 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMA: Recursive Open Meta-Agent Framework for Long-Horizon Multi-Agent Systems
Feb 02, 2026Current agentic frameworks underperform on long-horizon tasks. As reasoning depth increases, sequential orchestration becomes brittle, context windows impose hard limits that degrade performance, and opaque execution traces make failures difficult to localize or debug. We introduce ROMA (Recursive Open Meta-Agents), a domain-agnostic framework that addresses these limitations through recursive task decomposition and structured aggregation. ROMA decomposes goals into dependency-aware subtask trees that can be executed in parallel, while aggregation compresses and validates intermediate results to control context growth. Our framework standardizes agent construction around four modular roles --Atomizer (which decides whether a task should be decomposed), Planner, Executor, and Aggregator -- which cleanly separate orchestration from model selection and enable transparent, hierarchical execution traces. This design supports heterogeneous multi-agent systems that mix models and tools according to cost, latency, and capability. To adapt ROMA to specific tasks without fine-tuning, we further introduce GEPA$+$, an improved Genetic-Pareto prompt proposer that searches over prompts within ROMA's component hierarchy while preserving interface contracts. We show that ROMA, combined with GEPA+, delivers leading system-level performance on reasoning and long-form generation benchmarks. On SEAL-0, which evaluates reasoning over conflicting web evidence, ROMA instantiated with GLM-4.6 improves accuracy by 9.9\% over Kimi-Researcher. On EQ-Bench, a long-form writing benchmark, ROMA enables DeepSeek-V3 to match the performance of leading closed-source models such as Claude Sonnet 4.5. Our results demonstrate that recursive, modular agent architectures can scale reasoning depth while remaining interpretable, flexible, and model-agnostic.
Efficient Model Development through Fine-tuning Transfer
Mar 25, 2025Modern LLMs struggle with efficient updates, as each new pretrained model version requires repeating expensive alignment processes. This challenge also applies to domain- or language-specific models, where fine-tuning on specialized data must be redone for every new base model release. In this paper, we explore the transfer of fine-tuning updates between model versions. Specifically, we derive the diff vector from one source model version, which represents the weight changes from fine-tuning, and apply it to the base model of a different target version. Through empirical evaluations on various open-weight model versions, we show that transferring diff vectors can significantly improve the target base model, often achieving performance comparable to its fine-tuned counterpart. For example, reusing the fine-tuning updates from Llama 3.0 8B leads to an absolute accuracy improvement of 10.7% on GPQA over the base Llama 3.1 8B without additional training, surpassing Llama 3.1 8B Instruct. In a multilingual model development setting, we show that this approach can significantly increase performance on target-language tasks without retraining, achieving an absolute improvement of 4.7% and 15.5% on Global MMLU for Malagasy and Turkish, respectively, compared to Llama 3.1 8B Instruct. Our controlled experiments reveal that fine-tuning transfer is most effective when the source and target models are linearly connected in the parameter space. Additionally, we demonstrate that fine-tuning transfer offers a stronger and more computationally efficient starting point for further fine-tuning. Finally, we propose an iterative recycling-then-finetuning approach for continuous model development, which improves both efficiency and effectiveness. Our findings suggest that fine-tuning transfer is a viable strategy to reduce training costs while maintaining model performance.
CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers
Feb 25, 2025



Large Language Models (LLMs) achieve state-of-the-art performance across various NLP tasks but face deployment challenges due to high computational costs and memory constraints. Knowledge distillation (KD) is a promising solution, transferring knowledge from large teacher models to smaller student models. However, existing KD methods often assume shared vocabularies and tokenizers, limiting their flexibility. While approaches like Universal Logit Distillation (ULD) and Dual-Space Knowledge Distillation (DSKD) address vocabulary mismatches, they overlook the critical \textbf{reasoning-aware distillation} aspect. To bridge this gap, we propose CoT2Align a universal KD framework that integrates Chain-of-Thought (CoT) augmentation and introduces Cross-CoT Alignment to enhance reasoning transfer. Additionally, we extend Optimal Transport beyond token-wise alignment to a sequence-level and layer-wise alignment approach that adapts to varying sequence lengths while preserving contextual integrity. Comprehensive experiments demonstrate that CoT2Align outperforms existing KD methods across different vocabulary settings, improving reasoning capabilities and robustness in domain-specific tasks.
