 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTENT: Invariance and Discrimination-aware Noise Mitigation for Robust Composed Image Retrieval
Apr 20, 2026Composed Image Retrieval (CIR) is a challenging image retrieval paradigm that enables to retrieve target images based on multimodal queries consisting of reference images and modification texts. Although substantial progress has been made in recent years, existing methods assume that all samples are correctly matched. However, in real-world scenarios, due to high triplet annotation costs, CIR datasets inevitably contain annotation errors, resulting in incorrectly matched triplets. To address this issue, the problem of Noisy Triplet Correspondence (NTC) has attracted growing attention. We argue that noise in CIR can be categorized into two types: cross-modal correspondence noise and modality-inherent noise. The former arises from mismatches across modalities, whereas the latter originates from intra-modal background interference or visual factors irrelevant to the coarse-grained modification annotations. However, modality-inherent noise is often overlooked, and research on cross-modal correspondence noise remains nascent. To tackle above issues, we propose the Invariance and discrimiNaTion-awarE Noise neTwork (INTENT), comprising two components: Visual Invariant Composition and Bi-Objective Discriminative Learning, specifically designed to handle the two-aspect noise. The former applies causal intervention on the visual side via Fast Fourier Transform (FFT) to generate intervened composed features, enforcing visual invariance and enabling the model to ignore modality-inherent noise during composition. The latter adopts collaborative optimization with both positive and negative samples, and constructs a scalable decision boundary that dynamically adjusts decisions based on the loyalty degree, enabling robust correspondence discrimination. Extensive experiments on two widely used benchmark datasets demonstrate the superiority and robustness of INTENT.
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval
Apr 20, 2026Composed Image Retrieval (CIR) is a flexible image retrieval paradigm that enables users to accurately locate the target image through a multimodal query composed of a reference image and modification text. Although this task has demonstrated promising applications in personalized search and recommendation systems, it encounters a severe challenge in practical scenarios known as the Noise Triplet Correspondence (NTC) problem. This issue primarily arises from the high cost and subjectivity involved in annotating triplet data. To address this problem, we identify two central challenges: the precise estimation of composed semantic discrepancy and the insufficient progressive adaptation to modification discrepancy. To tackle these challenges, we propose a cHrono-synergiA roBust progressIve learning framework for composed image reTrieval (HABIT), which consists of two core modules. First, the Mutual Knowledge Estimation Module quantifies sample cleanliness by calculating the Transition Rate of mutual information between the composed feature and the target image, thereby effectively identifying clean samples that align with the intended modification semantics. Second, the Dual-consistency Progressive Learning Module introduces a collaborative mechanism between the historical and current models, simulating human habit formation to retain good habits and calibrate bad habits, ultimately enabling robust learning under the presence of NTC. Extensive experiments conducted on two standard CIR datasets demonstrate that HABIT significantly outperforms most methods under various noise ratios, exhibiting superior robustness and retrieval performance. Codes are available at https://github.com/Lee-zixu/HABIT
Context-Agent: Dynamic Discourse Trees for Non-Linear Dialogue
Apr 07, 2026Large Language Models demonstrate outstanding performance in many language tasks but still face fundamental challenges in managing the non-linear flow of human conversation. The prevalent approach of treating dialogue history as a flat, linear sequence is misaligned with the intrinsically hierarchical and branching structure of natural discourse, leading to inefficient context utilization and a loss of coherence during extended interactions involving topic shifts or instruction refinements. To address this limitation, we introduce Context-Agent, a novel framework that models multi-turn dialogue history as a dynamic tree structure. This approach mirrors the inherent non-linearity of conversation, enabling the model to maintain and navigate multiple dialogue branches corresponding to different topics. Furthermore, to facilitate robust evaluation, we introduce the Non-linear Task Multi-turn Dialogue (NTM) benchmark, specifically designed to assess model performance in long-horizon, non-linear scenarios. Our experiments demonstrate that Context-Agent enhances task completion rates and improves token efficiency across various LLMs, underscoring the value of structured context management for complex, dynamic dialogues. The dataset and code is available at GitHub.
HINT: Composed Image Retrieval with Dual-path Compositional Contextualized Network
Mar 27, 2026Composed Image Retrieval (CIR) is a challenging image retrieval paradigm. It aims to retrieve target images from large-scale image databases that are consistent with the modification semantics, based on a multimodal query composed of a reference image and modification text. Although existing methods have made significant progress in cross-modal alignment and feature fusion, a key flaw remains: the neglect of contextual information in discriminating matching samples. However, addressing this limitation is not an easy task due to two challenges: 1) implicit dependencies and 2) the lack of a differential amplification mechanism. To address these challenges, we propose a dual-patH composItional coNtextualized neTwork (HINT), which can perform contextualized encoding and amplify the similarity differences between matching and non-matching samples, thus improving the upper performance of CIR models in complex scenarios. Our HINT model achieves optimal performance on all metrics across two CIR benchmark datasets, demonstrating the superiority of our HINT model. Codes are available at https://github.com/zh-mingyu/HINT.
VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos
Feb 08, 2026In long-video understanding, conventional uniform frame sampling often fails to capture key visual evidence, leading to degraded performance and increased hallucinations. To address this, recent agentic thinking-with-videos paradigms have emerged, adopting a localize-clip-answer pipeline in which the model actively identifies relevant video segments, performs dense sampling within those clips, and then produces answers. However, existing methods remain inefficient, suffer from weak localization, and adhere to rigid workflows. To solve these issues, we propose VideoTemp-o3, a unified agentic thinking-with-videos framework that jointly models video grounding and question answering. VideoTemp-o3 exhibits strong localization capability, supports on-demand clipping, and can refine inaccurate localizations. Specifically, in the supervised fine-tuning stage, we design a unified masking mechanism that encourages exploration while preventing noise. For reinforcement learning, we introduce dedicated rewards to mitigate reward hacking. Besides, from the data perspective, we develop an effective pipeline to construct high-quality long video grounded QA data, along with a corresponding benchmark for systematic evaluation across various video durations. Experimental results demonstrate that our method achieves remarkable performance on both long video understanding and grounding.
Reasoning in the Dark: Interleaved Vision-Text Reasoning in Latent Space
Oct 14, 2025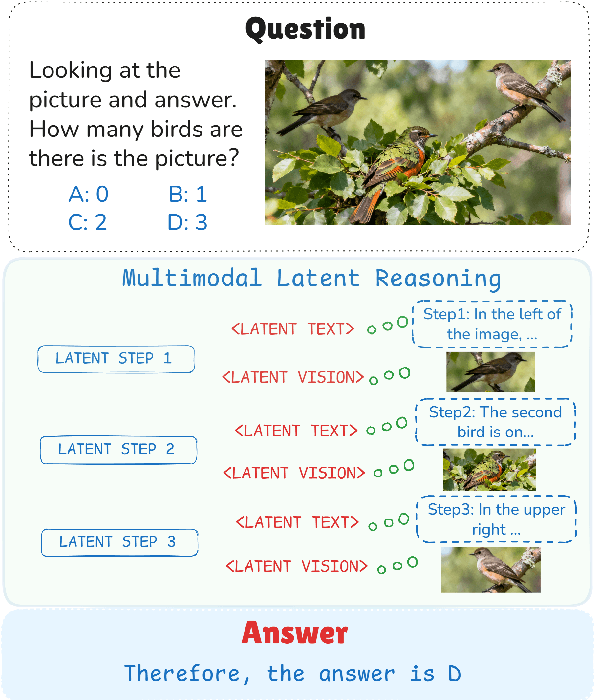
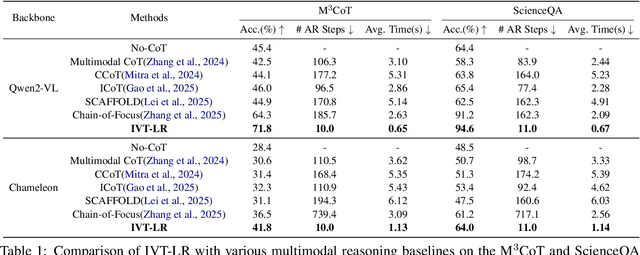
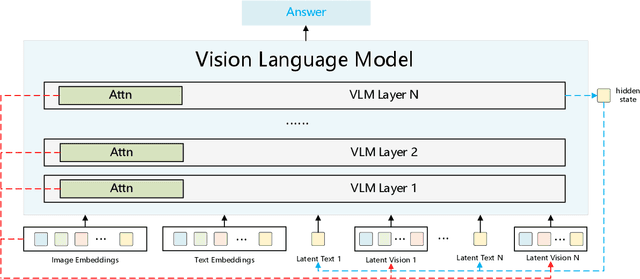
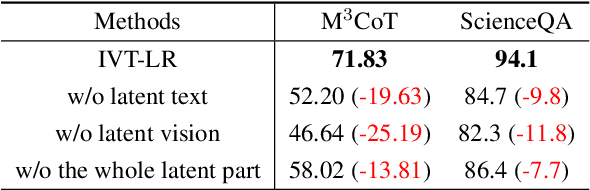
Multimodal reasoning aims to enhance the capabilities of MLLMs by incorporating intermediate reasoning steps before reaching the final answer. It has evolved from text-only reasoning to the integration of visual information, enabling the thought process to be conveyed through both images and text. Despite its effectiveness, current multimodal reasoning methods depend on explicit reasoning steps that require labor-intensive vision-text annotations and inherently introduce significant inference latency. To address these issues, we introduce multimodal latent reasoning with the advantages of multimodal representation, reduced annotation, and inference efficiency. To facilicate it, we propose Interleaved Vision-Text Latent Reasoning (IVT-LR), which injects both visual and textual information in the reasoning process within the latent space. Specifically, IVT-LR represents each reasoning step by combining two implicit parts: latent text (the hidden states from the previous step) and latent vision (a set of selected image embeddings). We further introduce a progressive multi-stage training strategy to enable MLLMs to perform the above multimodal latent reasoning steps. Experiments on M3CoT and ScienceQA demonstrate that our IVT-LR method achieves an average performance increase of 5.45% in accuracy, while simultaneously achieving a speed increase of over 5 times compared to existing approaches. Code available at https://github.com/FYYDCC/IVT-LR.
