 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of CHIP 2025 Shared Task 2: Discharge Medication Recommendation for Metabolic Diseases Based on Chinese Electronic Health Records
Nov 09, 2025Discharge medication recommendation plays a critical role in ensuring treatment continuity, preventing readmission, and improving long-term management for patients with chronic metabolic diseases. This paper present an overview of the CHIP 2025 Shared Task 2 competition, which aimed to develop state-of-the-art approaches for automatically recommending appro-priate discharge medications using real-world Chinese EHR data. For this task, we constructed CDrugRed, a high-quality dataset consisting of 5,894 de-identified hospitalization records from 3,190 patients in China. This task is challenging due to multi-label nature of medication recommendation, het-erogeneous clinical text, and patient-specific variability in treatment plans. A total of 526 teams registered, with 167 and 95 teams submitting valid results to the Phase A and Phase B leaderboards, respectively. The top-performing team achieved the highest overall performance on the final test set, with a Jaccard score of 0.5102, F1 score of 0.6267, demonstrating the potential of advanced large language model (LLM)-based ensemble systems. These re-sults highlight both the promise and remaining challenges of applying LLMs to medication recommendation in Chinese EHRs. The post-evaluation phase remains open at https://tianchi.aliyun.com/competition/entrance/532411/.
Does Homophily Help in Robust Test-time Node Classification?
Oct 25, 2025Homophily, the tendency of nodes from the same class to connect, is a fundamental property of real-world graphs, underpinning structural and semantic patterns in domains such as citation networks and social networks. Existing methods exploit homophily through designing homophily-aware GNN architectures or graph structure learning strategies, yet they primarily focus on GNN learning with training graphs. However, in real-world scenarios, test graphs often suffer from data quality issues and distribution shifts, such as domain shifts across users from different regions in social networks and temporal evolution shifts in citation network graphs collected over varying time periods. These factors significantly compromise the pre-trained model's robustness, resulting in degraded test-time performance. With empirical observations and theoretical analysis, we reveal that transforming the test graph structure by increasing homophily in homophilic graphs or decreasing it in heterophilic graphs can significantly improve the robustness and performance of pre-trained GNNs on node classifications, without requiring model training or update. Motivated by these insights, a novel test-time graph structural transformation method grounded in homophily, named GrapHoST, is proposed. Specifically, a homophily predictor is developed to discriminate test edges, facilitating adaptive test-time graph structural transformation by the confidence of predicted homophily scores. Extensive experiments on nine benchmark datasets under a range of test-time data quality issues demonstrate that GrapHoST consistently achieves state-of-the-art performance, with improvements of up to 10.92%. Our code has been released at https://github.com/YanJiangJerry/GrapHoST.
