 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Multimodal Fusion with Pre-Trained Model Features in Affective Behaviour Analysis In-the-wild
Mar 22, 2024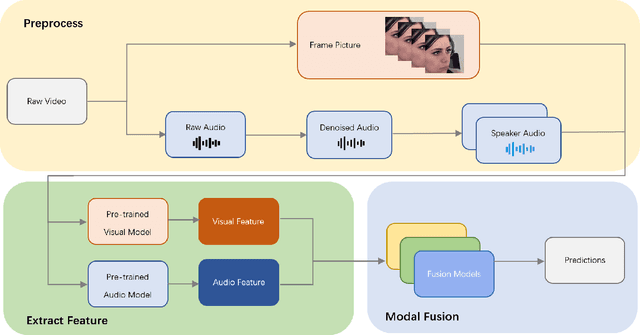
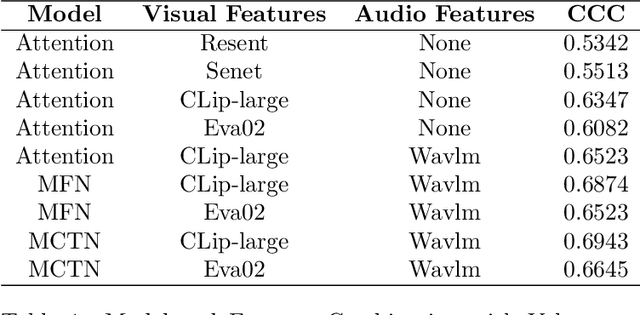

Multimodal fusion is a significant method for most multimodal tasks. With the recent surge in the number of large pre-trained models, combining both multimodal fusion methods and pre-trained model features can achieve outstanding performance in many multimodal tasks. In this paper, we present our approach, which leverages both advantages for addressing the task of Expression (Expr) Recognition and Valence-Arousal (VA) Estimation. We evaluate the Aff-Wild2 database using pre-trained models, then extract the final hidden layers of the models as features. Following preprocessing and interpolation or convolution to align the extracted features, different models are employed for modal fusion. Our code is available at GitHub - FulgenceWen/ABAW6th.
HiCMAE: Hierarchical Contrastive Masked Autoencoder for Self-Supervised Audio-Visual Emotion Recognition
Jan 11, 2024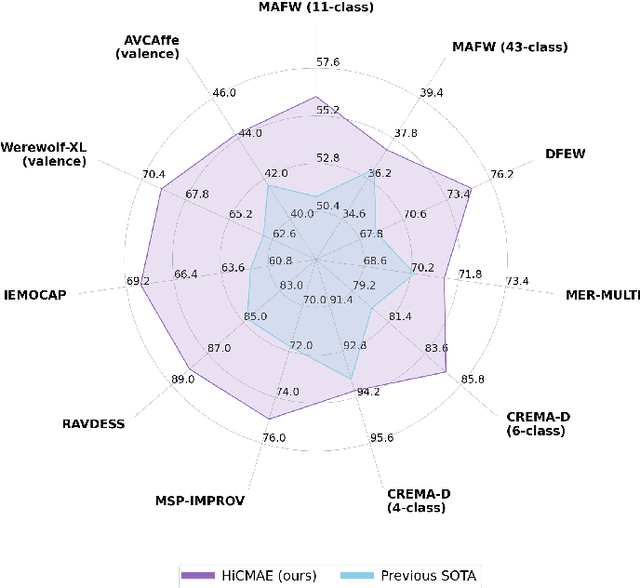
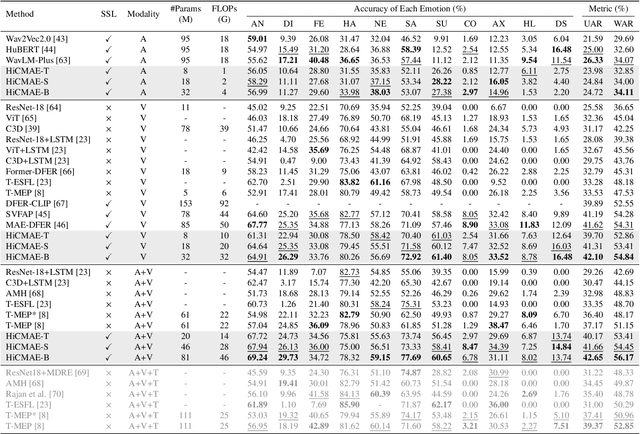
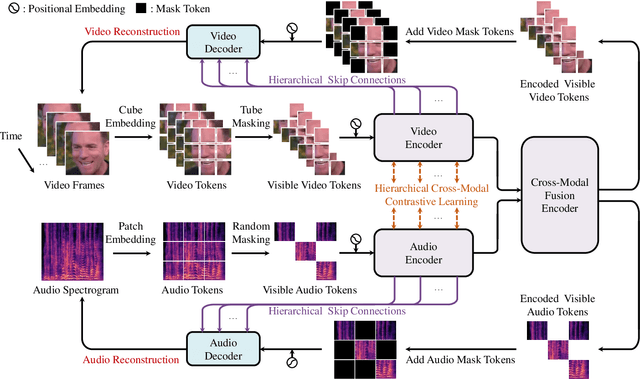
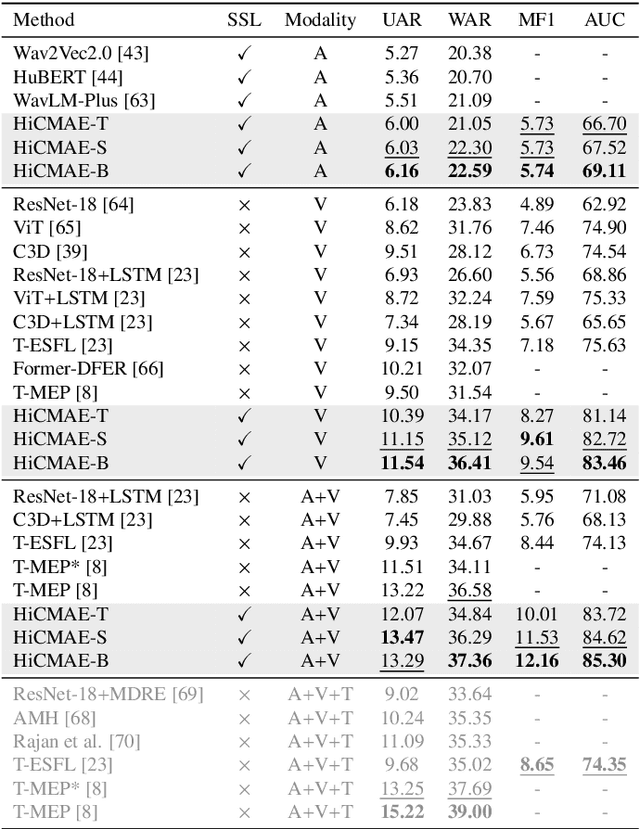
