 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting Ensemble Diversity with Interactive Bayesian Distributional Robustness for Fine-tuning Foundation Models
Jun 08, 2025We introduce Interactive Bayesian Distributional Robustness (IBDR), a novel Bayesian inference framework that allows modeling the interactions between particles, thereby enhancing ensemble quality through increased particle diversity. IBDR is grounded in a generalized theoretical framework that connects the distributional population loss with the approximate posterior, motivating a practical dual optimization procedure that enforces distributional robustness while fostering particle diversity. We evaluate IBDR's performance against various baseline methods using the VTAB-1K benchmark and the common reasoning language task. The results consistently show that IBDR outperforms these baselines, underscoring its effectiveness in real-world applications.
Few-Shot, No Problem: Descriptive Continual Relation Extraction
Feb 27, 2025Few-shot Continual Relation Extraction is a crucial challenge for enabling AI systems to identify and adapt to evolving relationships in dynamic real-world domains. Traditional memory-based approaches often overfit to limited samples, failing to reinforce old knowledge, with the scarcity of data in few-shot scenarios further exacerbating these issues by hindering effective data augmentation in the latent space. In this paper, we propose a novel retrieval-based solution, starting with a large language model to generate descriptions for each relation. From these descriptions, we introduce a bi-encoder retrieval training paradigm to enrich both sample and class representation learning. Leveraging these enhanced representations, we design a retrieval-based prediction method where each sample "retrieves" the best fitting relation via a reciprocal rank fusion score that integrates both relation description vectors and class prototypes. Extensive experiments on multiple datasets demonstrate that our method significantly advances the state-of-the-art by maintaining robust performance across sequential tasks, effectively addressing catastrophic forgetting.
Few-shot Continual Relation Extraction via Open Information Extraction
Feb 23, 2025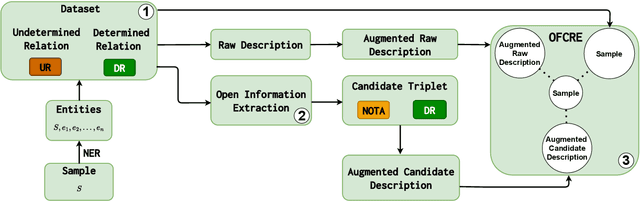
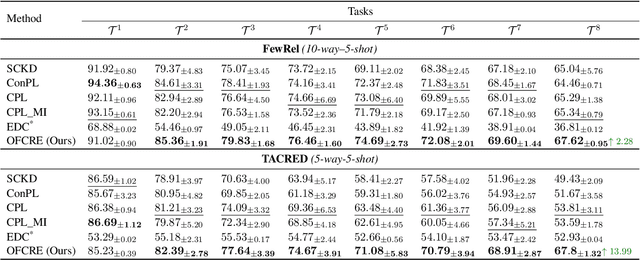
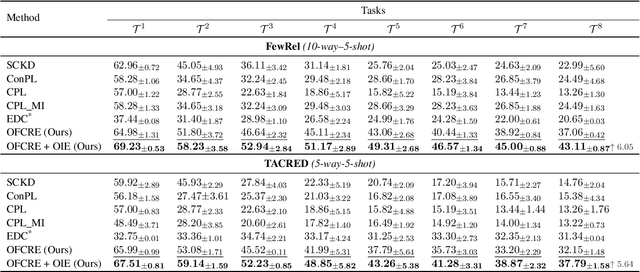
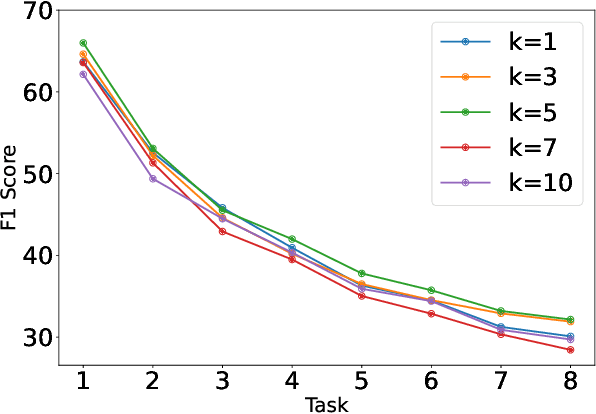
Typically, Few-shot Continual Relation Extraction (FCRE) models must balance retaining prior knowledge while adapting to new tasks with extremely limited data. However, real-world scenarios may also involve unseen or undetermined relations that existing methods still struggle to handle. To address these challenges, we propose a novel approach that leverages the Open Information Extraction concept of Knowledge Graph Construction (KGC). Our method not only exposes models to all possible pairs of relations, including determined and undetermined labels not available in the training set, but also enriches model knowledge with diverse relation descriptions, thereby enhancing knowledge retention and adaptability in this challenging scenario. In the perspective of KGC, this is the first work explored in the setting of Continual Learning, allowing efficient expansion of the graph as the data evolves. Experimental results demonstrate our superior performance compared to other state-of-the-art FCRE baselines, as well as the efficiency in handling dynamic graph construction in this setting.