Hyperspectral Mamba for Hyperspectral Object Tracking
Sep 10, 2025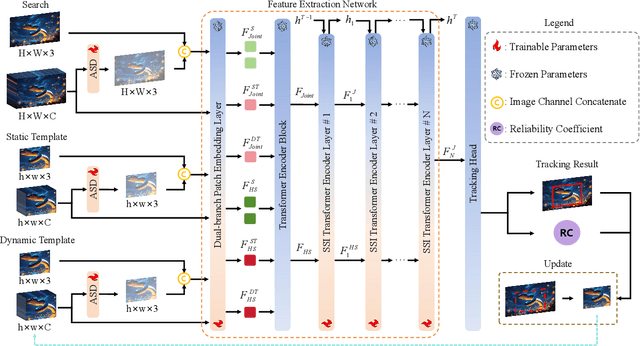
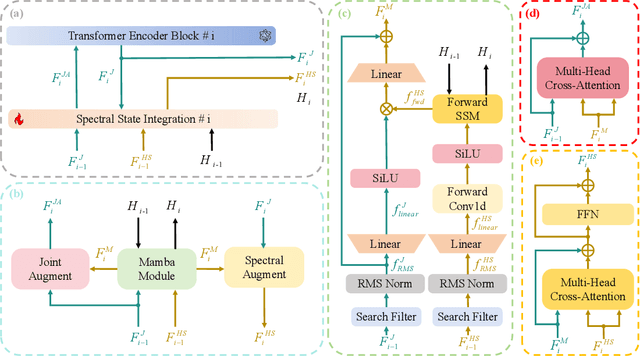
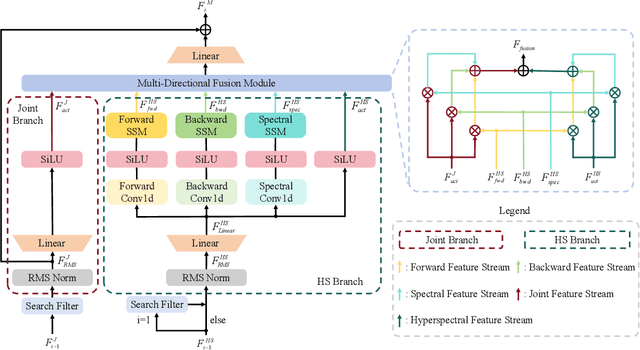
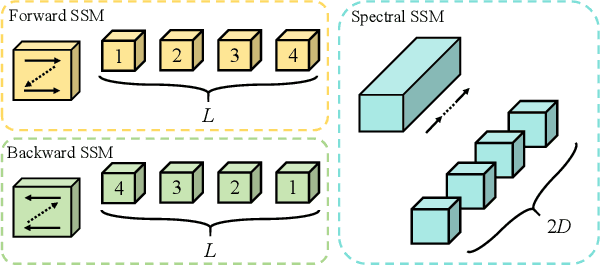
Hyperspectral object tracking holds great promise due to the rich spectral information and fine-grained material distinctions in hyperspectral images, which are beneficial in challenging scenarios. While existing hyperspectral trackers have made progress by either transforming hyperspectral data into false-color images or incorporating modality fusion strategies, they often fail to capture the intrinsic spectral information, temporal dependencies, and cross-depth interactions. To address these limitations, a new hyperspectral object tracking network equipped with Mamba (HyMamba), is proposed. It unifies spectral, cross-depth, and temporal modeling through state space modules (SSMs). The core of HyMamba lies in the Spectral State Integration (SSI) module, which enables progressive refinement and propagation of spectral features with cross-depth and temporal spectral information. Embedded within each SSI, the Hyperspectral Mamba (HSM) module is introduced to learn spatial and spectral information synchronously via three directional scanning SSMs. Based on SSI and HSM, HyMamba constructs joint features from false-color and hyperspectral inputs, and enhances them through interaction with original spectral features extracted from raw hyperspectral images. Extensive experiments conducted on seven benchmark datasets demonstrate that HyMamba achieves state-of-the-art performance. For instance, it achieves 73.0\% of the AUC score and 96.3\% of the DP@20 score on the HOTC2020 dataset. The code will be released at https://github.com/lgao001/HyMamba.
NaviAgent: Bilevel Planning on Tool Dependency Graphs for Function Calling
Jun 24, 2025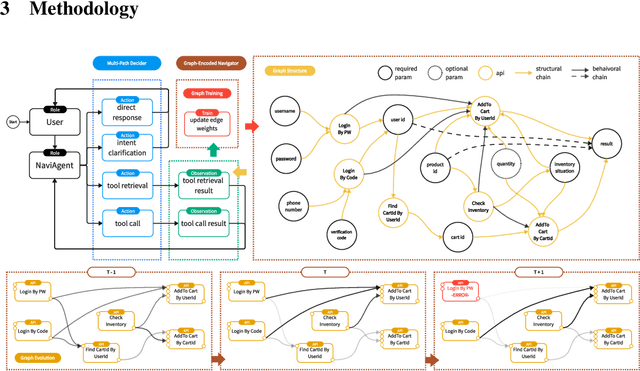
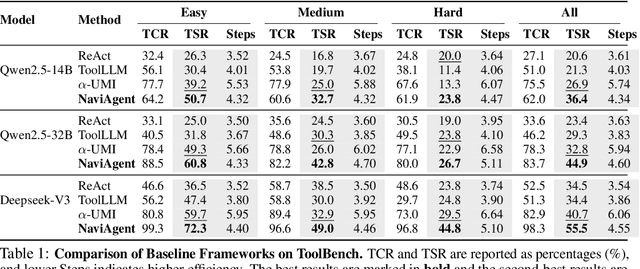

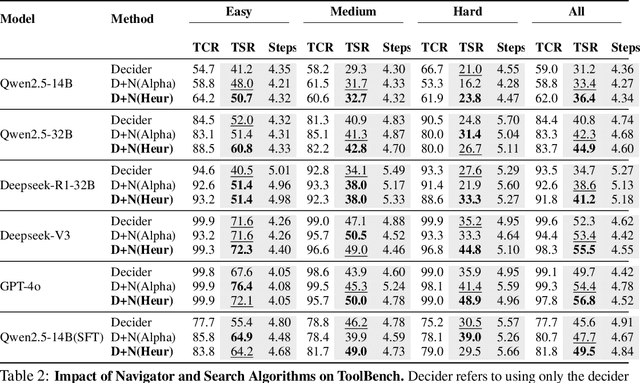
LLMs' reliance on static knowledge and fragile tool invocation severely hinders the orchestration of complex, heterogeneous toolchains, particularly at large scales. Existing methods typically use rigid single-path execution, resulting in poor error recovery and exponentially growing search spaces. We introduce NaviAgent, a graph-navigated bilevel planning architecture for robust function calling, comprising a Multi-Path Decider and Graph-Encoded Navigator. As an LLM-powered agent, the Multi-Path Decider defines a four-dimensional decision space and continuously perceives environmental states, dynamically selecting the optimal action to fully cover all tool invocation