 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning without Performance Degradation
May 01, 2025



Fine-tuning policies learned offline remains a major challenge in application domains. Monotonic performance improvement during \emph{fine-tuning} is often challenging, as agents typically experience performance degradation at the early fine-tuning stage. The community has identified multiple difficulties in fine-tuning a learned network online, however, the majority of progress has focused on improving learning efficiency during fine-tuning. In practice, this comes at a serious cost during fine-tuning: initially, agent performance degrades as the agent explores and effectively overrides the policy learned offline. We show across a range of settings, many offline-to-online algorithms exhibit either (1) performance degradation or (2) slow learning (sometimes effectively no improvement) during fine-tuning. We introduce a new fine-tuning algorithm, based on an algorithm called Jump Start, that gradually allows more exploration based on online estimates of performance. Empirically, this approach achieves fast fine-tuning and significantly reduces performance degradations compared with existing algorithms designed to do the same.
A Method for Evaluating Hyperparameter Sensitivity in Reinforcement Learning
Dec 10, 2024



The performance of modern reinforcement learning algorithms critically relies on tuning ever-increasing numbers of hyperparameters. Often, small changes in a hyperparameter can lead to drastic changes in performance, and different environments require very different hyperparameter settings to achieve state-of-the-art performance reported in the literature. We currently lack a scalable and widely accepted approach to characterizing these complex interactions. This work proposes a new empirical methodology for studying, comparing, and quantifying the sensitivity of an algorithm's performance to hyperparameter tuning for a given set of environments. We then demonstrate the utility of this methodology by assessing the hyperparameter sensitivity of several commonly used normalization variants of PPO. The results suggest that several algorithmic performance improvements may, in fact, be a result of an increased reliance on hyperparameter tuning.
Real-Time Recurrent Learning using Trace Units in Reinforcement Learning
Sep 02, 2024



Recurrent Neural Networks (RNNs) are used to learn representations in partially observable environments. For agents that learn online and continually interact with the environment, it is desirable to train RNNs with real-time recurrent learning (RTRL); unfortunately, RTRL is prohibitively expensive for standard RNNs. A promising direction is to use linear recurrent architectures (LRUs), where dense recurrent weights are replaced with a complex-valued diagonal, making RTRL efficient. In this work, we build on these insights to provide a lightweight but effective approach for training RNNs in online RL. We introduce Recurrent Trace Units (RTUs), a small modification on LRUs that we nonetheless find to have significant performance benefits over LRUs when trained with RTRL. We find RTUs significantly outperform other recurrent architectures across several partially observable environments while using significantly less computation.
The Cross-environment Hyperparameter Setting Benchmark for Reinforcement Learning
Jul 26, 2024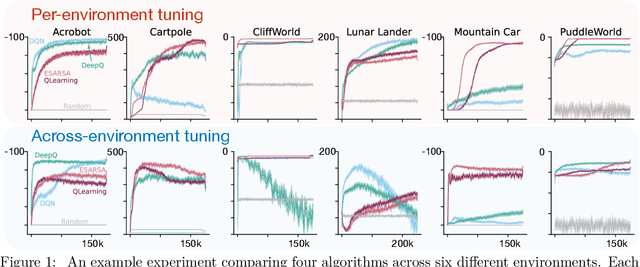
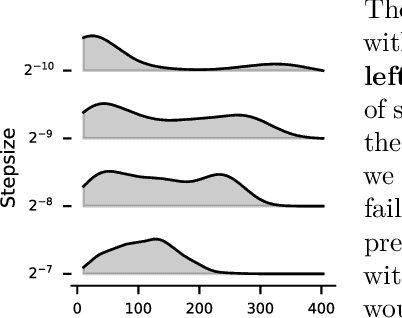
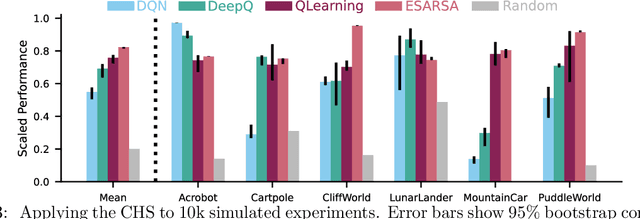
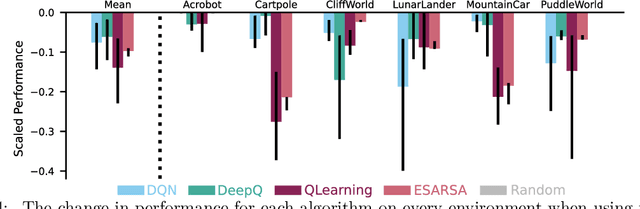
This paper introduces a new empirical methodology, the Cross-environment Hyperparameter Setting Benchmark, that compares RL algorithms across environments using a single hyperparameter setting, encouraging algorithmic development which is insensitive to hyperparameters. We demonstrate that this benchmark is robust to statistical noise and obtains qualitatively similar results across repeated applications, even when using few samples. This robustness makes the benchmark computationally cheap to apply, allowing statistically sound insights at low cost. We demonstrate two example instantiations of the CHS, on a set of six small control environments (SC-CHS) and on the entire DM Control suite of 28 environments (DMC-CHS). Finally, to illustrate the applicability of the CHS to modern RL algorithms on challenging environments, we conduct a novel empirical study of an open question in the continuous control literature. We show, with high confidence, that there is no meaningful difference in performance between Ornstein-Uhlenbeck noise and uncorrelated Gaussian noise for exploration with the DDPG algorithm on the DMC-CHS.
Investigating the Interplay of Prioritized Replay and Generalization
Jul 12, 2024