Lifelong Event Detection via Optimal Transport
Oct 11, 2024



Continual Event Detection (CED) poses a formidable challenge due to the catastrophic forgetting phenomenon, where learning new tasks (with new coming event types) hampers performance on previous ones. In this paper, we introduce a novel approach, Lifelong Event Detection via Optimal Transport (LEDOT), that leverages optimal transport principles to align the optimization of our classification module with the intrinsic nature of each class, as defined by their pre-trained language modeling. Our method integrates replay sets, prototype latent representations, and an innovative Optimal Transport component. Extensive experiments on MAVEN and ACE datasets demonstrate LEDOT's superior performance, consistently outperforming state-of-the-art baselines. The results underscore LEDOT as a pioneering solution in continual event detection, offering a more effective and nuanced approach to addressing catastrophic forgetting in evolving environments.
Leveraging Hierarchical Taxonomies in Prompt-based Continual Learning
Oct 06, 2024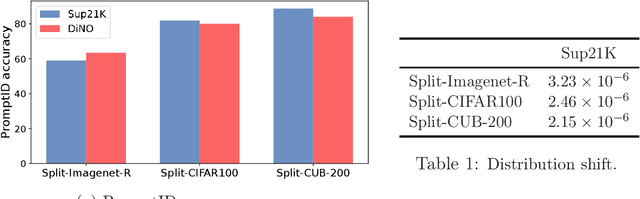
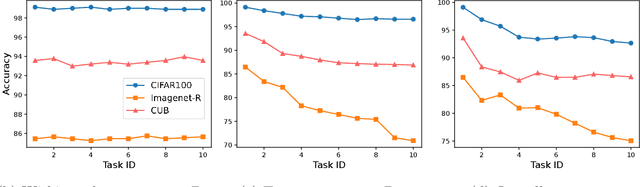
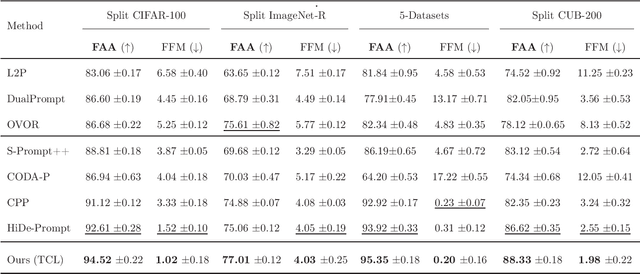
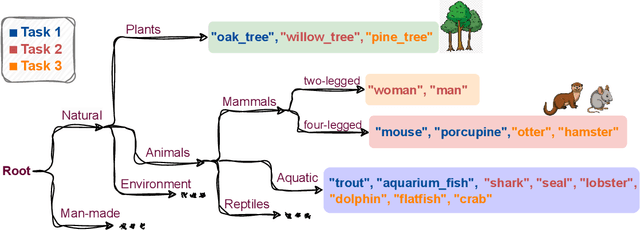
Drawing inspiration from human learning behaviors, this work proposes a novel approach to mitigate catastrophic forgetting in Prompt-based Continual Learning models by exploiting the relationships between continuously emerging class data. We find that applying human habits of organizing and connecting information can serve as an efficient strategy when training deep learning models. Specifically, by building a hierarchical tree structure based on the expanding set of labels, we gain fresh insights into the data, identifying groups of similar classes could easily cause confusion. Additionally, we delve deeper into the hidden connections between classes by exploring the original pretrained model's behavior through an optimal transport-based approach. From these insights, we propose a novel regularization loss function that encourages models to focus more on challenging knowledge areas, thereby enhancing overall performance. Experimentally, our method demonstrated significant superiority over the most robust state-of-the-art models on various benchmarks.