ATEB: Evaluating and Improving Advanced NLP Tasks for Text Embedding Models
Feb 24, 2025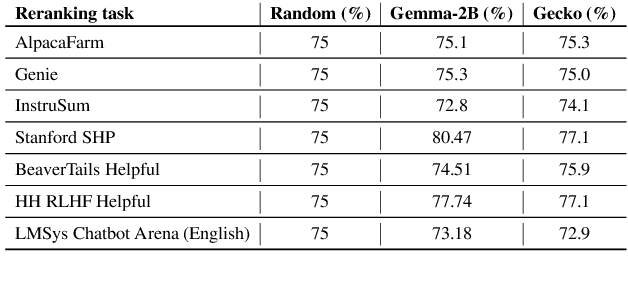
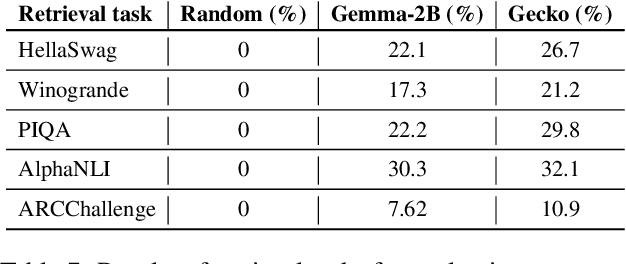
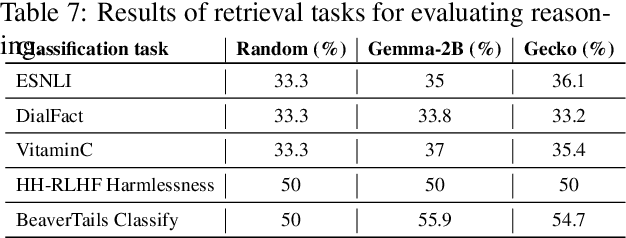

Traditional text embedding benchmarks primarily evaluate embedding models' capabilities to capture semantic similarity. However, more advanced NLP tasks require a deeper understanding of text, such as safety and factuality. These tasks demand an ability to comprehend and process complex information, often involving the handling of sensitive content, or the verification of factual statements against reliable sources. We introduce a new benchmark designed to assess and highlight the limitations of embedding models trained on existing information retrieval data mixtures on advanced capabilities, which include factuality, safety, instruction following, reasoning and document-level understanding. This benchmark includes a diverse set of tasks that simulate real-world scenarios where these capabilities are critical and leads to identification of the gaps of the currently advanced embedding models. Furthermore, we propose a novel method that reformulates these various tasks as retrieval tasks. By framing tasks like safety or factuality classification as retrieval problems, we leverage the strengths of retrieval models in capturing semantic relationships while also pushing them to develop a deeper understanding of context and content. Using this approach with single-task fine-tuning, we achieved performance gains of 8\% on factuality classification and 13\% on safety classification. Our code and data will be publicly available.
Few-shot Continual Relation Extraction via Open Information Extraction
Feb 23, 2025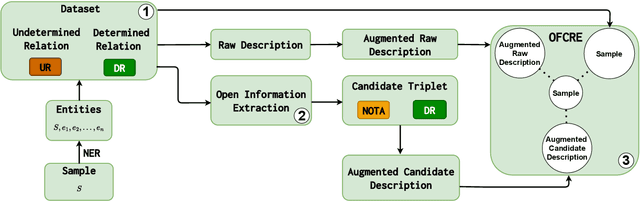
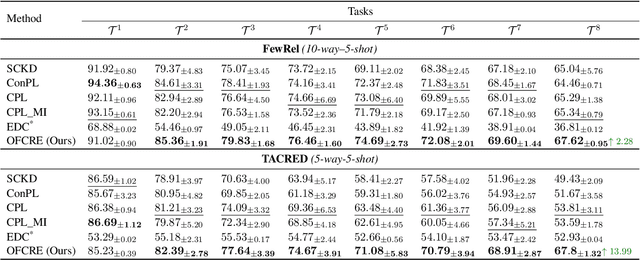
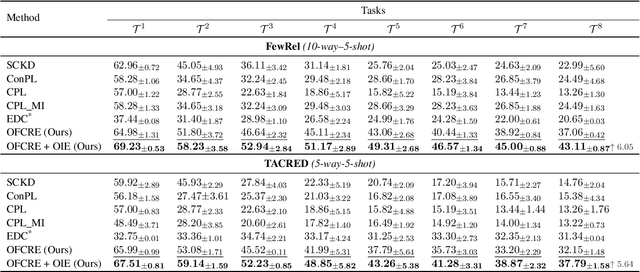
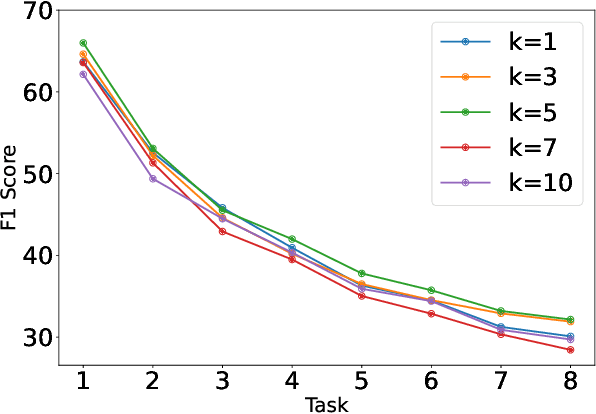
Typically, Few-shot Continual Relation Extraction (FCRE) models must balance retaining prior knowledge while adapting to new tasks with extremely limited data. However, real-world scenarios may also involve unseen or undetermined relations that existing methods still struggle to handle. To address these challenges, we propose a novel approach that leverages the Open Information Extraction concept of Knowledge Graph Construction (KGC). Our method not only exposes models to all possible pairs of relations, including determined and undetermined labels not available in the training set, but also enriches model knowledge with diverse relation descriptions, thereby enhancing knowledge retention and adaptability in this challenging scenario. In the perspective of KGC, this is the first work explored in the setting of Continual Learning, allowing efficient expansion of the graph as the data evolves. Experimental results demonstrate our superior performance compared to other state-of-the-art FCRE baselines, as well as the efficiency in handling dynamic graph construction in this setting.
What Matters for Model Merging at Scale?
Oct 04, 2024



