 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025



Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
What Matters for Model Merging at Scale?
Oct 04, 2024



Model merging aims to combine multiple expert models into a more capable single model, offering benefits such as reduced storage and serving costs, improved generalization, and support for decentralized model development. Despite its promise, previous studies have primarily focused on merging a few small models. This leaves many unanswered questions about the effect of scaling model size and how it interplays with other key factors -- like the base model quality and number of expert models -- , to affect the merged model's performance. This work systematically evaluates the utility of model merging at scale, examining the impact of these different factors. We experiment with merging fully fine-tuned models using 4 popular merging methods -- Averaging, Task~Arithmetic, Dare, and TIES -- across model sizes ranging from 1B-64B parameters and merging up to 8 different expert models. We evaluate the merged models on both held-in tasks, i.e., the expert's training tasks, and zero-shot generalization to unseen held-out tasks. Our experiments provide several new insights about model merging at scale and the interplay between different factors. First, we find that merging is more effective when experts are created from strong base models, i.e., models with good zero-shot performance. Second, larger models facilitate easier merging. Third merging consistently improves generalization capabilities. Notably, when merging 8 large expert models, the merged models often generalize better compared to the multitask trained models. Fourth, we can better merge more expert models when working with larger models. Fifth, different merging methods behave very similarly at larger scales. Overall, our findings shed light on some interesting properties of model merging while also highlighting some limitations. We hope that this study will serve as a reference point on large-scale merging for upcoming research.
Language and Task Arithmetic with Parameter-Efficient Layers for Zero-Shot Summarization
Nov 15, 2023

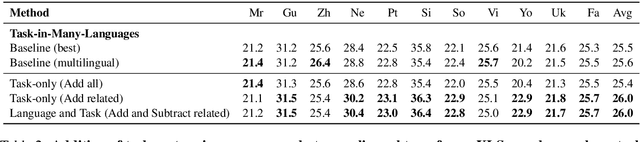

Parameter-efficient fine-tuning (PEFT) using labeled task data can significantly improve the performance of large language models (LLMs) on the downstream task. However, there are 7000 languages in the world and many of these languages lack labeled data for real-world language generation tasks. In this paper, we propose to improve zero-shot cross-lingual transfer by composing language or task specialized parameters. Our method composes language and task PEFT modules via element-wise arithmetic operations to leverage unlabeled data and English labeled data. We extend our approach to cases where labeled data from more languages is available and propose to arithmetically compose PEFT modules trained on languages related to the target. Empirical results on summarization demonstrate that our method is an effective strategy that obtains consistent gains using minimal training of PEFT modules.
On the Copying Problem of Unsupervised NMT: A Training Schedule with a Language Discriminator Loss
Jun 04, 2023

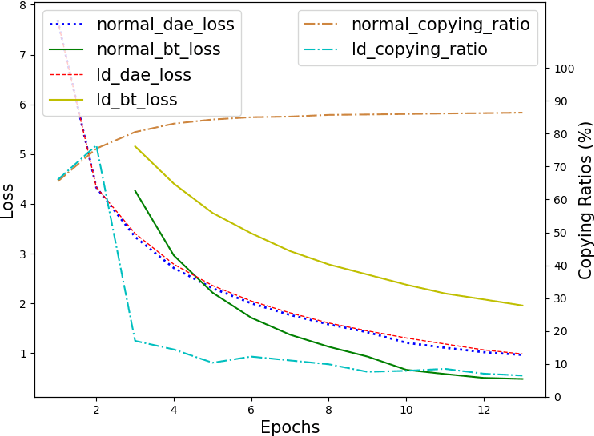

Although unsupervised neural machine translation (UNMT) has achieved success in many language pairs, the copying problem, i.e., directly copying some parts of the input sentence as the translation, is common among distant language pairs, especially when low-resource languages are involved. We find this issue is closely related to an unexpected copying behavior during online back-translation (BT). In this work, we propose a simple but effective training schedule that incorporates a language discriminator loss. The loss imposes constraints on the intermediate translation so that the translation is in the desired language. By conducting extensive experiments on different language pairs, including similar and distant, high and low-resource languages, we find that our method alleviates the copying problem, thus improving the translation performance on low-resource languages.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023



