 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Personality Traits: A New Benchmark Dataset for Explainable Personality Recognition on Dialogues
Sep 29, 2024



Personality recognition aims to identify the personality traits implied in user data such as dialogues and social media posts. Current research predominantly treats personality recognition as a classification task, failing to reveal the supporting evidence for the recognized personality. In this paper, we propose a novel task named Explainable Personality Recognition, aiming to reveal the reasoning process as supporting evidence of the personality trait. Inspired by personality theories, personality traits are made up of stable patterns of personality state, where the states are short-term characteristic patterns of thoughts, feelings, and behaviors in a concrete situation at a specific moment in time. We propose an explainable personality recognition framework called Chain-of-Personality-Evidence (CoPE), which involves a reasoning process from specific contexts to short-term personality states to long-term personality traits. Furthermore, based on the CoPE framework, we construct an explainable personality recognition dataset from dialogues, PersonalityEvd. We introduce two explainable personality state recognition and explainable personality trait recognition tasks, which require models to recognize the personality state and trait labels and their corresponding support evidence. Our extensive experiments based on Large Language Models on the two tasks show that revealing personality traits is very challenging and we present some insights for future research. Our data and code are available at https://github.com/Lei-Sun-RUC/PersonalityEvd.
Scaling A Simple Approach to Zero-Shot Speech Recognition
Jul 25, 2024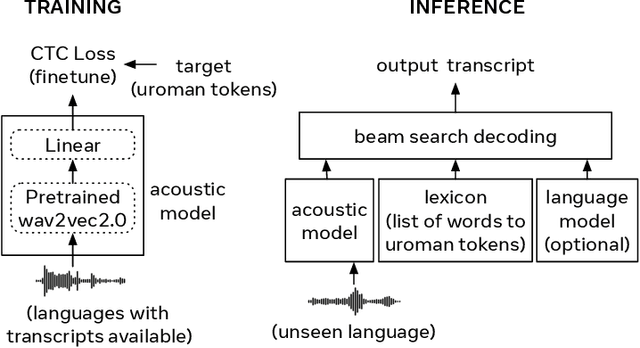


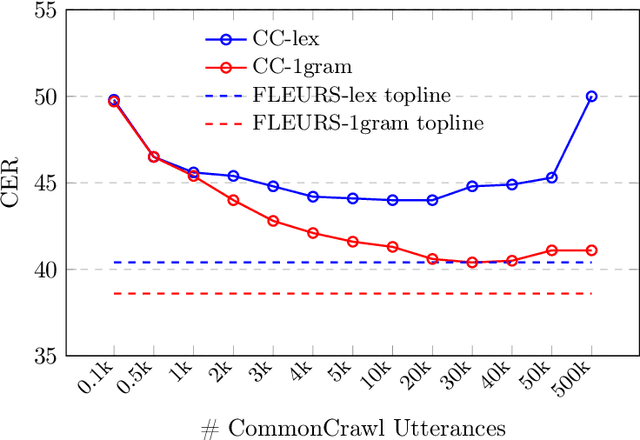
Despite rapid progress in increasing the language coverage of automatic speech recognition, the field is still far from covering all languages with a known writing script. Recent work showed promising results with a zero-shot approach requiring only a small amount of text data, however, accuracy heavily depends on the quality of the used phonemizer which is often weak for unseen languages. In this paper, we present MMS Zero-shot a conceptually simpler approach based on romanization and an acoustic model trained on data in 1,078 different languages or three orders of magnitude more than prior art. MMS Zero-shot reduces the average character error rate by a relative 46% over 100 unseen languages compared to the best previous work. Moreover, the error rate of our approach is only 2.5x higher compared to in-domain supervised baselines, while our approach uses no labeled data for the evaluation languages at all.
ESCoT: Towards Interpretable Emotional Support Dialogue Systems
Jun 16, 2024
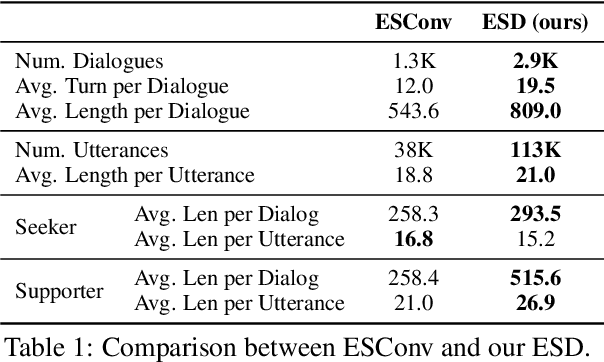