scenarios. The Graph-Encoded Navigator constructs a Tool Dependency Heterogeneous Graph (TDHG), where node embeddings explicitly fuse API schema structure with historical invocation behavior. It also integrates a novel heuristic search strategy that guides the Decider toward efficient and highly successful toolchains, even for unseen tool combinations. Experiments show that NaviAgent consistently achieves the highest task success rate (TSR) across all foundation models and task complexities, outperforming the average baselines (ReAct, ToolLLM, {\alpha}-UMI) by 13.5%, 16.4%, and 19.0% on Qwen2.5-14B, Qwen2.5-32B, and Deepseek-V3, respectively. Its execution steps are typically within one step of the most efficient baseline, ensuring a strong balance between quality and efficiency. Notably, a fine-tuned Qwen2.5-14B model achieves a TSR of 49.5%, surpassing the much larger 32B model (44.9%) under our architecture. Incorporating the Graph-Encoded Navigator further boosts TSR by an average of 2.4 points, with gains up over 9 points on complex tasks for larger models (Deepseek-V3 and GPT-4o), highlighting its essential role in toolchain orchestration.
OTPTO: Joint Product Selection and Inventory Optimization in Fresh E-commerce Front-End Warehouses
May 29, 2025In China's competitive fresh e-commerce market, optimizing operational strategies, especially inventory management in front-end warehouses, is key to enhance customer satisfaction and to gain a competitive edge. Front-end warehouses are placed in residential areas to ensure the timely delivery of fresh goods and are usually in small size. This brings the challenge of deciding which goods to stock and in what quantities, taking into account capacity constraints. To address this issue, traditional predict-then-optimize (PTO) methods that predict sales and then decide on inventory often don't align prediction with inventory goals, as well as fail to prioritize consumer satisfaction. This paper proposes a multi-task Optimize-then-Predict-then-Optimize (OTPTO) approach that jointly optimizes product selection and inventory management, aiming to increase consumer satisfaction by maximizing the full order fulfillment rate. Our method employs a 0-1 mixed integer programming model OM1 to determine historically optimal inventory levels, and then uses a product selection model PM1 and the stocking model PM2 for prediction. The combined results are further refined through a post-processing algorithm OM2. Experimental results from JD.com's 7Fresh platform demonstrate the robustness and significant advantages of our OTPTO method. Compared to the PTO approach, our OTPTO method substantially enhances the full order fulfillment rate by 4.34% (a relative increase of 7.05%) and narrows the gap to the optimal full order fulfillment rate by 5.27%. These findings substantiate the efficacy of the OTPTO method in managing inventory at front-end warehouses of fresh e-commerce platforms and provide valuable insights for future research in this domain.
