 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Mixture: Towards Continual Event Detection from Speech
Apr 20, 2024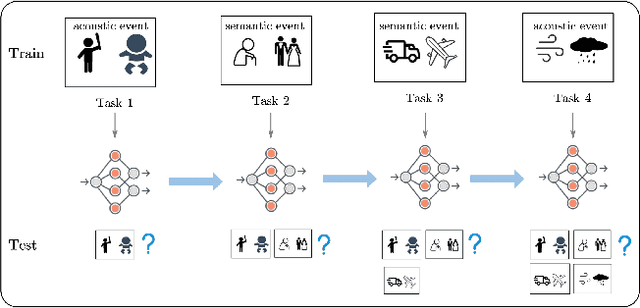
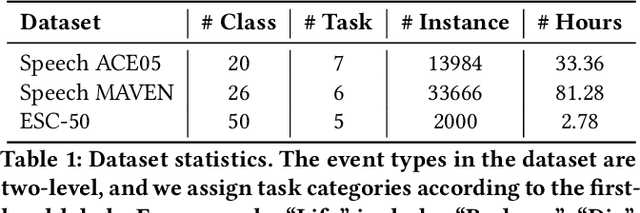
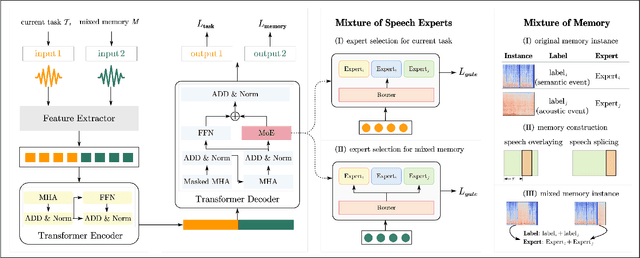
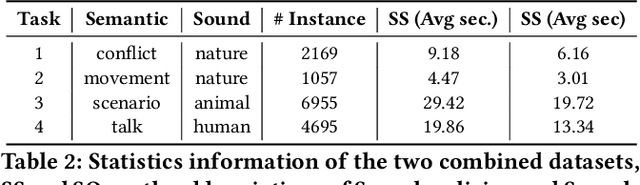
Speech event detection is crucial for multimedia retrieval, involving the tagging of both semantic and acoustic events. Traditional ASR systems often overlook the interplay between these events, focusing solely on content, even though the interpretation of dialogue can vary with environmental context. This paper tackles two primary challenges in speech event detection: the continual integration of new events without forgetting previous ones, and the disentanglement of semantic from acoustic events. We introduce a new task, continual event detection from speech, for which we also provide two benchmark datasets. To address the challenges of catastrophic forgetting and effective disentanglement, we propose a novel method, 'Double Mixture.' This method merges speech expertise with robust memory mechanisms to enhance adaptability and prevent forgetting. Our comprehensive experiments show that this task presents significant challenges that are not effectively addressed by current state-of-the-art methods in either computer vision or natural language processing. Our approach achieves the lowest rates of forgetting and the highest levels of generalization, proving robust across various continual learning sequences. Our code and data are available at https://anonymous.4open.science/status/Continual-SpeechED-6461.
Towards Event Extraction from Speech with Contextual Clues
Jan 27, 2024While text-based event extraction has been an active research area and has seen successful application in many domains, extracting semantic events from speech directly is an under-explored problem. In this paper, we introduce the Speech Event Extraction (SpeechEE) task and construct three synthetic training sets and one human-spoken test set. Compared to event extraction from text, SpeechEE poses greater challenges mainly due to complex speech signals that are continuous and have no word boundaries. Additionally, unlike perceptible sound events, semantic events are more subtle and require a deeper understanding. To tackle these challenges, we introduce a sequence-to-structure generation paradigm that can produce events from speech signals in an end-to-end manner, together with a conditioned generation method that utilizes speech recognition transcripts as the contextual clue. We further propose to represent events with a flat format to make outputs more natural language-like. Our experimental results show that our method brings significant improvements on all datasets, achieving a maximum F1 gain of 10.7%. The code and datasets are released on https://github.com/jodie-kang/SpeechEE.