Audio-Visual Emotion Recognition (AVER) has garnered increasing attention in recent years for its critical role in creating emotion-ware intelligent machines. Previous efforts in this area are dominated by the supervised learning paradigm. Despite significant progress, supervised learning is meeting its bottleneck due to the longstanding data scarcity issue in AVER. Motivated by recent advances in self-supervised learning, we propose Hierarchical Contrastive Masked Autoencoder (HiCMAE), a novel self-supervised framework that leverages large-scale self-supervised pre-training on vast unlabeled audio-visual data to promote the advancement of AVER. Following prior arts in self-supervised audio-visual representation learning, HiCMAE adopts two primary forms of self-supervision for pre-training, namely masked data modeling and contrastive learning. Unlike them which focus exclusively on top-layer representations while neglecting explicit guidance of intermediate layers, HiCMAE develops a three-pronged strategy to foster hierarchical audio-visual feature learning and improve the overall quality of learned representations. To verify the effectiveness of HiCMAE, we conduct extensive experiments on 9 datasets covering both categorical and dimensional AVER tasks. Experimental results show that our method significantly outperforms state-of-the-art supervised and self-supervised audio-visual methods, which indicates that HiCMAE is a powerful audio-visual emotion representation learner. Codes and models will be publicly available at https://github.com/sunlicai/HiCMAE.