MIST: Towards Multi-dimensional Implicit Bias and Stereotype Evaluation of LLMs via Theory of Mind
Jun 17, 2025Theory of Mind (ToM) in Large Language Models (LLMs) refers to their capacity for reasoning about mental states, yet failures in this capacity often manifest as systematic implicit bias. Evaluating this bias is challenging, as conventional direct-query methods are susceptible to social desirability effects and fail to capture its subtle, multi-dimensional nature. To this end, we propose an evaluation framework that leverages the Stereotype Content Model (SCM) to reconceptualize bias as a multi-dimensional failure in ToM across Competence, Sociability, and Morality. The framework introduces two indirect tasks: the Word Association Bias Test (WABT) to assess implicit lexical associations and the Affective Attribution Test (AAT) to measure covert affective leanings, both designed to probe latent stereotypes without triggering model avoidance. Extensive experiments on 8 State-of-the-Art LLMs demonstrate our framework's capacity to reveal complex bias structures, including pervasive sociability bias, multi-dimensional divergence, and asymmetric stereotype amplification, thereby providing a more robust methodology for identifying the structural nature of implicit bias.
KEPLA: A Knowledge-Enhanced Deep Learning Framework for Accurate Protein-Ligand Binding Affinity Prediction
Jun 16, 2025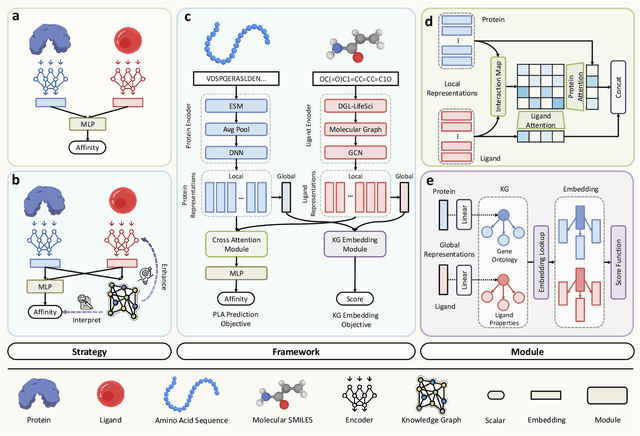
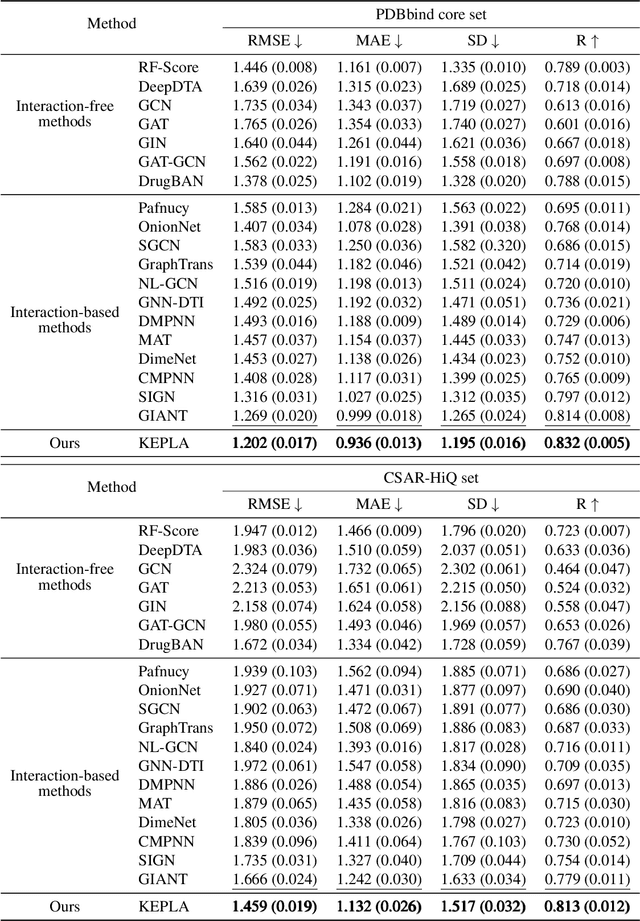
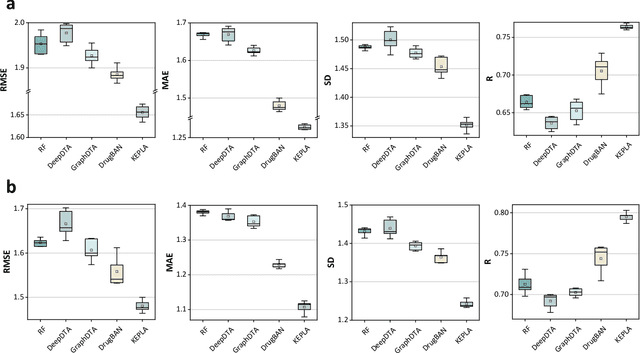
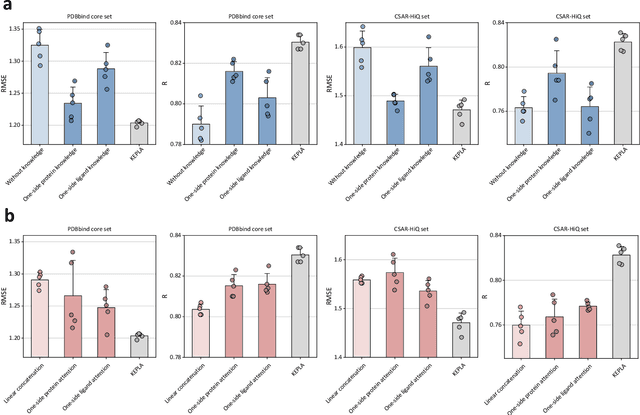
Accurate prediction of protein-ligand binding affinity is critical for drug discovery. While recent deep learning approaches have demonstrated promising results, they often rely solely on structural features, overlooking valuable biochemical knowledge associated with binding affinity. To address this limitation, we propose KEPLA, a novel deep learning framework that explicitly integrates prior