 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Linear Transformers
Oct 24, 2023The self-attention mechanism in the transformer architecture is capable of capturing long-range dependencies and it is the main reason behind its effectiveness in processing sequential data. Nevertheless, despite their success, transformers have two significant drawbacks that still limit their broader applicability: (1) In order to remember past information, the self-attention mechanism requires access to the whole history to be provided as context. (2) The inference cost in transformers is expensive. In this paper we introduce recurrent alternatives to the transformer self-attention mechanism that offer a context-independent inference cost, leverage long-range dependencies effectively, and perform well in practice. We evaluate our approaches in reinforcement learning problems where the aforementioned computational limitations make the application of transformers nearly infeasible. We quantify the impact of the different components of our architecture in a diagnostic environment and assess performance gains in 2D and 3D pixel-based partially-observable environments. When compared to a state-of-the-art architecture, GTrXL, inference in our approach is at least 40% cheaper while reducing memory use in more than 50%. Our approach either performs similarly or better than GTrXL, improving more than 37% upon GTrXL performance on harder tasks.
Towards a Multi-modal, Multi-task Learning based Pre-training Framework for Document Representation Learning
Sep 30, 2020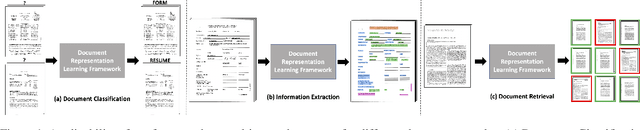

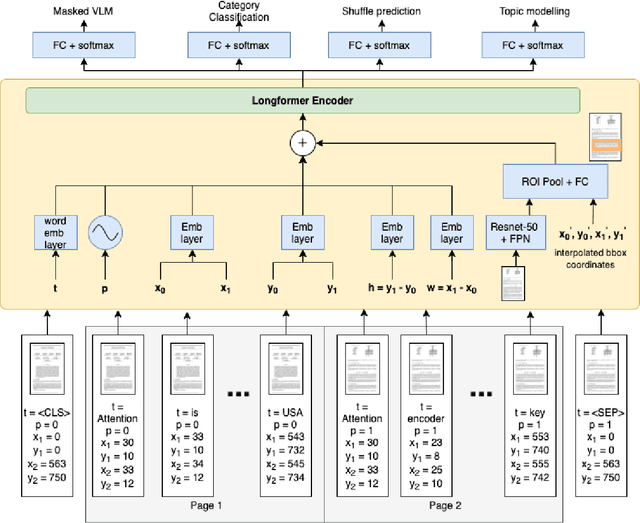

In this paper, we propose a multi-task learning-based framework that utilizes a combination of self-supervised and supervised pre-training tasks to learn a generic document representation. We design the network architecture and the pre-training tasks to incorporate the multi-modal document information across text, layout, and image dimensions and allow the network to work with multi-page documents. We showcase the applicability of our pre-training framework on a variety of different real-world document tasks such as document classification, document information extraction, and document retrieval. We conduct exhaustive experiments to compare performance against different ablations of our framework and state-of-the-art baselines. We discuss the current limitations and next steps for our work.
OmniNet: A unified architecture for multi-modal multi-task learning
Jul 17, 2019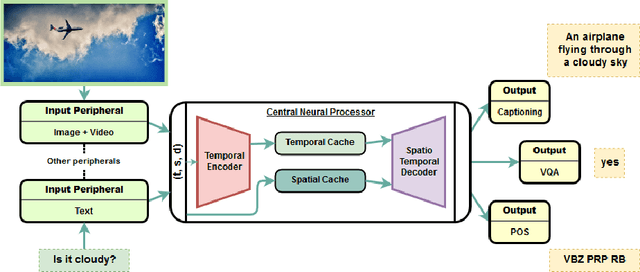

