graphs. However, in real-world scenarios, test graphs often suffer from data quality issues and distribution shifts, such as domain shifts across users from different regions in social networks and temporal evolution shifts in citation network graphs collected over varying time periods. These factors significantly compromise the pre-trained model's robustness, resulting in degraded test-time performance. With empirical observations and theoretical analysis, we reveal that transforming the test graph structure by increasing homophily in homophilic graphs or decreasing it in heterophilic graphs can significantly improve the robustness and performance of pre-trained GNNs on node classifications, without requiring model training or update. Motivated by these insights, a novel test-time graph structural transformation method grounded in homophily, named GrapHoST, is proposed. Specifically, a homophily predictor is developed to discriminate test edges, facilitating adaptive test-time graph structural transformation by the confidence of predicted homophily scores. Extensive experiments on nine benchmark datasets under a range of test-time data quality issues demonstrate that GrapHoST consistently achieves state-of-the-art performance, with improvements of up to 10.92%. Our code has been released at https://github.com/YanJiangJerry/GrapHoST.
MARCO: A Cooperative Knowledge Transfer Framework for Personalized Cross-domain Recommendations
Oct 06, 2025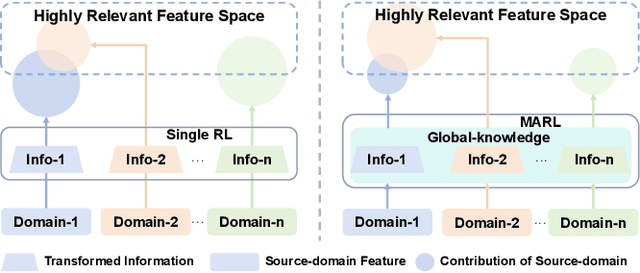
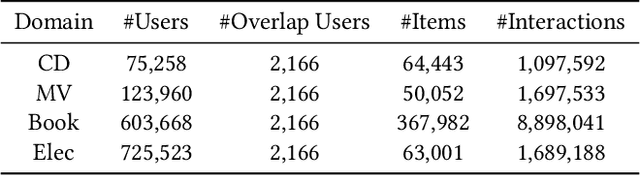
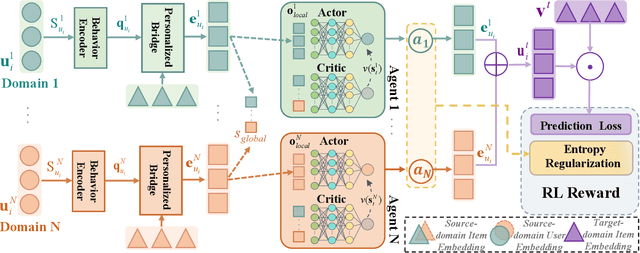
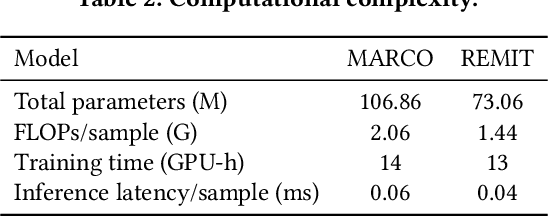
Recommender systems frequently encounter data sparsity issues, particularly when addressing cold-start scenarios involving new users or items. Multi-source cross-domain recommendation (CDR) addresses these challenges by transferring valuable knowledge from multiple source domains to enhance recommendations in a target domain. However, existing reinforcement learning (RL)-based CDR methods typically rely on a single-agent framework, leading to negative transfer issues caused by inconsistent domain contributions and inherent distributional discrepancies among source domains. To overcome these limitations, MARCO, a Multi-Agent Reinforcement Learning-based Cross-Domain recommendation framework, is proposed. It leverages cooperative multi-agent reinforcement learning, where each agent is dedicated to estimating the contribution from an individual source domain, effectively managing credit assignment and mitigating negative transfer. In addition, an entropy-based action diversity penalty is introduced to enhance policy expressiveness and stabilize training by encouraging diverse agents' joint actions. Extensive experiments across four benchmark datasets demonstrate MARCO's superior performance over state-of-the-art methods, highlighting its robustness and strong generalization capabilities. The code is at https://github.com/xiewilliams/MARCO.
ALSA: Anchors in Logit Space for Out-of-Distribution Accuracy Estimation
Aug 27, 2025Estimating model accuracy on unseen, unlabeled datasets is crucial for real-world machine learning applications, especially under distribution shifts that can degrade performance. Existing methods often rely on predicted class probabilities (softmax scores) or data similarity metrics. While softmax-based approaches benefit from representing predictions on the standard simplex, compressing logits into probabilities leads to information loss. Meanwhile, similarity-based methods can be computationally expensive and domain-specific, limiting their broader applicability. In this paper, we introduce ALSA (Anchors in Logit Space for Accuracy estimation), a novel framework that preserves richer information by operating directly in the logit space. Building on theoretical insights and empirical observations, we demonstrate that the aggregation and distribution of logits exhibit a strong correlation with the predictive performance of the model. To exploit this property, ALSA employs an anchor-based modeling strategy: multiple learnable anchors are initialized in logit space, each assigned an influence function that captures subtle variations in the logits. This allows ALSA to provide robust and accurate performance estimates across a wide range of distribution shifts. Extensive experiments on vision, language, and graph benchmarks demonstrate ALSA's superiority over both softmax- and similarity-based baselines. Notably, ALSA's robustness under significant distribution shifts highlights its potential as a practical tool for reliable model evaluation.
