 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
DOLOMITES: Domain-Specific Long-Form Methodical Tasks
May 09, 2024Experts in various fields routinely perform methodical writing tasks to plan, organize, and report their work. From a clinician writing a differential diagnosis for a patient, to a teacher writing a lesson plan for students, these tasks are pervasive, requiring to methodically generate structured long-form output for a given input. We develop a typology of methodical tasks structured in the form of a task objective, procedure, input, and output, and introduce DoLoMiTes, a novel benchmark with specifications for 519 such tasks elicited from hundreds of experts from across 25 fields. Our benchmark further contains specific instantiations of methodical tasks with concrete input and output examples (1,857 in total) which we obtain by collecting expert revisions of up to 10 model-generated examples of each task. We use these examples to evaluate contemporary language models highlighting that automating methodical tasks is a challenging long-form generation problem, as it requires performing complex inferences, while drawing upon the given context as well as domain knowledge.
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Apr 07, 2024Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Language and Task Arithmetic with Parameter-Efficient Layers for Zero-Shot Summarization
Nov 15, 2023

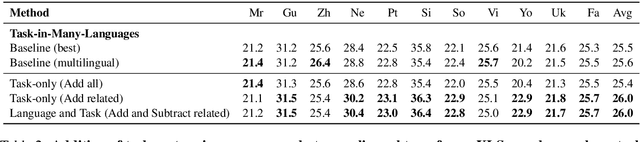

Parameter-efficient fine-tuning (PEFT) using labeled task data can significantly improve the performance of large language models (LLMs) on the downstream task. However, there are 7000 languages in the world and many of these languages lack labeled data for real-world language generation tasks. In this paper, we propose to improve zero-shot cross-lingual transfer by composing language or task specialized parameters. Our method composes language and task PEFT modules via element-wise arithmetic operations to leverage unlabeled data and English labeled data. We extend our approach to cases where labeled data from more languages is available and propose to arithmetically compose PEFT modules trained on languages related to the target. Empirical results on summarization demonstrate that our method is an effective strategy that obtains consistent gains using minimal training of PEFT modules.
Benchmarking Large Language Model Capabilities for Conditional Generation
Jun 29, 2023Pre-trained large language models (PLMs) underlie most new developments in natural language processing. They have shifted the field from application-specific model pipelines to a single model that is adapted to a wide range of tasks. Autoregressive PLMs like GPT-3 or PaLM, alongside techniques like few-shot learning, have additionally shifted the output modality to generation instead of classification or regression. Despite their ubiquitous use, the generation quality of language models is rarely evaluated when these models are introduced. Additionally, it is unclear how existing generation tasks--while they can be used to compare systems at a high level--relate to the real world use cases for which people have been adopting them. In this work, we discuss how to adapt existing application-specific generation benchmarks to PLMs and provide an in-depth, empirical study of the limitations and capabilities of PLMs in natural language generation tasks along dimensions such as scale, architecture, input and output language. Our results show that PLMs differ in their applicability to different data regimes and their generalization to multiple languages and inform which PLMs to use for a given generation task setup. We share best practices to be taken into consideration when benchmarking generation capabilities during the development of upcoming PLMs.
$μ$PLAN: Summarizing using a Content Plan as Cross-Lingual Bridge
May 23, 2023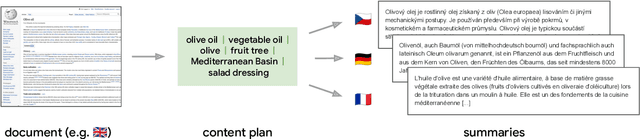


Cross-lingual summarization consists of generating a summary in one language given an input document in a different language, allowing for the dissemination of relevant content across speakers of other languages. However, this task remains challenging, mainly because of the need for cross-lingual datasets and the compounded difficulty of summarizing and translating. This work presents $\mu$PLAN, an approach to cross-lingual summarization that uses an intermediate planning step as a cross-lingual bridge. We formulate the plan as a sequence of entities that captures the conceptualization of the summary, i.e. identifying the salient content and expressing in which order to present the information, separate from the surface form. Using a multilingual knowledge base, we align the entities to their canonical designation across languages. $\mu$PLAN models first learn to generate the plan and then continue generating the summary conditioned on the plan and the input. We evaluate our methodology on the XWikis dataset on cross-lingual pairs across four languages and demonstrate that this planning objective achieves state-of-the-art performance in terms of ROUGE and faithfulness scores. Moreover, this planning approach improves the zero-shot transfer to new cross-lingual language pairs compared to non-planning baselines.
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
Curriculum Meta-Learning for Few-shot Classification
Dec 06, 2021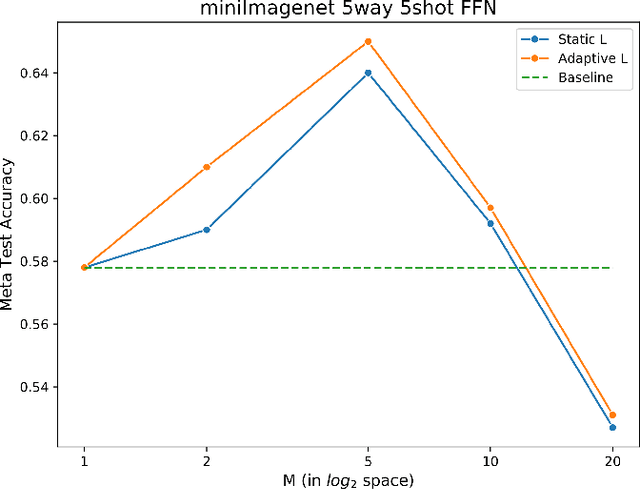