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
Hyperspectral Adapter for Object Tracking based on Hyperspectral Video
Mar 28, 2025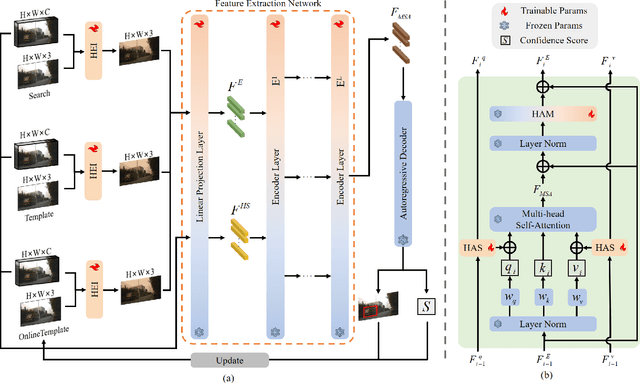
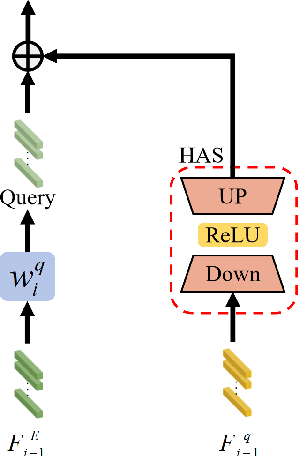
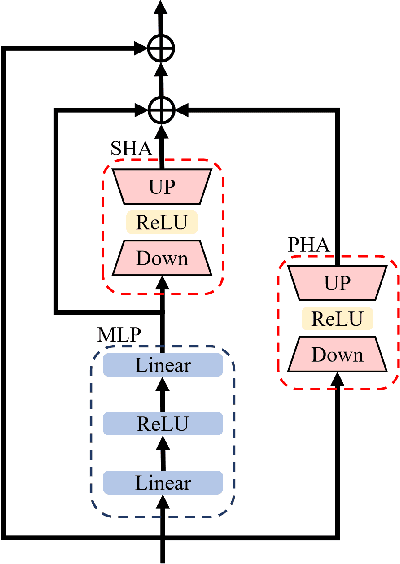
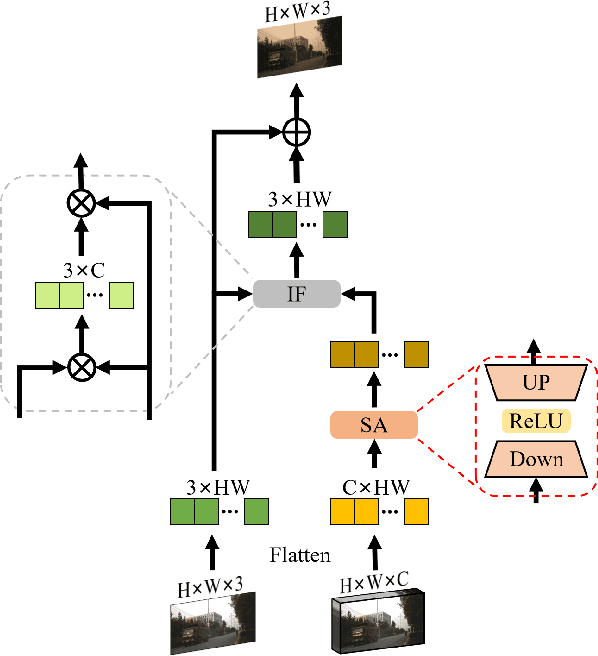
Object tracking based on hyperspectral video attracts increasing attention to the rich material and motion information in the hyperspectral videos. The prevailing hyperspectral methods adapt pretrained RGB-based object tracking networks for hyperspectral tasks by fine-tuning the entire network on hyperspectral datasets, which achieves impressive results in challenging scenarios. However, the performance of hyperspectral trackers is limited by the loss of spectral information during the transformation, and fine-tuning the entire pretrained network is inefficient for practical applications. To address the issues, a new hyperspectral object tracking method, hyperspectral adapter for tracking (HyA-T), is proposed in this work. The hyperspectral adapter for the self-attention (HAS) and the hyperspectral adapter for the multilayer perceptron (HAM) are proposed to generate the adaption information and to transfer the multi-head self-attention (MSA) module and the multilayer perceptron (MLP) in pretrained network for the hyperspectral object tracking task by augmenting the adaption information into the calculation of the MSA and MLP. Additionally, the hyperspectral enhancement of input (HEI) is proposed to augment the original spectral information into the input of the tracking network. The proposed methods extract spectral information directly from the hyperspectral images, which prevent the loss of the spectral information. Moreover, only the parameters in the proposed methods are fine-tuned, which is more efficient than the existing methods. Extensive experiments were conducted on four datasets with various spectral bands, verifing the effectiveness of the proposed methods. The HyA-T achieves state-of-the-art performance on all the datasets.
