 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdering-based Causal Discovery via Generalized Score Matching
Jan 26, 2026Learning DAG structures from purely observational data remains a long-standing challenge across scientific domains. An emerging line of research leverages the score of the data distribution to initially identify a topological order of the underlying DAG via leaf node detection and subsequently performs edge pruning for graph recovery. This paper extends the score matching framework for causal discovery, which is originally designated for continuous data, and introduces a novel leaf discriminant criterion based on the discrete score function. Through simulated and real-world experiments, we demonstrate that our theory enables accurate inference of true causal orders from observed discrete data and the identified ordering can significantly boost the accuracy of existing causal discovery baselines on nearly all of the settings.
CTPD: Cross Tokenizer Preference Distillation
Jan 17, 2026While knowledge distillation has seen widespread use in pre-training and instruction tuning, its application to aligning language models with human preferences remains underexplored, particularly in the more realistic cross-tokenizer setting. The incompatibility of tokenization schemes between teacher and student models has largely prevented fine-grained, white-box distillation of preference information. To address this gap, we propose Cross-Tokenizer Preference Distillation (CTPD), the first unified framework for transferring human-aligned behavior between models with heterogeneous tokenizers. CTPD introduces three key innovations: (1) Aligned Span Projection, which maps teacher and student tokens to shared character-level spans for precise supervision transfer; (2) a cross-tokenizer adaptation of Token-level Importance Sampling (TIS-DPO) for improved credit assignment; and (3) a Teacher-Anchored Reference, allowing the student to directly leverage the teacher's preferences in a DPO-style objective. Our theoretical analysis grounds CTPD in importance sampling, and experiments across multiple benchmarks confirm its effectiveness, with significant performance gains over existing methods. These results establish CTPD as a practical and general solution for preference distillation across diverse tokenization schemes, opening the door to more accessible and efficient alignment of language models.
On the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025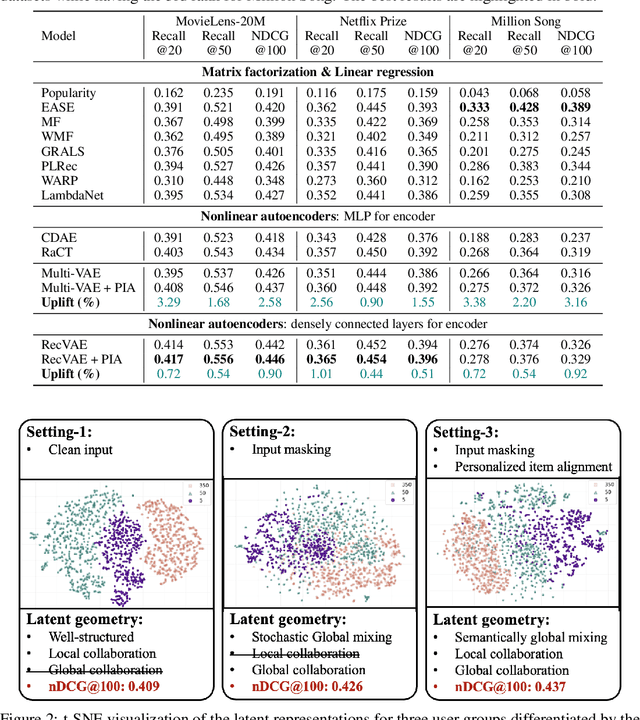
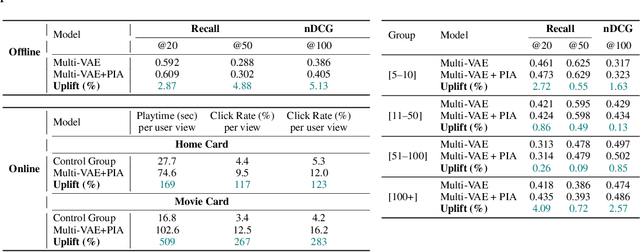

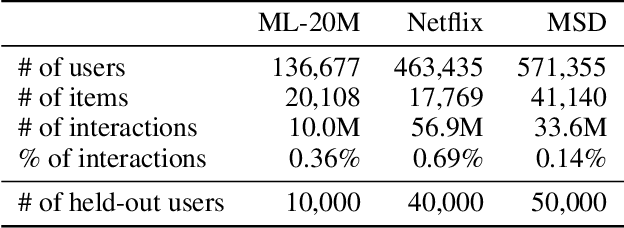
Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
Multilayer GNN for Predictive Maintenance and Clustering in Power Grids
Jul 09, 2025Unplanned power outages cost the US economy over $150 billion annually, partly due to predictive maintenance (PdM) models that overlook spatial, temporal, and causal dependencies in grid failures. This study introduces a multilayer Graph Neural Network (GNN) framework to enhance PdM and enable resilience-based substation clustering. Using seven years of incident data from Oklahoma Gas & Electric (292,830 records across 347 substations), the framework integrates Graph Attention Networks (spatial), Graph Convolutional Networks (temporal), and Graph Isomorphism Networks (causal), fused through attention-weighted embeddings. Our model achieves a 30-day F1-score of 0.8935 +/- 0.0258, outperforming XGBoost and Random Forest by 3.2% and 2.7%, and single-layer GNNs by 10 to 15 percent. Removing the causal layer drops performance to 0.7354 +/- 0.0418. For resilience analysis, HDBSCAN clustering on HierarchicalRiskGNN embeddings identifies eight operational risk groups. The highest-risk cluster (Cluster 5, 44 substations) shows 388.4 incidents/year and 602.6-minute recovery time, while low-risk groups report fewer than 62 incidents/year. ANOVA (p < 0.0001) confirms significant inter-cluster separation. Our clustering outperforms K-Means and Spectral Clustering with a Silhouette Score of 0.626 and Davies-Bouldin index of 0.527. This work supports proactive grid management through improved failure prediction and risk-aware substation clustering.