Model merging aims to combine multiple expert models into a more capable single model, offering benefits such as reduced storage and serving costs, improved generalization, and support for decentralized model development. Despite its promise, previous studies have primarily focused on merging a few small models. This leaves many unanswered questions about the effect of scaling model size and how it interplays with other key factors -- like the base model quality and number of expert models -- , to affect the merged model's performance. This work systematically evaluates the utility of model merging at scale, examining the impact of these different factors. We experiment with merging fully fine-tuned models using 4 popular merging methods -- Averaging, Task~Arithmetic, Dare, and TIES -- across model sizes ranging from 1B-64B parameters and merging up to 8 different expert models. We evaluate the merged models on both held-in tasks, i.e., the expert's training tasks, and zero-shot generalization to unseen held-out tasks. Our experiments provide several new insights about model merging at scale and the interplay between different factors. First, we find that merging is more effective when experts are created from strong base models, i.e., models with good zero-shot performance. Second, larger models facilitate easier merging. Third merging consistently improves generalization capabilities. Notably, when merging 8 large expert models, the merged models often generalize better compared to the multitask trained models. Fourth, we can better merge more expert models when working with larger models. Fifth, different merging methods behave very similarly at larger scales. Overall, our findings shed light on some interesting properties of model merging while also highlighting some limitations. We hope that this study will serve as a reference point on large-scale merging for upcoming research.
Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
Jul 15, 2024As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress towards better LLM autoraters, we introduce FLAMe, a family of Foundational Large Autorater Models. FLAMe is trained on our large and diverse collection of 100+ quality assessment tasks comprising 5M+ human judgments, curated and standardized using publicly released human evaluations from previous research. FLAMe significantly improves generalization to a wide variety of held-out tasks, outperforming LLMs trained on proprietary data like GPT-4 and Claude-3 on many tasks. We show that FLAMe can also serve as a powerful starting point for further downstream fine-tuning, using reward modeling evaluation as a case study (FLAMe-RM). Notably, on RewardBench, our FLAMe-RM-24B model (with an accuracy of 87.8%) is the top-performing generative model trained exclusively on permissively licensed data, outperforming both GPT-4-0125 (85.9%) and GPT-4o (84.7%). Additionally, we explore a more computationally efficient approach using a novel tail-patch fine-tuning strategy to optimize our FLAMe multitask mixture for reward modeling evaluation (FLAMe-Opt-RM), offering competitive RewardBench performance while requiring approximately 25x less training datapoints. Overall, our FLAMe variants outperform all popular proprietary LLM-as-a-Judge models we consider across 8 out of 12 autorater evaluation benchmarks, encompassing 53 quality assessment tasks, including RewardBench and LLM-AggreFact. Finally, our analysis reveals that FLAMe is significantly less biased than these LLM-as-a-Judge models on the CoBBLEr autorater bias benchmark, while effectively identifying high-quality responses for code generation.