To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Mitigating Data Imbalance and Representation Degeneration in Multilingual Machine Translation
May 22, 2023



Despite advances in multilingual neural machine translation (MNMT), we argue that there are still two major challenges in this area: data imbalance and representation degeneration. The data imbalance problem refers to the imbalance in the amount of parallel corpora for all language pairs, especially for long-tail languages (i.e., very low-resource languages). The representation degeneration problem refers to the problem of encoded tokens tending to appear only in a small subspace of the full space available to the MNMT model. To solve these two issues, we propose Bi-ACL, a framework that uses only target-side monolingual data and a bilingual dictionary to improve the performance of the MNMT model. We define two modules, named bidirectional autoencoder and bidirectional contrastive learning, which we combine with an online constrained beam search and a curriculum learning sampling strategy. Extensive experiments show that our proposed method is more effective both in long-tail languages and in high-resource languages. We also demonstrate that our approach is capable of transferring knowledge between domains and languages in zero-shot scenarios.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
AdapterSoup: Weight Averaging to Improve Generalization of Pretrained Language Models
Feb 14, 2023



Pretrained language models (PLMs) are trained on massive corpora, but often need to specialize to specific domains. A parameter-efficient adaptation method suggests training an adapter for each domain on the task of language modeling. This leads to good in-domain scores but can be impractical for domain- or resource-restricted settings. A solution is to use a related-domain adapter for the novel domain at test time. In this paper, we introduce AdapterSoup, an approach that performs weight-space averaging of adapters trained on different domains. Our approach is embarrassingly parallel: first, we train a set of domain-specific adapters; then, for each novel domain, we determine which adapters should be averaged at test time. We present extensive experiments showing that AdapterSoup consistently improves performance to new domains without extra training. We also explore weight averaging of adapters trained on the same domain with different hyper-parameters, and show that it preserves the performance of a PLM on new domains while obtaining strong in-domain results. We explore various approaches for choosing which adapters to combine, such as text clustering and semantic similarity. We find that using clustering leads to the most competitive results on novel domains.