Preserving Clusters in Prompt Learning for Unsupervised Domain Adaptation
Jun 13, 2025Recent approaches leveraging multi-modal pre-trained models like CLIP for Unsupervised Domain Adaptation (UDA) have shown significant promise in bridging domain gaps and improving generalization by utilizing rich semantic knowledge and robust visual representations learned through extensive pre-training on diverse image-text datasets. While these methods achieve state-of-the-art performance across benchmarks, much of the improvement stems from base pseudo-labels (CLIP zero-shot predictions) and self-training mechanisms. Thus, the training mechanism exhibits a key limitation wherein the visual embedding distribution in target domains can deviate from the visual embedding distribution in the pre-trained model, leading to misguided signals from class descriptions. This work introduces a fresh solution to reinforce these pseudo-labels and facilitate target-prompt learning, by exploiting the geometry of visual and text embeddings - an aspect that is overlooked by existing methods. We first propose to directly leverage the reference predictions (from source prompts) based on the relationship between source and target visual embeddings. We later show that there is a strong clustering behavior observed between visual and text embeddings in pre-trained multi-modal models. Building on optimal transport theory, we transform this insight into a novel strategy to enforce the clustering property in text embeddings, further enhancing the alignment in the target domain. Our experiments and ablation studies validate the effectiveness of the proposed approach, demonstrating superior performance and improved quality of target prompts in terms of representation.
Promoting Ensemble Diversity with Interactive Bayesian Distributional Robustness for Fine-tuning Foundation Models
Jun 08, 2025We introduce Interactive Bayesian Distributional Robustness (IBDR), a novel Bayesian inference framework that allows modeling the interactions between particles, thereby enhancing ensemble quality through increased particle diversity. IBDR is grounded in a generalized theoretical framework that connects the distributional population loss with the approximate posterior, motivating a practical dual optimization procedure that enforces distributional robustness while fostering particle diversity. We evaluate IBDR's performance against various baseline methods using the VTAB-1K benchmark and the common reasoning language task. The results consistently show that IBDR outperforms these baselines, underscoring its effectiveness in real-world applications.
Exemplar-Free Continual Learning for State Space Models
May 24, 2025State-Space Models (SSMs) excel at capturing long-range dependencies with structured recurrence, making them well-suited for sequence modeling. However, their evolving internal states pose challenges in adapting them under Continual Learning (CL). This is particularly difficult in exemplar-free settings, where the absence of prior data leaves updates to the dynamic SSM states unconstrained, resulting in catastrophic forgetting. To address this, we propose Inf-SSM, a novel and simple geometry-aware regularization method that utilizes the geometry of the infinite-dimensional Grassmannian to constrain state evolution during CL. Unlike classical continual learning methods that constrain weight updates, Inf-SSM regularizes the infinite-horizon evolution of SSMs encoded in their extended observability subspace. We show that enforcing this regularization requires solving a matrix equation known as the Sylvester equation, which typically incurs $\mathcal{O}(n^3)$ complexity. We develop a $\mathcal{O}(n^2)$ solution by exploiting the structure and properties of SSMs. This leads to an efficient regularization mechanism that can be seamlessly integrated into existing CL methods. Comprehensive experiments on challenging benchmarks, including ImageNet-R and Caltech-256, demonstrate a significant reduction in forgetting while improving accuracy across sequential tasks.
Optimizing Specific and Shared Parameters for Efficient Parameter Tuning
Apr 04, 2025Foundation models, with a vast number of parameters and pretraining on massive datasets, achieve state-of-the-art performance across various applications. However, efficiently adapting them to downstream tasks with minimal computational overhead remains a challenge. Parameter-Efficient Transfer Learning (PETL) addresses this by fine-tuning only a small subset of parameters while preserving pre-trained knowledge. In this paper, we propose SaS, a novel PETL method that effectively mitigates distributional shifts during fine-tuning. SaS integrates (1) a shared module that captures common statistical characteristics across layers using low-rank projections and (2) a layer-specific module that employs hypernetworks to generate tailored parameters for each layer. This dual design ensures an optimal balance between performance and parameter efficiency while introducing less than 0.05% additional parameters, making it significantly more compact than existing methods. Extensive experiments on diverse downstream tasks, few-shot settings and domain generalization demonstrate that SaS significantly enhances performance while maintaining superior parameter efficiency compared to existing methods, highlighting the importance of capturing both shared and layer-specific information in transfer learning. Code and data are available at https://anonymous.4open.science/r/SaS-PETL-3565.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers
Feb 25, 2025



Large Language Models (LLMs) achieve state-of-the-art performance across various NLP tasks but face deployment challenges due to high computational costs and memory constraints. Knowledge distillation (KD) is a promising solution, transferring knowledge from large teacher models to smaller student models. However, existing KD methods often assume shared vocabularies and tokenizers, limiting their flexibility. While approaches like Universal Logit Distillation (ULD) and Dual-Space Knowledge Distillation (DSKD) address vocabulary mismatches, they overlook the critical \textbf{reasoning-aware distillation} aspect. To bridge this gap, we propose CoT2Align a universal KD framework that integrates Chain-of-Thought (CoT) augmentation and introduces Cross-CoT Alignment to enhance reasoning transfer. Additionally, we extend Optimal Transport beyond token-wise alignment to a sequence-level and layer-wise alignment approach that adapts to varying sequence lengths while preserving contextual integrity. Comprehensive experiments demonstrate that CoT2Align outperforms existing KD methods across different vocabulary settings, improving reasoning capabilities and robustness in domain-specific tasks.