From Laboratory to Real World: A New Benchmark Towards Privacy-Preserved Visible-Infrared Person Re-Identification
Mar 15, 2025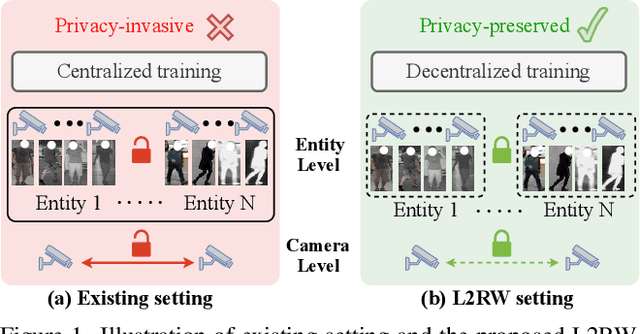
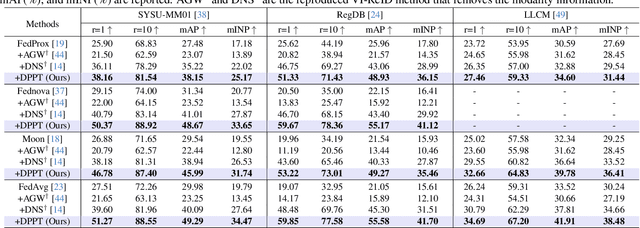
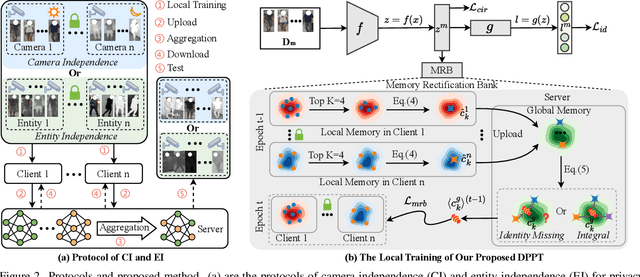
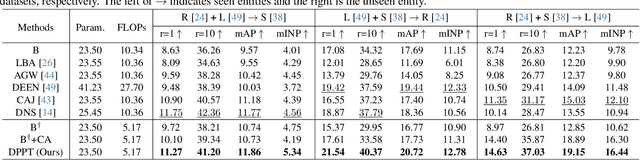
Aiming to match pedestrian images captured under varying lighting conditions, visible-infrared person re-identification (VI-ReID) has drawn intensive research attention and achieved promising results. However, in real-world surveillance contexts, data is distributed across multiple devices/entities, raising privacy and ownership concerns that make existing centralized training impractical for VI-ReID. To tackle these challenges, we propose L2RW, a benchmark that brings VI-ReID closer to real-world applications. The rationale of L2RW is that integrating decentralized training into VI-ReID can address privacy concerns in scenarios with limited data-sharing regulation. Specifically, we design protocols and corresponding algorithms for different privacy sensitivity levels. In our new benchmark, we ensure the model training is done in the conditions that: 1) data from each camera remains completely isolated, or 2) different data entities (e.g., data controllers of a certain region) can selectively share the data. In this way, we simulate scenarios with strict privacy constraints which is closer to real-world conditions. Intensive experiments with various server-side federated algorithms are conducted, showing the feasibility of decentralized VI-ReID training. Notably, when evaluated in unseen domains (i.e., new data entities), our L2RW, trained with isolated data (privacy-preserved), achieves performance comparable to SOTAs trained with shared data (privacy-unrestricted). We hope this work offers a novel research entry for deploying VI-ReID that fits real-world scenarios and can benefit the community.