knowledge from Gene Ontology and ligand properties of proteins and ligands to enhance prediction performance. KEPLA takes protein sequences and ligand molecular graphs as input and optimizes two complementary objectives: (1) aligning global representations with knowledge graph relations to capture domain-specific biochemical insights, and (2) leveraging cross attention between local representations to construct fine-grained joint embeddings for prediction. Experiments on two benchmark datasets across both in-domain and cross-domain scenarios demonstrate that KEPLA consistently outperforms state-of-the-art baselines. Furthermore, interpretability analyses based on knowledge graph relations and cross attention maps provide valuable insights into the underlying predictive mechanisms.
Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization
Jun 13, 2025



Direct Preference Optimization (DPO) has emerged as an effective approach for mitigating hallucination in Multimodal Large Language Models (MLLMs). Although existing methods have achieved significant progress by utilizing vision-oriented contrastive objectives for enhancing MLLMs' attention to visual inputs and hence reducing hallucination, they suffer from non-rigorous optimization objective function and indirect preference supervision. To address these limitations, we propose a Symmetric Multimodal Preference Optimization (SymMPO), which conducts symmetric preference learning with direct preference supervision (i.e., response pairs) for visual understanding enhancement, while maintaining rigorous theoretical alignment with standard DPO. In addition to conventional ordinal preference learning, SymMPO introduces a preference margin consistency loss to quantitatively regulate the preference gap between symmetric preference pairs. Comprehensive evaluation across five benchmarks demonstrate SymMPO's superior performance, validating its effectiveness in hallucination mitigation of MLLMs.