Text Meets Topology: Rethinking Out-of-distribution Detection in Text-Rich Networks
Aug 25, 2025Out-of-distribution (OOD) detection remains challenging in text-rich networks, where textual features intertwine with topological structures. Existing methods primarily address label shifts or rudimentary domain-based splits, overlooking the intricate textual-structural diversity. For example, in social networks, where users represent nodes with textual features (name, bio) while edges indicate friendship status, OOD may stem from the distinct language patterns between bot and normal users. To address this gap, we introduce the TextTopoOOD framework for evaluating detection across diverse OOD scenarios: (1) attribute-level shifts via text augmentations and embedding perturbations; (2) structural shifts through edge rewiring and semantic connections; (3) thematically-guided label shifts; and (4) domain-based divisions. Furthermore, we propose TNT-OOD to model the complex interplay between Text aNd Topology using: 1) a novel cross-attention module to fuse local structure into node-level text representations, and 2) a HyperNetwork to generate node-specific transformation parameters. This aligns topological and semantic features of ID nodes, enhancing ID/OOD distinction across structural and textual shifts. Experiments on 11 datasets across four OOD scenarios demonstrate the nuanced challenge of TextTopoOOD for evaluating OOD detection in text-rich networks.
UQLegalAI@COLIEE2025: Advancing Legal Case Retrieval with Large Language Models and Graph Neural Networks
May 27, 2025Legal case retrieval plays a pivotal role in the legal domain by facilitating the efficient identification of relevant cases, supporting legal professionals and researchers to propose legal arguments and make informed decision-making. To improve retrieval accuracy, the Competition on Legal Information Extraction and Entailment (COLIEE) is held annually, offering updated benchmark datasets for evaluation. This paper presents a detailed description of CaseLink, the method employed by UQLegalAI, the second highest team in Task 1 of COLIEE 2025. The CaseLink model utilises inductive graph learning and Global Case Graphs to capture the intrinsic case connectivity to improve the accuracy of legal case retrieval. Specifically, a large language model specialized in text embedding is employed to transform legal texts into embeddings, which serve as the feature representations of the nodes in the constructed case graph. A new contrastive objective, incorporating a regularization on the degree of case nodes, is proposed to leverage the information within the case reference relationship for model optimization. The main codebase used in our method is based on an open-sourced repo of CaseLink: https://github.com/yanran-tang/CaseLink.
DARLR: Dual-Agent Offline Reinforcement Learning for Recommender Systems with Dynamic Reward
May 12, 2025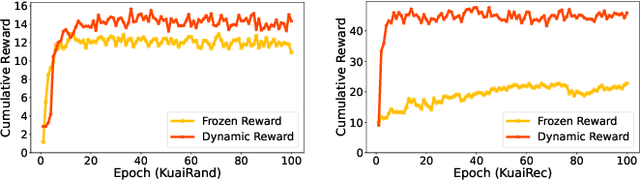
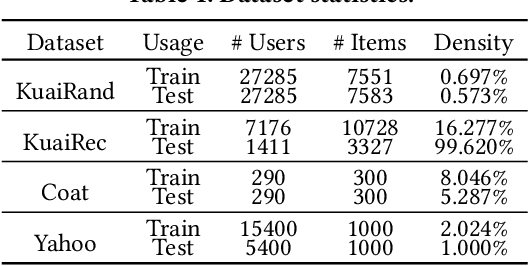
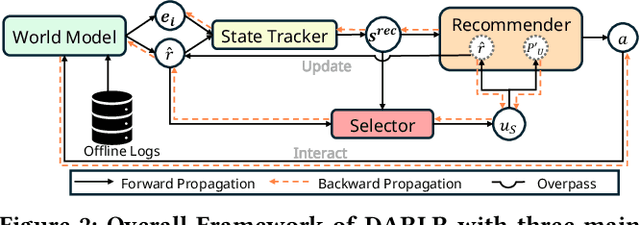
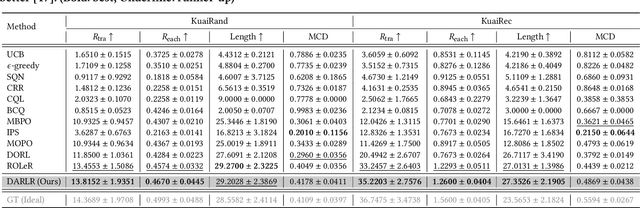
Model-based offline reinforcement learning (RL) has emerged as a promising approach for recommender systems, enabling effective policy learning by interacting with frozen world models. However, the reward functions in these world models, trained on sparse offline logs, often suffer from inaccuracies. Specifically, existing methods face two major limitations in addressing this challenge: (1) deterministic use of reward functions as static look-up tables, which propagates inaccuracies during policy learning, and (2) static uncertainty designs that fail to effectively capture decision risks and mitigate the impact of these inaccuracies. In this work, a dual-agent framework, DARLR, is proposed to dynamically update world models to enhance recommendation policies. To achieve this, a \textbf{\textit{selector}} is introduced to identify reference users by balancing similarity and diversity so that the \textbf{\textit{recommender}} can aggregate information from these users and iteratively refine reward estimations for dynamic reward shaping. Further, the statistical features of the selected users guide the dynamic adaptation of an uncertainty penalty to better align with evolving recommendation requirements. Extensive experiments on four benchmark datasets demonstrate the superior performance of DARLR, validating its effectiveness. The code is available at https://github.com/ArronDZhang/DARLR.