SVFAP: Self-supervised Video Facial Affect Perceiver
Dec 31, 2023



Video-based facial affect analysis has recently attracted increasing attention owing to its critical role in human-computer interaction. Previous studies mainly focus on developing various deep learning architectures and training them in a fully supervised manner. Although significant progress has been achieved by these supervised methods, the longstanding lack of large-scale high-quality labeled data severely hinders their further improvements. Motivated by the recent success of self-supervised learning in computer vision, this paper introduces a self-supervised approach, termed Self-supervised Video Facial Affect Perceiver (SVFAP), to address the dilemma faced by supervised methods. Specifically, SVFAP leverages masked facial video autoencoding to perform self-supervised pre-training on massive unlabeled facial videos. Considering that large spatiotemporal redundancy exists in facial videos, we propose a novel temporal pyramid and spatial bottleneck Transformer as the encoder of SVFAP, which not only enjoys low computational cost but also achieves excellent performance. To verify the effectiveness of our method, we conduct experiments on nine datasets spanning three downstream tasks, including dynamic facial expression recognition, dimensional emotion recognition, and personality recognition. Comprehensive results demonstrate that SVFAP can learn powerful affect-related representations via large-scale self-supervised pre-training and it significantly outperforms previous state-of-the-art methods on all datasets. Codes will be available at https://github.com/sunlicai/SVFAP.
GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding
Dec 07, 2023



Recently, GPT-4 with Vision (GPT-4V) has shown remarkable performance across various multimodal tasks. However, its efficacy in emotion recognition remains a question. This paper quantitatively evaluates GPT-4V's capabilities in multimodal emotion understanding, encompassing tasks such as facial emotion recognition, visual sentiment analysis, micro-expression recognition, dynamic facial emotion recognition, and multimodal emotion recognition. Our experiments show that GPT-4V exhibits impressive multimodal and temporal understanding capabilities, even surpassing supervised systems in some tasks. Despite these achievements, GPT-4V is currently tailored for general domains. It performs poorly in micro-expression recognition that requires specialized expertise. The main purpose of this paper is to present quantitative results of GPT-4V on emotion understanding and establish a zero-shot benchmark for future research. Code and evaluation results are available at: https://github.com/zeroQiaoba/gpt4v-emotion.
MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition
Jul 05, 2023Dynamic facial expression recognition (DFER) is essential to the development of intelligent and empathetic machines. Prior efforts in this field mainly fall into supervised learning paradigm, which is restricted by the limited labeled data in existing datasets. Inspired by recent unprecedented success of masked autoencoders (e.g., VideoMAE), this paper proposes MAE-DFER, a novel self-supervised method which leverages large-scale self-supervised pre-training on abundant unlabeled data to advance the development of DFER. Since the vanilla Vision Transformer (ViT) employed in VideoMAE requires substantial computation during fine-tuning, MAE-DFER develops an efficient local-global interaction Transformer (LGI-Former) as the encoder. LGI-Former first constrains self-attention in local spatiotemporal regions and then utilizes a small set of learnable representative tokens to achieve efficient local-global information exchange, thus avoiding the expensive computation of global space-time self-attention in ViT. Moreover, in addition to the standalone appearance content reconstruction in VideoMAE, MAE-DFER also introduces explicit facial motion modeling to encourage LGI-Former to excavate both static appearance and dynamic motion information. Extensive experiments on six datasets show that MAE-DFER consistently outperforms state-of-the-art supervised methods by significant margins, verifying that it can learn powerful dynamic facial representations via large-scale self-supervised pre-training. Besides, it has comparable or even better performance than VideoMAE, while largely reducing the computational cost (about 38\% FLOPs). We believe MAE-DFER has paved a new way for the advancement of DFER and can inspire more relavant research in this field and even other related tasks. Codes and models are publicly available at https://github.com/sunlicai/MAE-DFER.