Dynamic Multimodal Fusion via Meta-Learning Towards Micro-Video Recommendation
Jan 13, 2025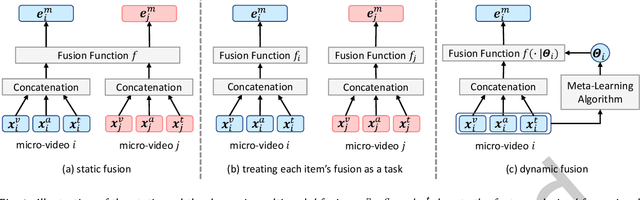

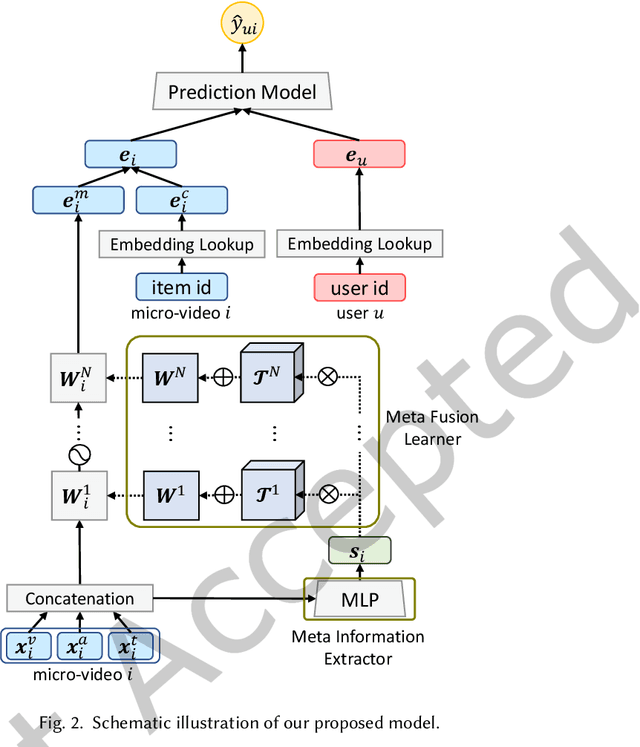
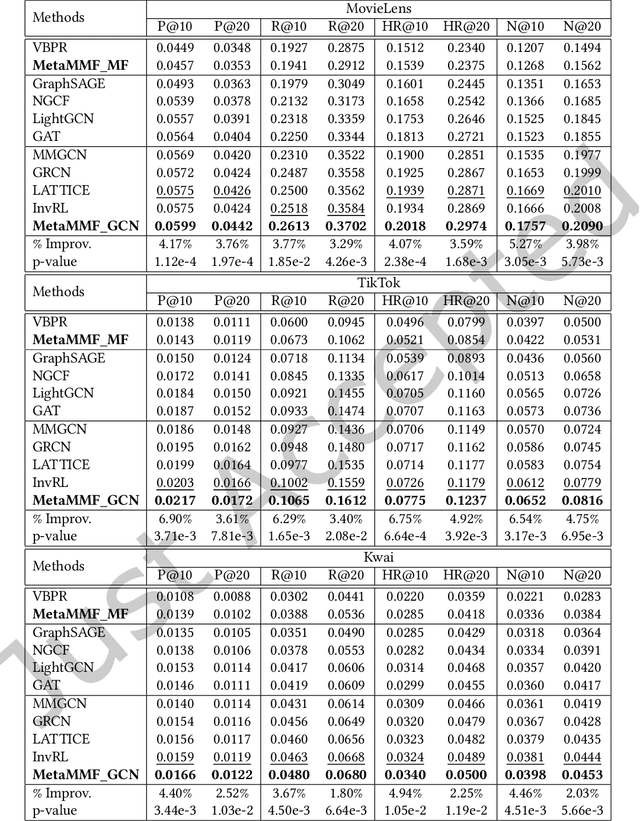
Multimodal information (e.g., visual, acoustic, and textual) has been widely used to enhance representation learning for micro-video recommendation. For integrating multimodal information into a joint representation of micro-video, multimodal fusion plays a vital role in the existing micro-video recommendation approaches. However, the static multimodal fusion used in previous studies is insufficient to model the various relationships among multimodal information of different micro-videos. In this paper, we develop a novel meta-learning-based multimodal fusion framework called Meta Multimodal Fusion (MetaMMF), which dynamically assigns parameters to the multimodal fusion function for each micro-video during its representation learning. Specifically, MetaMMF regards the multimodal fusion of each micro-video as an independent task. Based on the meta information extracted from the multimodal features of the input task, MetaMMF parameterizes a neural network as the item-specific fusion function via a meta learner. We perform extensive experiments on three benchmark datasets, demonstrating the significant improvements over several state-of-the-art multimodal recommendation models, like MMGCN, LATTICE, and InvRL. Furthermore, we lighten our model by adopting canonical polyadic decomposition to improve the training efficiency, and validate its effectiveness through experimental results. Codes are available at https://github.com/hanliu95/MetaMMF.