Experience replay is ubiquitous in reinforcement learning, to reuse past data and improve sample efficiency. Though a variety of smart sampling schemes have been introduced to improve performance, uniform sampling by far remains the most common approach. One exception is Prioritized Experience Replay (PER), where sampling is done proportionally to TD errors, inspired by the success of prioritized sweeping in dynamic programming. The original work on PER showed improvements in Atari, but follow-up results are mixed. In this paper, we investigate several variations on PER, to attempt to understand where and when PER may be useful. Our findings in prediction tasks reveal that while PER can improve value propagation in tabular settings, behavior is significantly different when combined with neural networks. Certain mitigations -- like delaying target network updates to control generalization and using estimates of expected TD errors in PER to avoid chasing stochasticity -- can avoid large spikes in error with PER and neural networks, but nonetheless generally do not outperform uniform replay. In control tasks, none of the prioritized variants consistently outperform uniform replay.
Position: Benchmarking is Limited in Reinforcement Learning Research
Jun 23, 2024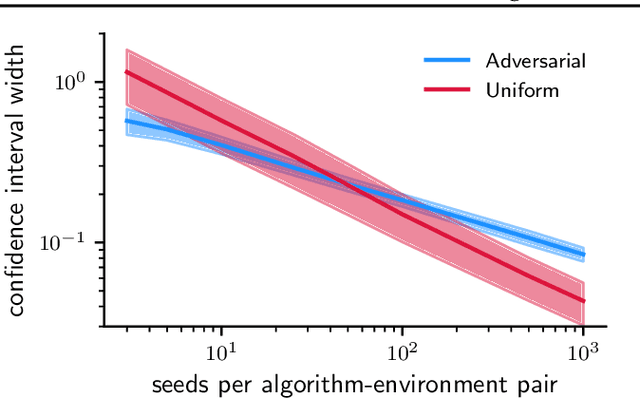