GOLD: Graph Out-of-Distribution Detection via Implicit Adversarial Latent Generation
Feb 09, 2025Despite graph neural networks' (GNNs) great success in modelling graph-structured data, out-of-distribution (OOD) test instances still pose a great challenge for current GNNs. One of the most effective techniques to detect OOD nodes is to expose the detector model with an additional OOD node-set, yet the extra OOD instances are often difficult to obtain in practice. Recent methods for image data address this problem using OOD data synthesis, typically relying on pre-trained generative models like Stable Diffusion. However, these approaches require vast amounts of additional data, as well as one-for-all pre-trained generative models, which are not available for graph data. Therefore, we propose the GOLD framework for graph OOD detection, an implicit adversarial learning pipeline with synthetic OOD exposure without pre-trained models. The implicit adversarial training process employs a novel alternating optimisation framework by training: (1) a latent generative model to regularly imitate the in-distribution (ID) embeddings from an evolving GNN, and (2) a GNN encoder and an OOD detector to accurately classify ID data while increasing the energy divergence between the ID embeddings and the generative model's synthetic embeddings. This novel approach implicitly transforms the synthetic embeddings into pseudo-OOD instances relative to the ID data, effectively simulating exposure to OOD scenarios without auxiliary data. Extensive OOD detection experiments are conducted on five benchmark graph datasets, verifying the superior performance of GOLD without using real OOD data compared with the state-of-the-art OOD exposure and non-exposure baselines.
Contrastive Learning for Implicit Social Factors in Social Media Popularity Prediction
Oct 12, 2024On social media sharing platforms, some posts are inherently destined for popularity. Therefore, understanding the reasons behind this phenomenon and predicting popularity before post publication holds significant practical value. The previous work predominantly focuses on enhancing post content extraction for better prediction results. However, certain factors introduced by social platforms also impact post popularity, which has not been extensively studied. For instance, users are more likely to engage with posts from individuals they follow, potentially influencing the popularity of these posts. We term these factors, unrelated to the explicit attractiveness of content, as implicit social factors. Through the analysis of users' post browsing behavior (also validated in public datasets), we propose three implicit social factors related to popularity, including content relevance, user influence similarity, and user identity. To model the proposed social factors, we introduce three supervised contrastive learning tasks. For different task objectives and data types, we assign them to different encoders and control their gradient flows to achieve joint optimization. We also design corresponding sampling and augmentation algorithms to improve the effectiveness of contrastive learning. Extensive experiments on the Social Media Popularity Dataset validate the superiority of our proposed method and also confirm the important role of implicit social factors in popularity prediction. We open source the code at https://github.com/Daisy-zzz/PPCL.git.
EMIT- Event-Based Masked Auto Encoding for Irregular Time Series
Sep 25, 2024Irregular time series, where data points are recorded at uneven intervals, are prevalent in healthcare settings, such as emergency wards where vital signs and laboratory results are captured at varying times. This variability, which reflects critical fluctuations in patient health, is essential for informed clinical decision-making. Existing self-supervised learning research on irregular time series often relies on generic pretext tasks like forecasting, which may not fully utilise the signal provided by irregular time series. There is a significant need for specialised pretext tasks designed for the characteristics of irregular time series to enhance model performance and robustness, especially in scenarios with limited data availability. This paper proposes a novel pretraining framework, EMIT, an event-based masking for irregular time series. EMIT focuses on masking-based reconstruction in the latent space, selecting masking points based on the rate of change in the data. This method preserves the natural variability and timing of measurements while enhancing the model's ability to process irregular intervals without losing essential information. Extensive experiments on the MIMIC-III and PhysioNet Challenge datasets demonstrate the superior performance of our event-based masking strategy. The code has been released at https://github.com/hrishi-ds/EMIT .