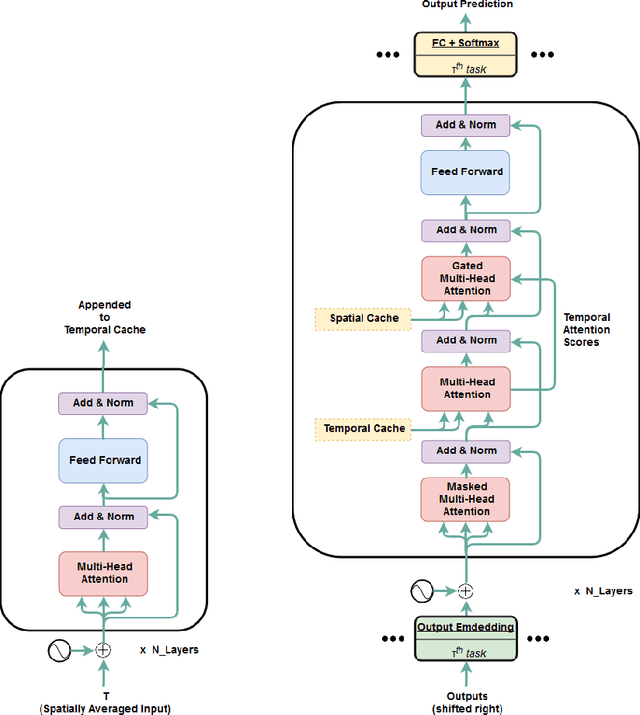

Transformer is a popularly used neural network architecture, especially for language understanding. We introduce an extended and unified architecture which can be used for tasks involving a variety of modalities like image, text, videos, etc. We propose a spatio-temporal cache mechanism that enables learning spatial dimension of the input in addition to the hidden states corresponding to the temporal input sequence. The proposed architecture further enables a single model to support tasks with multiple input modalities as well as asynchronous multi-task learning, thus we refer to it as OmniNet. For example, a single instance of OmniNet can concurrently learn to perform the tasks of part-of-speech tagging, image captioning, visual question answering and video activity recognition. We demonstrate that training these four tasks together results in about three times compressed model while retaining the performance in comparison to training them individually. We also show that using this neural network pre-trained on some modalities assists in learning an unseen task. This illustrates the generalization capacity of the self-attention mechanism on the spatio-temporal cache present in OmniNet.
Text Normalization using Memory Augmented Neural Networks
Jul 06, 2018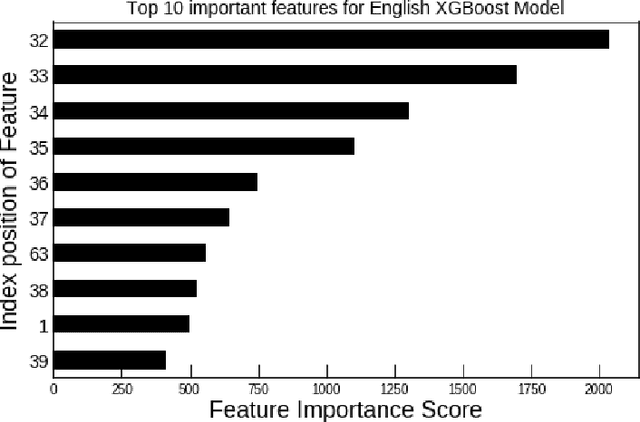

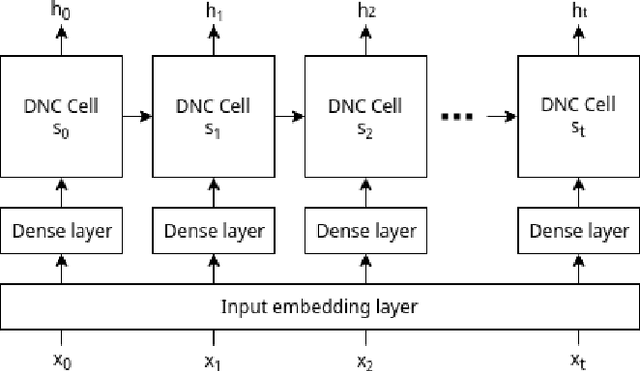
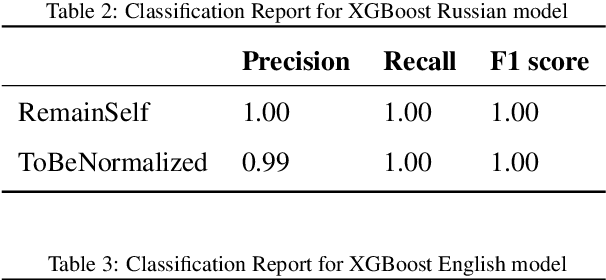
We perform text normalization, i.e. the transformation of words from the written to the spoken form, using a memory augmented neural network. With the addition of dynamic memory access and storage mechanism, we present a neural architecture that will serve as a language agnostic text normalization system while avoiding the kind of unacceptable errors made by the LSTM based recurrent neural networks. By reducing the number of unacceptable mistakes, we show that such a novel architecture is indeed a better alternative. Our proposed system requires significantly lesser amounts of data, training time and compute resources. Although a few occurrences of these errors still remain in certain semiotic classes, we demonstrate that memory augmented networks with meta-learning capabilities can open many doors to a superior text normalization system.