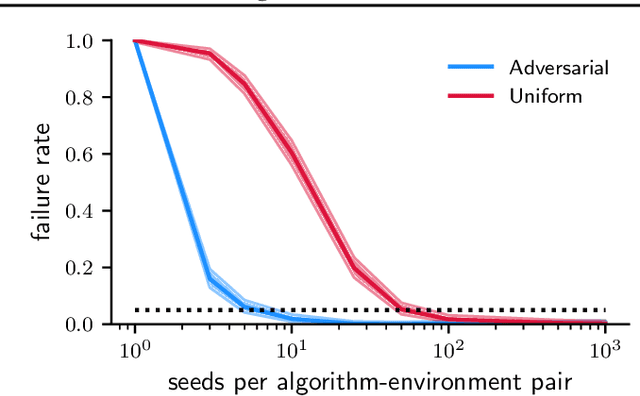
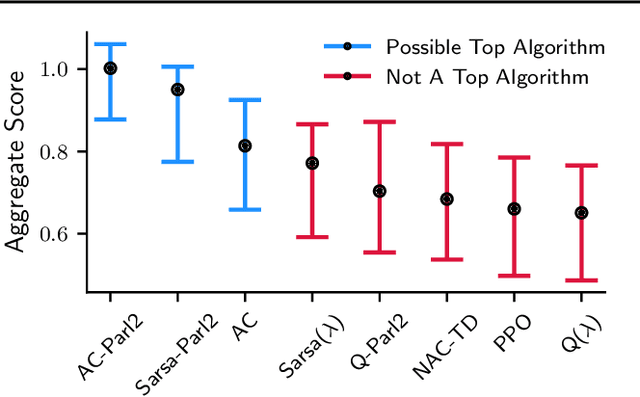
Novel reinforcement learning algorithms, or improvements on existing ones, are commonly justified by evaluating their performance on benchmark environments and are compared to an ever-changing set of standard algorithms. However, despite numerous calls for improvements, experimental practices continue to produce misleading or unsupported claims. One reason for the ongoing substandard practices is that conducting rigorous benchmarking experiments requires substantial computational time. This work investigates the sources of increased computation costs in rigorous experiment designs. We show that conducting rigorous performance benchmarks will likely have computational costs that are often prohibitive. As a result, we argue for using an additional experimentation paradigm to overcome the limitations of benchmarking.
A New View on Planning in Online Reinforcement Learning
Jun 03, 2024



This paper investigates a new approach to model-based reinforcement learning using background planning: mixing (approximate) dynamic programming updates and model-free updates, similar to the Dyna architecture. Background planning with learned models is often worse than model-free alternatives, such as Double DQN, even though the former uses significantly more memory and computation. The fundamental problem is that learned models can be inaccurate and often generate invalid states, especially when iterated many steps. In this paper, we avoid this limitation by constraining background planning to a set of (abstract) subgoals and learning only local, subgoal-conditioned models. This goal-space planning (GSP) approach is more computationally efficient, naturally incorporates temporal abstraction for faster long-horizon planning and avoids learning the transition dynamics entirely. We show that our GSP algorithm can propagate value from an abstract space in a manner that helps a variety of base learners learn significantly faster in different domains.
Tuning for the Unknown: Revisiting Evaluation Strategies for Lifelong RL
Apr 02, 2024