MER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning
Apr 18, 2023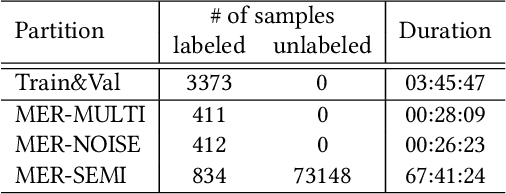
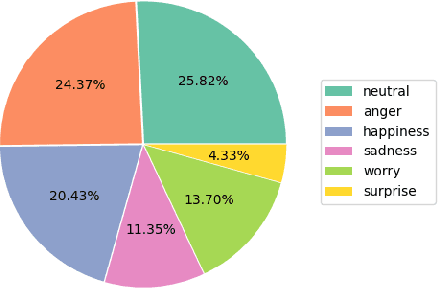
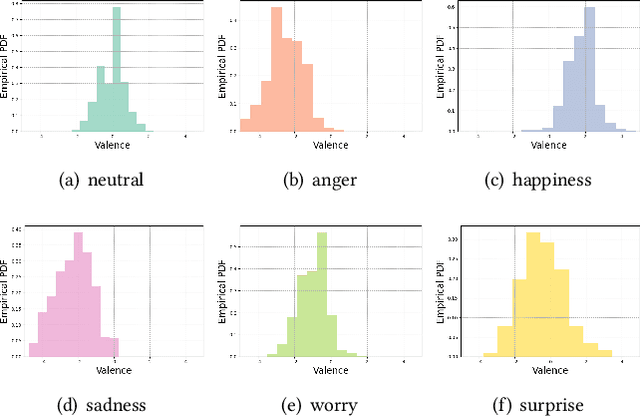
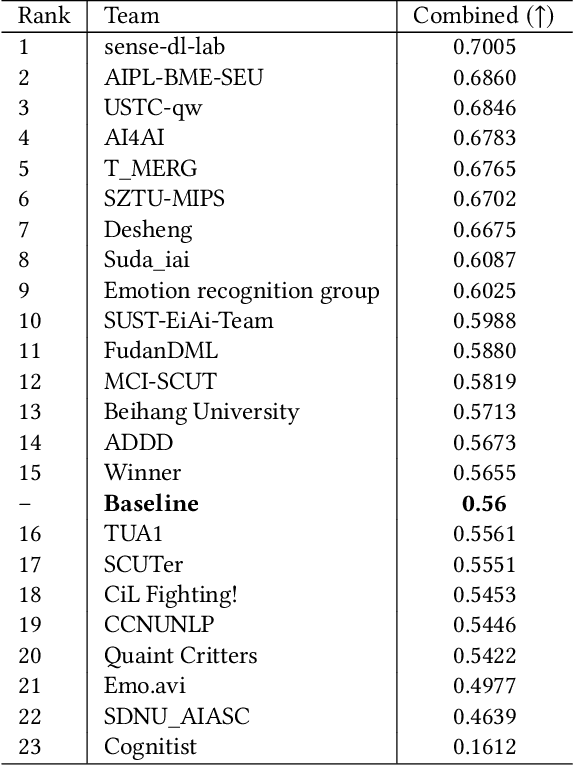
Over the past few decades, multimodal emotion recognition has made remarkable progress with the development of deep learning. However, existing technologies are difficult to meet the demand for practical applications. To improve the robustness, we launch a Multimodal Emotion Recognition Challenge (MER 2023) to motivate global researchers to build innovative technologies that can further accelerate and foster research. For this year's challenge, we present three distinct sub-challenges: (1) MER-MULTI, in which participants recognize both discrete and dimensional emotions; (2) MER-NOISE, in which noise is added to test videos for modality robustness evaluation; (3) MER-SEMI, which provides large amounts of unlabeled samples for semi-supervised learning. In this paper, we test a variety of multimodal features and provide a competitive baseline for each sub-challenge. Our system achieves 77.57% on the F1 score and 0.82 on the mean squared error (MSE) for MER-MULTI, 69.82% on the F1 score and 1.12 on MSE for MER-NOISE, and 86.75% on the F1 score for MER-SEMI, respectively. Baseline code is available at https://github.com/zeroQiaoba/MER2023-Baseline.
ARNet: Automatic Refinement Network for Noisy Partial Label Learning
Nov 10, 2022Partial label learning (PLL) is a typical weakly supervised learning, where each sample is associated with a set of candidate labels. The basic assumption of PLL is that the ground-truth label must reside in the candidate set. However, this assumption may not be satisfied due to the unprofessional judgment of the annotators, thus limiting the practical application of PLL. In this paper, we relax this assumption and focus on a more general problem, noisy PLL, where the ground-truth label may not exist in the candidate set. To address this challenging problem, we further propose a novel framework called "Automatic Refinement Network (ARNet)". Our method consists of multiple rounds. In each round, we purify the noisy samples through two key modules, i.e., noisy sample detection and label correction. To guarantee the performance of these modules, we start with warm-up training and automatically select the appropriate correction epoch. Meanwhile, we exploit data augmentation to further reduce prediction errors in ARNet. Through theoretical analysis, we prove that our method is able to reduce the noise level of the dataset and eventually approximate the Bayes optimal classifier. To verify the effectiveness of ARNet, we conduct experiments on multiple benchmark datasets. Experimental results demonstrate that our ARNet is superior to existing state-of-the-art approaches in noisy PLL. Our code will be made public soon.