Language-Family Adapters for Multilingual Neural Machine Translation
Sep 30, 2022
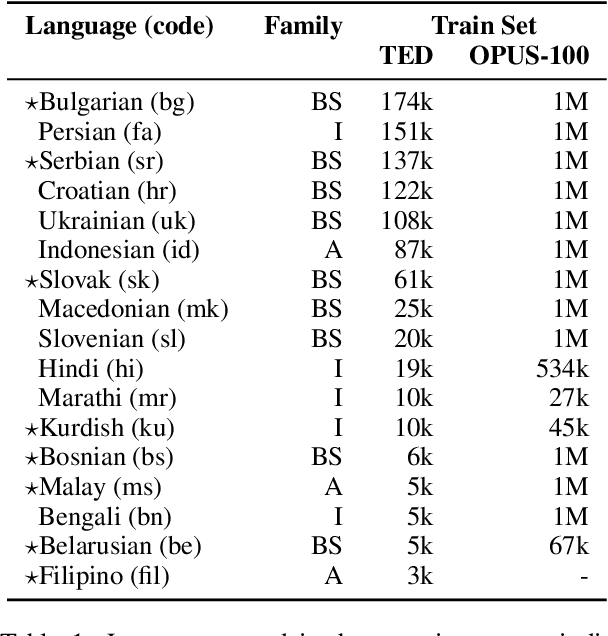
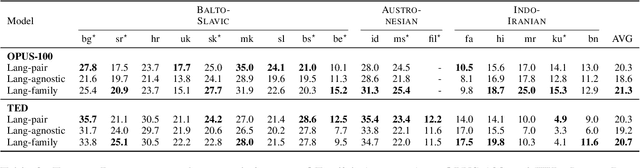
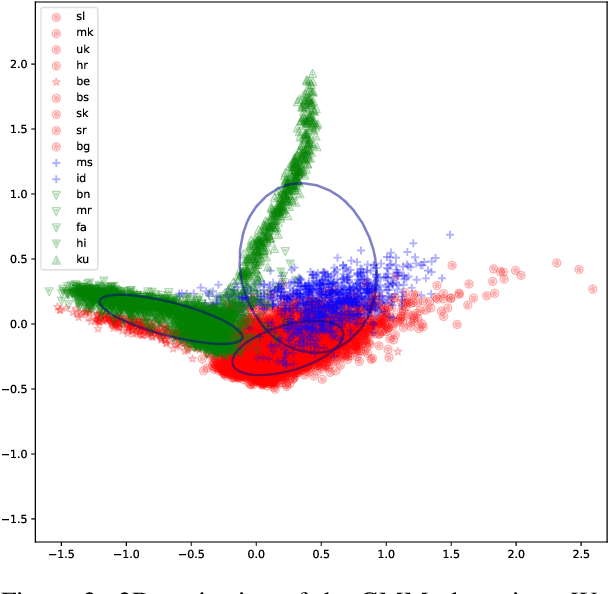
Massively multilingual models pretrained on abundant corpora with self-supervision achieve state-of-the-art results in a wide range of natural language processing tasks. In machine translation, multilingual pretrained models are often fine-tuned on parallel data from one or multiple language pairs. Multilingual fine-tuning improves performance on medium- and low-resource languages but requires modifying the entire model and can be prohibitively expensive. Training a new set of adapters on each language pair or training a single set of adapters on all language pairs while keeping the pretrained model's parameters frozen has been proposed as a parameter-efficient alternative. However, the former do not permit any sharing between languages, while the latter share parameters for all languages and have to deal with negative interference. In this paper, we propose training language-family adapters on top of a pretrained multilingual model to facilitate cross-lingual transfer. Our model consistently outperforms other adapter-based approaches. We also demonstrate that language-family adapters provide an effective method to translate to languages unseen during pretraining.
Efficient Hierarchical Domain Adaptation for Pretrained Language Models
Dec 16, 2021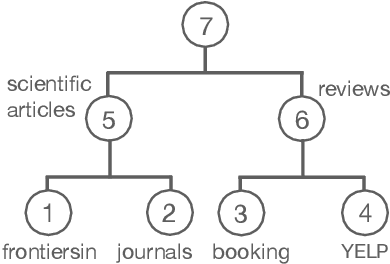
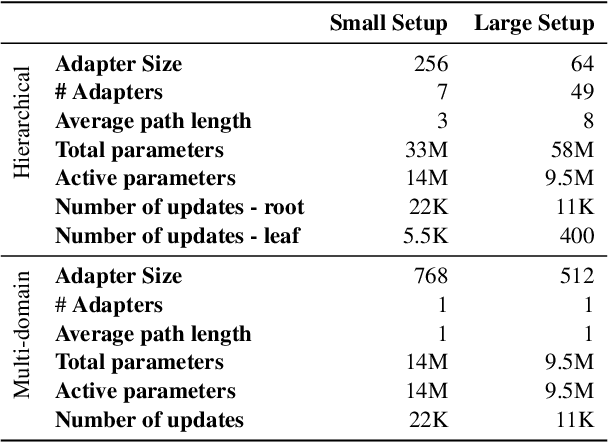


Generative language models are trained on diverse, general domain corpora. However, this limits their applicability to narrower domains, and prior work has shown that continued in-domain training can provide further gains. In this paper, we introduce a method to scale domain adaptation to many diverse domains using a computationally efficient adapter approach. Our method is based on the observation that textual domains are partially overlapping, and we represent domains as a hierarchical tree structure where each node in the tree is associated with a set of adapter weights. When combined with a frozen pretrained language model, this approach enables parameter sharing among related domains, while avoiding negative interference between unrelated ones. It is efficient and computational cost scales as O(log(D)) for D domains. Experimental results with GPT-2 and a large fraction of the 100 most represented websites in C4 show across-the-board improvements in-domain. We additionally provide an inference time algorithm for a held-out domain and show that averaging over multiple paths through the tree enables further gains in generalization, while adding only a marginal cost to inference.