In continual or lifelong reinforcement learning access to the environment should be limited. If we aspire to design algorithms that can run for long-periods of time, continually adapting to new, unexpected situations then we must be willing to deploy our agents without tuning their hyperparameters over the agent's entire lifetime. The standard practice in deep RL -- and even continual RL -- is to assume unfettered access to deployment environment for the full lifetime of the agent. This paper explores the notion that progress in lifelong RL research has been held back by inappropriate empirical methodologies. In this paper we propose a new approach for tuning and evaluating lifelong RL agents where only one percent of the experiment data can be used for hyperparameter tuning. We then conduct an empirical study of DQN and Soft Actor Critic across a variety of continuing and non-stationary domains. We find both methods generally perform poorly when restricted to one-percent tuning, whereas several algorithmic mitigations designed to maintain network plasticity perform surprising well. In addition, we find that properties designed to measure the network's ability to learn continually indeed correlate with performance under one-percent tuning.
Application-Driven Innovation in Machine Learning
Mar 26, 2024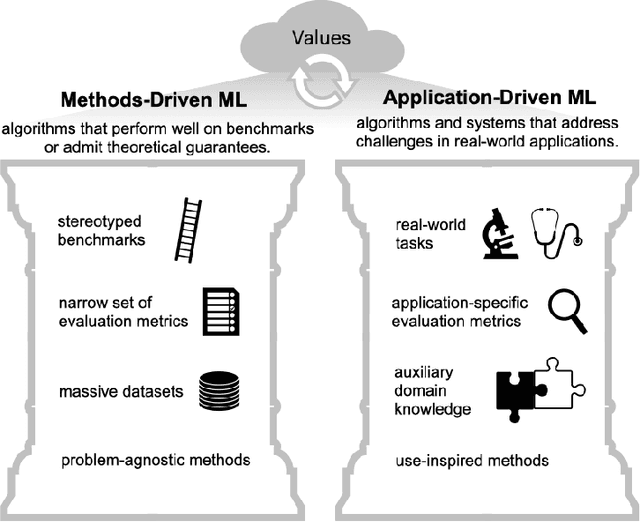
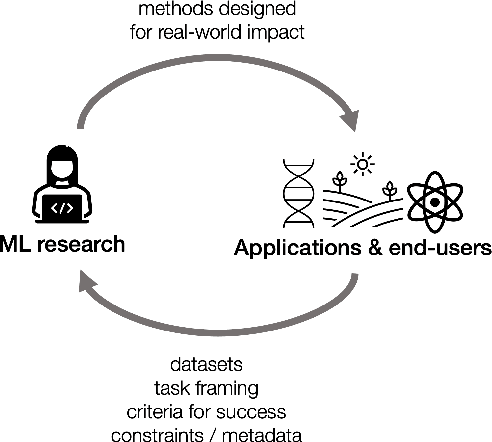
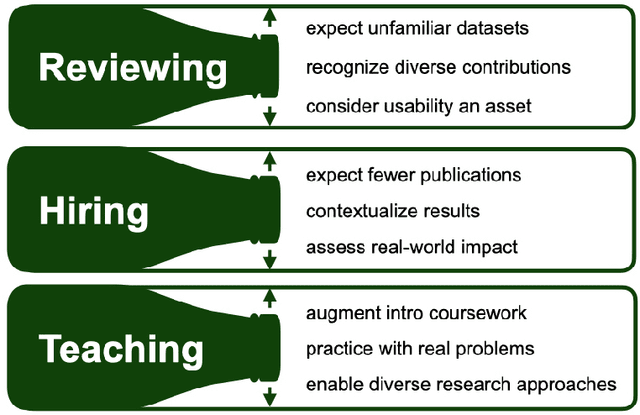
As applications of machine learning proliferate, innovative algorithms inspired by specific real-world challenges have become increasingly important. Such work offers the potential for significant impact not merely in domains of application but also in machine learning itself. In this paper, we describe the paradigm of application-driven research in machine learning, contrasting it with the more standard paradigm of methods-driven research. We illustrate the benefits of application-driven machine learning and how this approach can productively synergize with methods-driven work. Despite these benefits, we find that reviewing, hiring, and teaching practices in machine learning often hold back application-driven innovation. We outline how these processes may be improved.
Harnessing Discrete Representations For Continual Reinforcement Learning
Dec 05, 2023Reinforcement learning (RL) agents make decisions using nothing but observations from the environment, and consequently, heavily rely on the representations of those observations. Though some recent breakthroughs have used vector-based categorical representations of observations, often referred to as discrete representations, there is little work explicitly assessing the significance of such a choice. In this work, we provide a thorough empirical investigation of the advantages of representing observations as vectors of categorical values within the context of reinforcement learning. We perform evaluations on world-model learning, model-free RL, and ultimately continual RL problems, where the benefits best align with the needs of the problem setting. We find that, when compared to traditional continuous representations, world models learned over discrete representations accurately model more of the world with less capacity, and that agents trained with discrete representations learn better policies with less data. In the context of continual RL, these benefits translate into faster adapting agents. Additionally, our analysis suggests that the observed performance improvements can be attributed to the information contained within the latent vectors and potentially the encoding of the discrete representation itself.