Improving Generalization with Flat Hilbert Bayesian Inference
Oct 05, 2024We introduce Flat Hilbert Bayesian Inference (FHBI), an algorithm designed to enhance generalization in Bayesian inference. Our approach involves an iterative two-step procedure with an adversarial functional perturbation step and a functional descent step within the reproducing kernel Hilbert spaces. This methodology is supported by a theoretical analysis that extends previous findings on generalization ability from finite-dimensional Euclidean spaces to infinite-dimensional functional spaces. To evaluate the effectiveness of FHBI, we conduct comprehensive comparisons against seven baseline methods on the VTAB-1K benchmark, which encompasses 19 diverse datasets across various domains with diverse semantics. Empirical results demonstrate that FHBI consistently outperforms the baselines by notable margins, highlighting its practical efficacy.
Revisiting Prefix-tuning: Statistical Benefits of Reparameterization among Prompts
Oct 03, 2024



Prompt-based techniques, such as prompt-tuning and prefix-tuning, have gained prominence for their efficiency in fine-tuning large pre-trained models. Despite their widespread adoption, the theoretical foundations of these methods remain limited. For instance, in prefix-tuning, we observe that a key factor in achieving performance parity with full fine-tuning lies in the reparameterization strategy. However, the theoretical principles underpinning the effectiveness of this approach have yet to be thoroughly examined. Our study demonstrates that reparameterization is not merely an engineering trick but is grounded in deep theoretical foundations. Specifically, we show that the reparameterization strategy implicitly encodes a shared structure between prefix key and value vectors. Building on recent insights into the connection between prefix-tuning and mixture of experts models, we further illustrate that this shared structure significantly improves sample efficiency in parameter estimation compared to non-shared alternatives. The effectiveness of prefix-tuning across diverse tasks is empirically confirmed to be enhanced by the shared structure, through extensive experiments in both visual and language domains. Additionally, we uncover similar structural benefits in prompt-tuning, offering new perspectives on its success. Our findings provide theoretical and empirical contributions, advancing the understanding of prompt-based methods and their underlying mechanisms.
Connective Viewpoints of Signal-to-Noise Diffusion Models
Aug 08, 2024



Diffusion models (DM) have become fundamental components of generative models, excelling across various domains such as image creation, audio generation, and complex data interpolation. Signal-to-Noise diffusion models constitute a diverse family covering most state-of-the-art diffusion models. While there have been several attempts to study Signal-to-Noise (S2N) diffusion models from various perspectives, there remains a need for a comprehensive study connecting different viewpoints and exploring new perspectives. In this study, we offer a comprehensive perspective on noise schedulers, examining their role through the lens of the signal-to-noise ratio (SNR) and its connections to information theory. Building upon this framework, we have developed a generalized backward equation to enhance the performance of the inference process.
Enhancing Domain Adaptation through Prompt Gradient Alignment
Jun 13, 2024Prior Unsupervised Domain Adaptation (UDA) methods often aim to train a domain-invariant feature extractor, which may hinder the model from learning sufficiently discriminative features. To tackle this, a line of works based on prompt learning leverages the power of large-scale pre-trained vision-language models to learn both domain-invariant and specific features through a set of domain-agnostic and domain-specific learnable prompts. Those studies typically enforce invariant constraints on representation, output, or prompt space to learn such prompts. Differently, we cast UDA as a multiple-objective optimization problem in which each objective is represented by a domain loss. Under this new framework, we propose aligning per-objective gradients to foster consensus between them. Additionally, to prevent potential overfitting when fine-tuning this deep learning architecture, we penalize the norm of these gradients. To achieve these goals, we devise a practical gradient update procedure that can work under both single-source and multi-source UDA. Empirically, our method consistently surpasses other prompt-based baselines by a large margin on different UDA benchmarks
Agnostic Sharpness-Aware Minimization
Jun 12, 2024Sharpness-aware minimization (SAM) has been instrumental in improving deep neural network training by minimizing both the training loss and the sharpness of the loss landscape, leading the model into flatter minima that are associated with better generalization properties. In another aspect, Model-Agnostic Meta-Learning (MAML) is a framework designed to improve the adaptability of models. MAML optimizes a set of meta-models that are specifically tailored for quick adaptation to multiple tasks with minimal fine-tuning steps and can generalize well with limited data. In this work, we explore the connection between SAM and MAML, particularly in terms of enhancing model generalization. We introduce Agnostic-SAM, a novel approach that combines the principles of both SAM and MAML. Agnostic-SAM adapts the core idea of SAM by optimizing the model towards wider local minima using training data, while concurrently maintaining low loss values on validation data. By doing so, it seeks flatter minima that are not only robust to small perturbations but also less vulnerable to data distributional shift problems. Our experimental results demonstrate that Agnostic-SAM significantly improves generalization over baselines across a range of datasets and under challenging conditions such as noisy labels and data limitation.