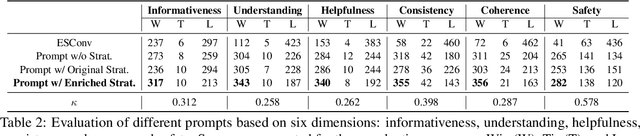
Understanding the reason for emotional support response is crucial for establishing connections between users and emotional support dialogue systems. Previous works mostly focus on generating better responses but ignore interpretability, which is extremely important for constructing reliable dialogue systems. To empower the system with better interpretability, we propose an emotional support response generation scheme, named $\textbf{E}$motion-Focused and $\textbf{S}$trategy-Driven $\textbf{C}$hain-$\textbf{o}$f-$\textbf{T}$hought ($\textbf{ESCoT}$), mimicking the process of $\textit{identifying}$, $\textit{understanding}$, and $\textit{regulating}$ emotions. Specially, we construct a new dataset with ESCoT in two steps: (1) $\textit{Dialogue Generation}$ where we first generate diverse conversation situations, then enhance dialogue generation using richer emotional support strategies based on these situations; (2) $\textit{Chain Supplement}$ where we focus on supplementing selected dialogues with elements such as emotion, stimuli, appraisal, and strategy reason, forming the manually verified chains. Additionally, we further develop a model to generate dialogue responses with better interpretability. We also conduct extensive experiments and human evaluations to validate the effectiveness of the proposed ESCoT and generated dialogue responses. Our data and code are available at $\href{https://github.com/TeigenZhang/ESCoT}{https://github.com/TeigenZhang/ESCoT}$.
ECR-Chain: Advancing Generative Language Models to Better Emotion-Cause Reasoners through Reasoning Chains
May 17, 2024



Understanding the process of emotion generation is crucial for analyzing the causes behind emotions. Causal Emotion Entailment (CEE), an emotion-understanding task, aims to identify the causal utterances in a conversation that stimulate the emotions expressed in a target utterance. However, current works in CEE mainly focus on modeling semantic and emotional interactions in conversations, neglecting the exploration of the emotion-generation process. This hinders the models from deeply understanding emotions, restricting their ability to produce explainable predictions. In this work, inspired by the emotion generation process of "stimulus-appraisal-emotion" in the cognitive appraisal theory, we introduce a step-by-step reasoning method, Emotion-Cause Reasoning Chain (ECR-Chain), to infer the stimulus from the target emotional expressions in conversations. Specifically, we first introduce the ECR-Chain to ChatGPT via few-shot prompting, which significantly improves its performance on the CEE task. We further propose an automated construction process to utilize ChatGPT in building an ECR-Chain set, which can enhance the reasoning abilities of smaller models through supervised training and assist the Vicuna-7B model in achieving state-of-the-art CEE performance. Moreover, our methods can enable these generative language models to effectively perform emotion-cause reasoning in an explainable manner. Our code, data and more details are at https://github.com/hzp3517/ECR-Chain.
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Apr 29, 2024



Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing dataset size and building more effective architectures. However, due to various reasons (such as complex environments and inaccurate labels), current systems still cannot meet the demands of practical applications. Therefore, we plan to organize a series of challenges around emotion recognition to further promote the development of this field. Last year, we launched MER2023, focusing on three topics: multi-label learning, noise robustness, and semi-supervised learning. This year, we continue to organize MER2024. In addition to expanding the dataset size, we introduce a new track around open-vocabulary emotion recognition. The main consideration for this track is that existing datasets often fix the label space and use majority voting to enhance annotator consistency, but this process may limit the model's ability to describe subtle emotions. In this track, we encourage participants to generate any number of labels in any category, aiming to describe the emotional state as accurately as possible. Our baseline is based on MERTools and the code is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Double Mixture: Towards Continual Event Detection from Speech
Apr 20, 2024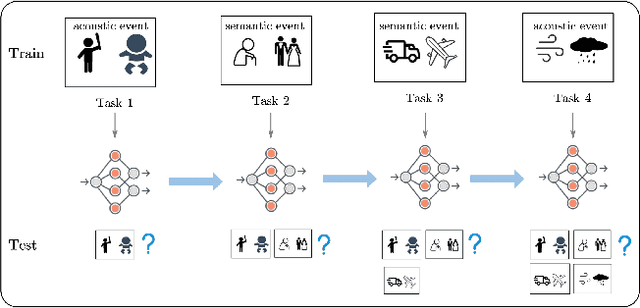
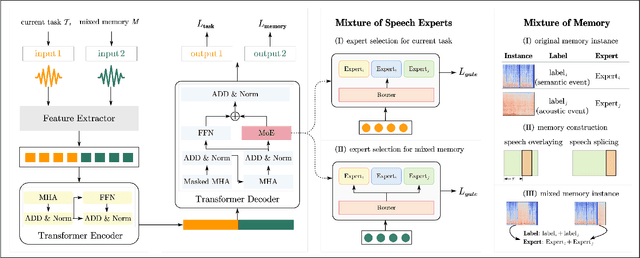
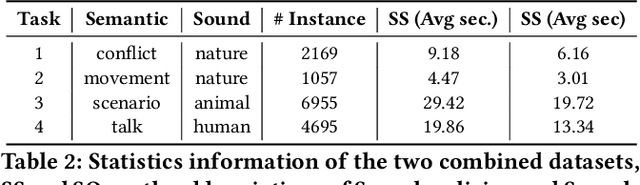
Speech event detection is crucial for multimedia retrieval, involving the tagging of both semantic and acoustic events. Traditional ASR systems often overlook the interplay between these events, focusing solely on content, even though the interpretation of dialogue can vary with environmental context. This paper tackles two primary challenges in speech event detection: the continual integration of new events without forgetting previous ones, and the disentanglement of semantic from acoustic events. We introduce a new task, continual event detection from speech, for which we also provide two benchmark datasets. To address the challenges of catastrophic forgetting and effective disentanglement, we propose a novel method, 'Double Mixture.' This method merges speech expertise with robust memory mechanisms to enhance adaptability and prevent forgetting. Our comprehensive experiments show that this task presents significant challenges that are not effectively addressed by current state-of-the-art methods in either computer vision or natural language processing. Our approach achieves the lowest rates of forgetting and the highest levels of generalization, proving robust across various continual learning sequences. Our code and data are available at https://anonymous.4open.science/status/Continual-SpeechED-6461.
Towards Event Extraction from Speech with Contextual Clues
Jan 27, 2024While text-based event extraction has been an active research area and has seen successful application in many domains, extracting semantic events from speech directly is an under-explored problem. In this paper, we introduce the Speech Event Extraction (SpeechEE) task and construct three synthetic training sets and one human-spoken test set. Compared to event extraction from text, SpeechEE poses greater challenges mainly due to complex speech signals that are continuous and have no word boundaries. Additionally, unlike perceptible sound events, semantic events are more subtle and require a deeper understanding. To tackle these challenges, we introduce a sequence-to-structure generation paradigm that can produce events from speech signals in an end-to-end manner, together with a conditioned generation method that utilizes speech recognition transcripts as the contextual clue. We further propose to represent events with a flat format to make outputs more natural language-like. Our experimental results show that our method brings significant improvements on all datasets, achieving a maximum F1 gain of 10.7%. The code and datasets are released on https://github.com/jodie-kang/SpeechEE.
Simultaneous Machine Translation with Large Language Models
Sep 13, 2023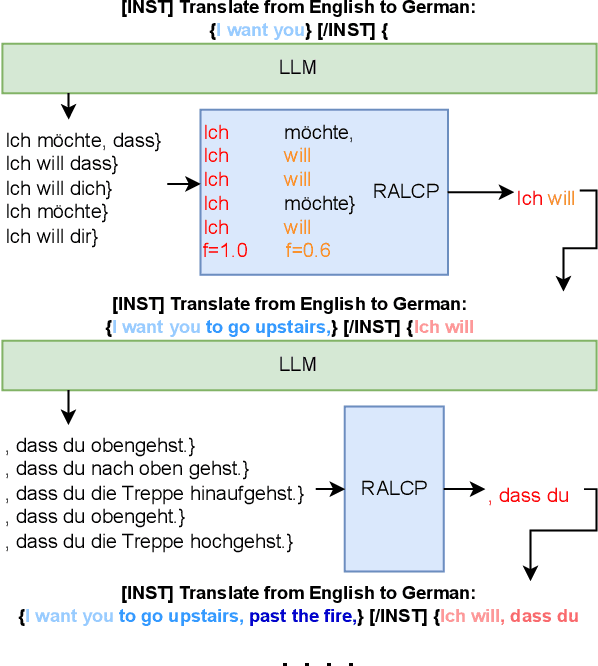


Large language models (LLM) have demonstrated their abilities to solve various natural language processing tasks through dialogue-based interactions. For instance, research indicates that LLMs can achieve competitive performance in offline machine translation tasks for high-resource languages. However, applying LLMs to simultaneous machine translation (SimulMT) poses many challenges, including issues related to the training-inference mismatch arising from different decoding patterns. In this paper, we explore the feasibility of utilizing LLMs for SimulMT. Building upon conventional approaches, we introduce a simple yet effective mixture policy that enables LLMs to engage in SimulMT without requiring additional training. Furthermore, after Supervised Fine-Tuning (SFT) on a mixture of full and prefix sentences, the model exhibits significant performance improvements. Our experiments, conducted with Llama2-7B-chat on nine language pairs from the MUST-C dataset, demonstrate that LLM can achieve translation quality and latency comparable to dedicated SimulMT models.
Investigating Pre-trained Audio Encoders in the Low-Resource Condition
May 28, 2023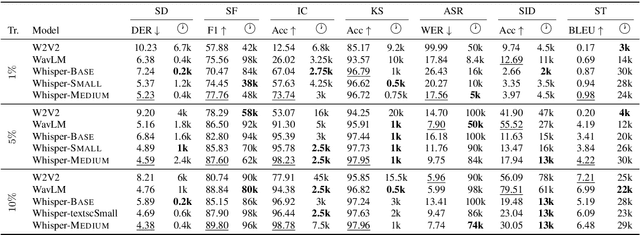