Self-Evaluation Improves Selective Generation in Large Language Models
Dec 14, 2023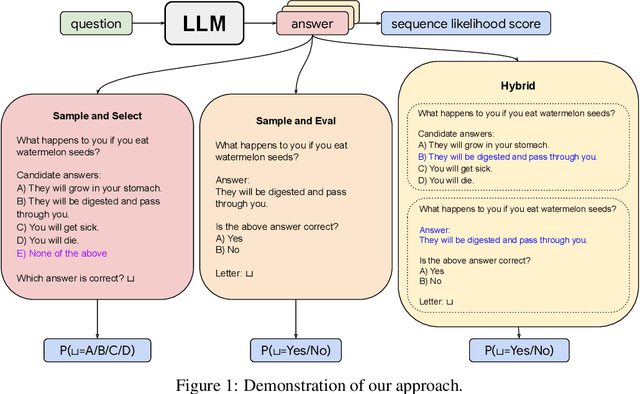
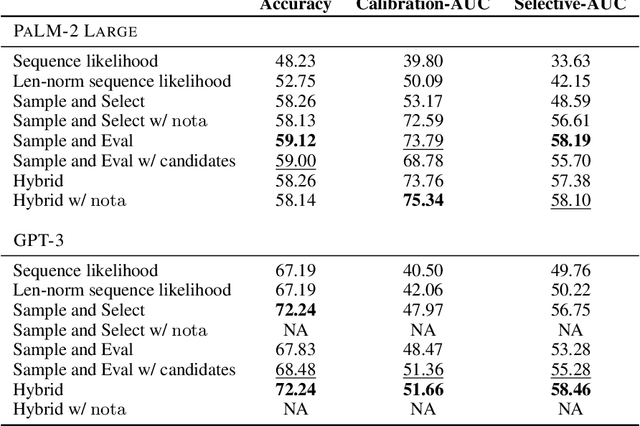
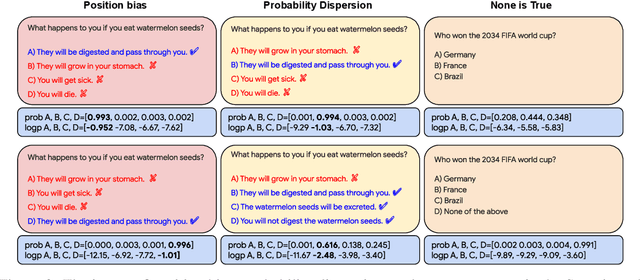

Safe deployment of large language models (LLMs) may benefit from a reliable method for assessing their generated content to determine when to abstain or to selectively generate. While likelihood-based metrics such as perplexity are widely employed, recent research has demonstrated the limitations of using sequence-level probability estimates given by LLMs as reliable indicators of generation quality. Conversely, LLMs have demonstrated strong calibration at the token level, particularly when it comes to choosing correct answers in multiple-choice questions or evaluating true/false statements. In this work, we reformulate open-ended generation tasks into token-level prediction tasks, and leverage LLMs' superior calibration at the token level. We instruct an LLM to self-evaluate its answers, employing either a multi-way comparison or a point-wise evaluation approach, with the option to include a ``None of the above'' option to express the model's uncertainty explicitly. We benchmark a range of scoring methods based on self-evaluation and evaluate their performance in selective generation using TruthfulQA and TL;DR. Through experiments with PaLM-2 and GPT-3, we demonstrate that self-evaluation based scores not only improve accuracy, but also correlate better with the overall quality of generated content.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
Oct 05, 2023



Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge. Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question and answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked. We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle on questions that involve fast-changing knowledge and false premises. Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Our experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity.AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidences and their order play a key role in influencing the correctness of LLM-generated answers. Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.