Zero-Shot Hashing Based on Reconstruction With Part Alignment
Mar 10, 2025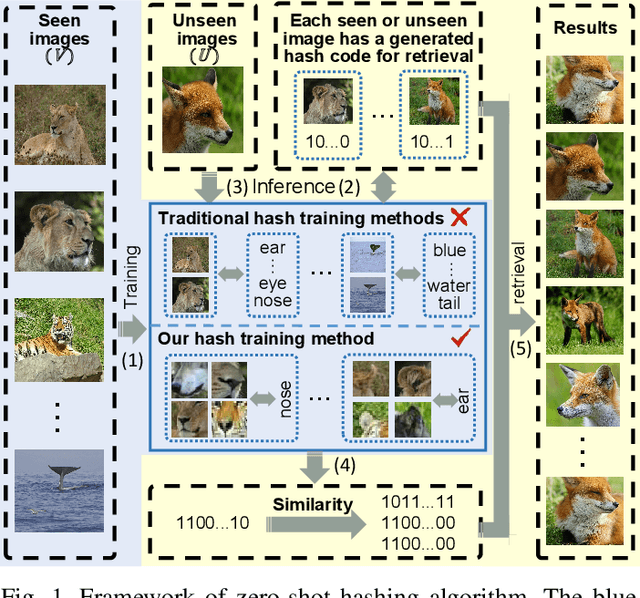
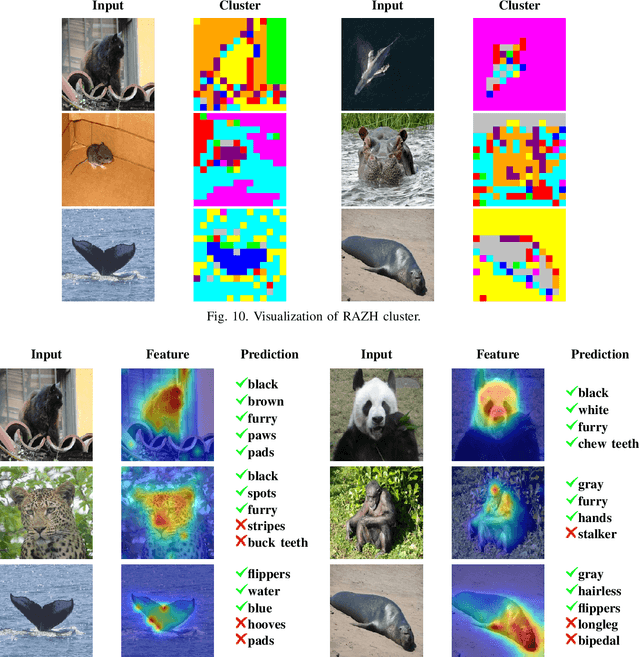
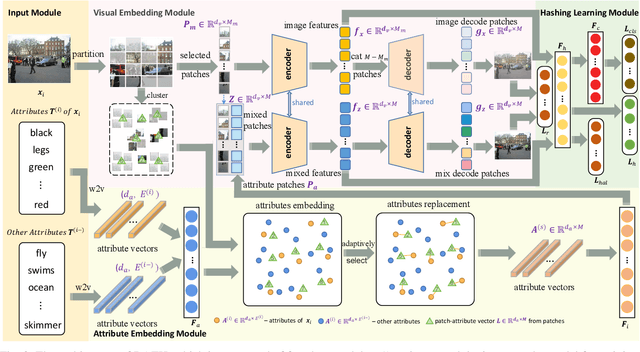
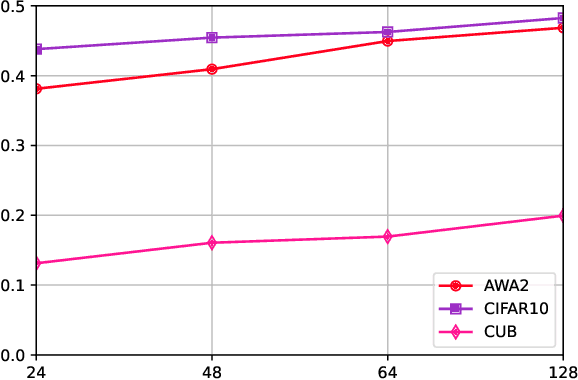
Hashing algorithms have been widely used in large-scale image retrieval tasks, especially for seen class data. Zero-shot hashing algorithms have been proposed to handle unseen class data. The key technique in these algorithms involves learning features from seen classes and transferring them to unseen classes, that is, aligning the feature embeddings between the seen and unseen classes. Most existing zero-shot hashing algorithms use the shared attributes between the two classes of interest to complete alignment tasks. However, the attributes are always described for a whole image, even though they represent specific parts of the image. Hence, these methods ignore the importance of aligning attributes with the corresponding image parts, which explicitly introduces noise and reduces the accuracy achieved when aligning the features of seen and unseen classes. To address this problem, we propose a new zero-shot hashing method called RAZH. We first use a clustering algorithm to group similar patches to image parts for attribute matching and then replace the image parts with the corresponding attribute vectors, gradually aligning each part with its nearest attribute. Extensive evaluation results demonstrate the superiority of the RAZH method over several state-of-the-art methods.