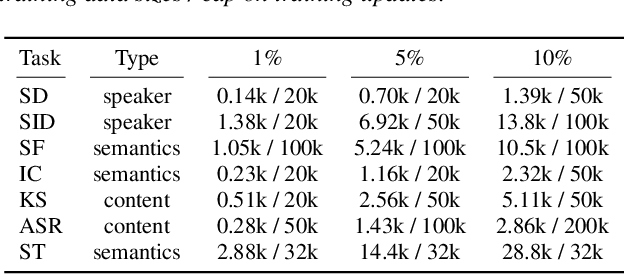
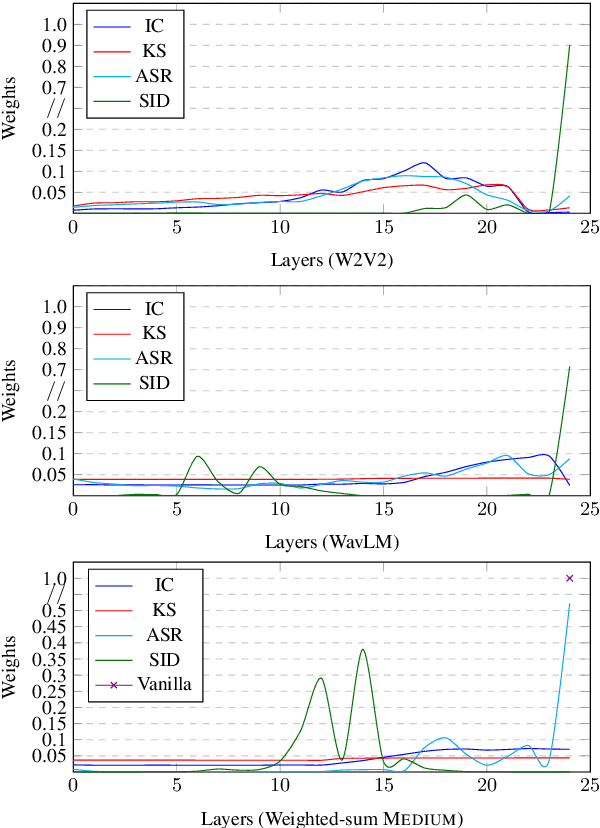
Pre-trained speech encoders have been central to pushing state-of-the-art results across various speech understanding and generation tasks. Nonetheless, the capabilities of these encoders in low-resource settings are yet to be thoroughly explored. To address this, we conduct a comprehensive set of experiments using a representative set of 3 state-of-the-art encoders (Wav2vec2, WavLM, Whisper) in the low-resource setting across 7 speech understanding and generation tasks. We provide various quantitative and qualitative analyses on task performance, convergence speed, and representational properties of the encoders. We observe a connection between the pre-training protocols of these encoders and the way in which they capture information in their internal layers. In particular, we observe the Whisper encoder exhibits the greatest low-resource capabilities on content-driven tasks in terms of performance and convergence speed.
NAIST-SIC-Aligned: Automatically-Aligned English-Japanese Simultaneous Interpretation Corpus
Apr 25, 2023

It remains a question that how simultaneous interpretation (SI) data affects simultaneous machine translation (SiMT). Research has been limited due to the lack of a large-scale training corpus. In this work, we aim to fill in the gap by introducing NAIST-SIC-Aligned, which is an automatically-aligned parallel English-Japanese SI dataset. Starting with a non-aligned corpus NAIST-SIC, we propose a two-stage alignment approach to make the corpus parallel and thus suitable for model training. The first stage is coarse alignment where we perform a many-to-many mapping between source and target sentences, and the second stage is fine-grained alignment where we perform intra- and inter-sentence filtering to improve the quality of aligned pairs. To ensure the quality of the corpus, each step has been validated either quantitatively or qualitatively. This is the first open-sourced large-scale parallel SI dataset in the literature. We also manually curated a small test set for evaluation purposes. We hope our work advances research on SI corpora construction and SiMT. Please find our data at \url{https://github.com/mingzi151/AHC-SI}.