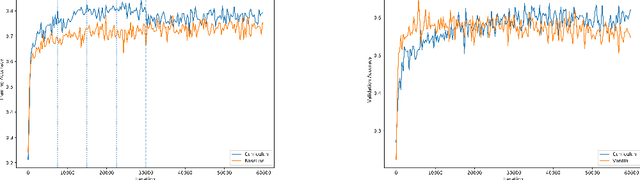
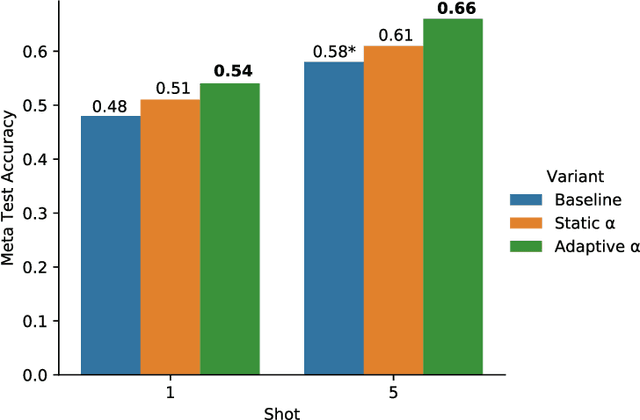
We propose an adaptation of the curriculum training framework, applicable to state-of-the-art meta learning techniques for few-shot classification. Curriculum-based training popularly attempts to mimic human learning by progressively increasing the training complexity to enable incremental concept learning. As the meta-learner's goal is learning how to learn from as few samples as possible, the exact number of those samples (i.e. the size of the support set) arises as a natural proxy of a given task's difficulty. We define a simple yet novel curriculum schedule that begins with a larger support size and progressively reduces it throughout training to eventually match the desired shot-size of the test setup. This proposed method boosts the learning efficiency as well as the generalization capability. Our experiments with the MAML algorithm on two few-shot image classification tasks show significant gains with the curriculum training framework. Ablation studies corroborate the independence of our proposed method from the model architecture as well as the meta-learning hyperparameters
OmniNet: A unified architecture for multi-modal multi-task learning
Jul 17, 2019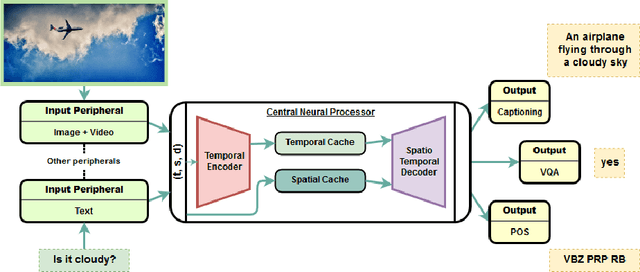

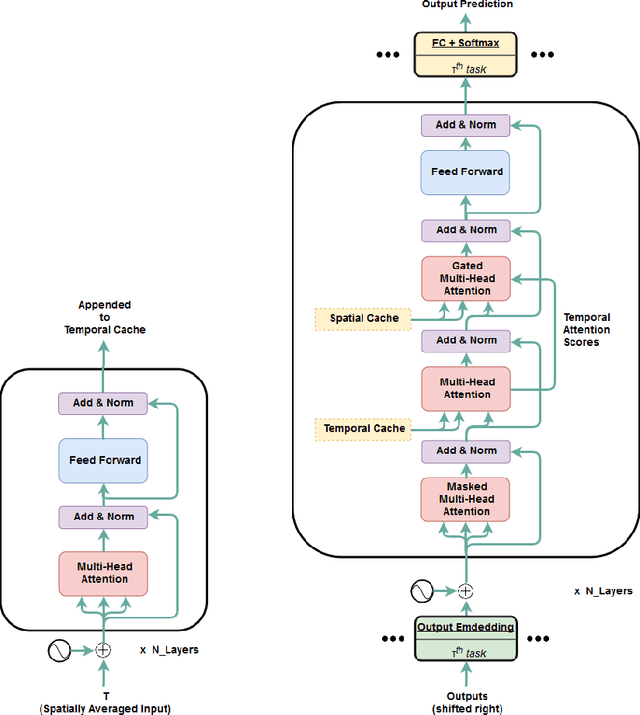

Transformer is a popularly used neural network architecture, especially for language understanding. We introduce an extended and unified architecture which can be used for tasks involving a variety of modalities like image, text, videos, etc. We propose a spatio-temporal cache mechanism that enables learning spatial dimension of the input in addition to the hidden states corresponding to the temporal input sequence. The proposed architecture further enables a single model to support tasks with multiple input modalities as well as asynchronous multi-task learning, thus we refer to it as OmniNet. For example, a single instance of OmniNet can concurrently learn to perform the tasks of part-of-speech tagging, image captioning, visual question answering and video activity recognition. We demonstrate that training these four tasks together results in about three times compressed model while retaining the performance in comparison to training them individually. We also show that using this neural network pre-trained on some modalities assists in learning an unseen task. This illustrates the generalization capacity of the self-attention mechanism on the spatio-temporal cache present in OmniNet.