Predictive Response Optimization: Using Reinforcement Learning to Fight Online Social Network Abuse
Feb 24, 2025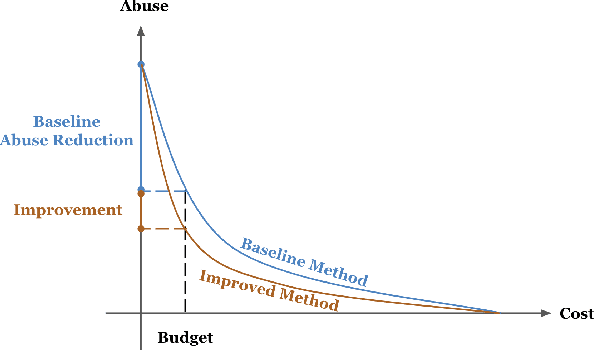

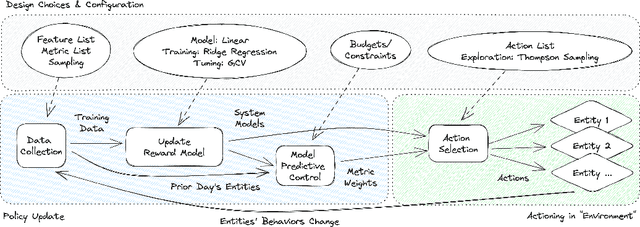
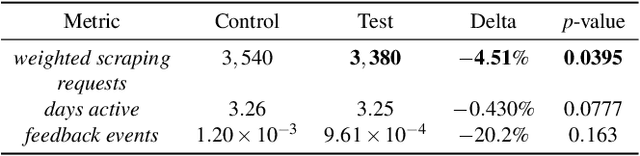
Detecting phishing, spam, fake accounts, data scraping, and other malicious activity in online social networks (OSNs) is a problem that has been studied for well over a decade, with a number of important results. Nearly all existing works on abuse detection have as their goal producing the best possible binary classifier; i.e., one that labels unseen examples as "benign" or "malicious" with high precision and recall. However, no prior published work considers what comes next: what does the service actually do after it detects abuse? In this paper, we argue that detection as described in previous work is not the goal of those who are fighting OSN abuse. Rather, we believe the goal to be selecting actions (e.g., ban the user, block the request, show a CAPTCHA, or "collect more evidence") that optimize a tradeoff between harm caused by abuse and impact on benign users. With this framing, we see that enlarging the set of possible actions allows us to move the Pareto frontier in a way that is unattainable by simply tuning the threshold of a binary classifier. To demonstrate the potential of our approach, we present Predictive Response Optimization (PRO), a system based on reinforcement learning that utilizes available contextual information to predict future abuse and user-experience metrics conditioned on each possible action, and select actions that optimize a multi-dimensional tradeoff between abuse/harm and impact on user experience. We deployed versions of PRO targeted at stopping automated activity on Instagram and Facebook. In both cases our experiments showed that PRO outperforms a baseline classification system, reducing abuse volume by 59% and 4.5% (respectively) with no negative impact to users. We also present several case studies that demonstrate how PRO can quickly and automatically adapt to changes in business constraints, system behavior, and/or adversarial tactics.