 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cross-environment Hyperparameter Setting Benchmark for Reinforcement Learning
Jul 26, 2024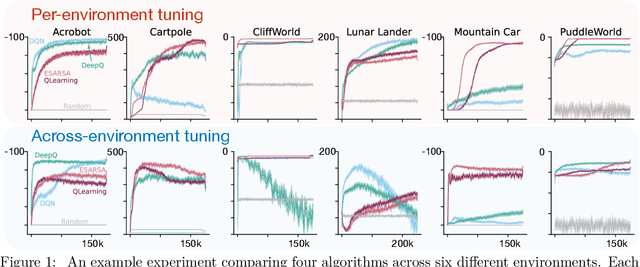
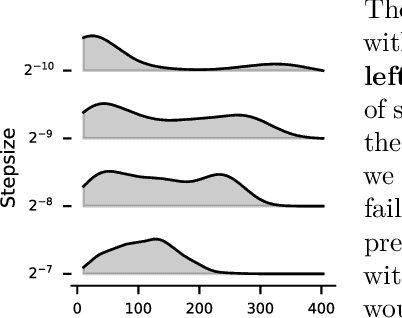
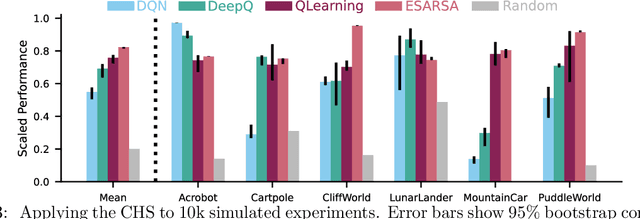
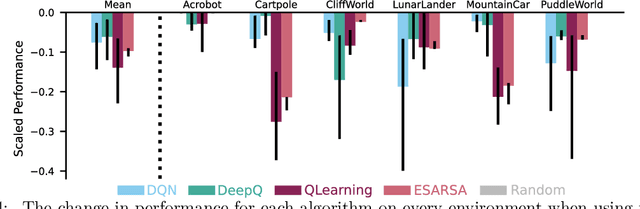
This paper introduces a new empirical methodology, the Cross-environment Hyperparameter Setting Benchmark, that compares RL algorithms across environments using a single hyperparameter setting, encouraging algorithmic development which is insensitive to hyperparameters. We demonstrate that this benchmark is robust to statistical noise and obtains qualitatively similar results across repeated applications, even when using few samples. This robustness makes the benchmark computationally cheap to apply, allowing statistically sound insights at low cost. We demonstrate two example instantiations of the CHS, on a set of six small control environments (SC-CHS) and on the entire DM Control suite of 28 environments (DMC-CHS). Finally, to illustrate the applicability of the CHS to modern RL algorithms on challenging environments, we conduct a novel empirical study of an open question in the continuous control literature. We show, with high confidence, that there is no meaningful difference in performance between Ornstein-Uhlenbeck noise and uncorrelated Gaussian noise for exploration with the DDPG algorithm on the DMC-CHS.
Investigating the Properties of Neural Network Representations in Reinforcement Learning
Mar 30, 2022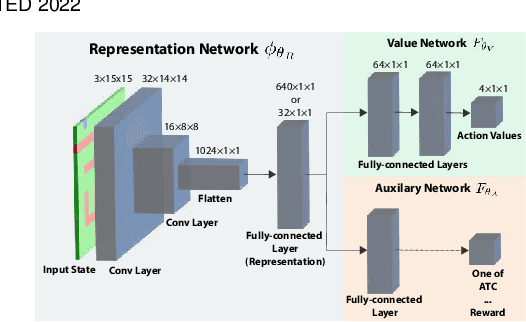

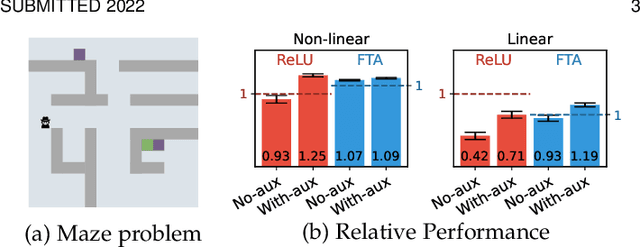

In this paper we investigate the properties of representations learned by deep reinforcement learning systems. Much of the earlier work in representation learning for reinforcement learning focused on designing fixed-basis architectures to achieve properties thought to be desirable, such as orthogonality and sparsity. In contrast, the idea behind deep reinforcement learning methods is that the agent designer should not encode representational properties, but rather that the data stream should determine the properties of the representation -- good representations emerge under appropriate training schemes. In this paper we bring these two perspectives together, empirically investigating the properties of representations that support transfer in reinforcement learning. This analysis allows us to provide novel hypotheses regarding impact of auxiliary tasks in end-to-end training of non-linear reinforcement learning methods. We introduce and measure six representational properties over more than 25 thousand agent-task settings. We consider DQN agents with convolutional networks in a pixel-based navigation environment. We develop a method to better understand \emph{why} some representations work better for transfer, through a systematic approach varying task similarity and measuring and correlating representation properties with transfer performance.
Continual Auxiliary Task Learning
Feb 22, 2022
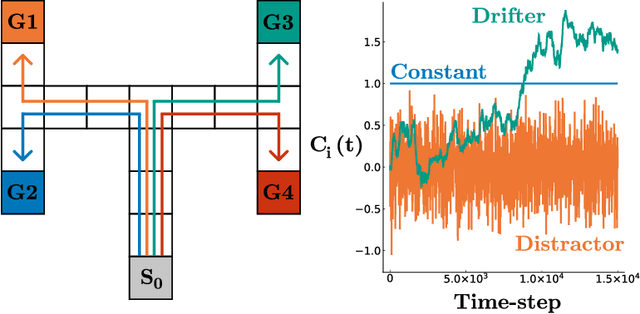
Learning auxiliary tasks, such as multiple predictions about the world, can provide many benefits to reinforcement learning systems. A variety of off-policy learning algorithms have been developed to learn such predictions, but as yet there is little work on how to adapt the behavior to gather useful data for those off-policy predictions. In this work, we investigate a reinforcement learning system designed to learn a collection of auxiliary tasks, with a behavior policy learning to take actions to improve those auxiliary predictions. We highlight the inherent non-stationarity in this continual auxiliary task learning problem, for both prediction learners and the behavior learner. We develop an algorithm based on successor features that facilitates tracking under non-stationary rewards, and prove the separation into learning successor features and rewards provides convergence rate improvements. We conduct an in-depth study into the resulting multi-prediction learning system.
Off-Policy Actor-Critic with Emphatic Weightings
Nov 16, 2021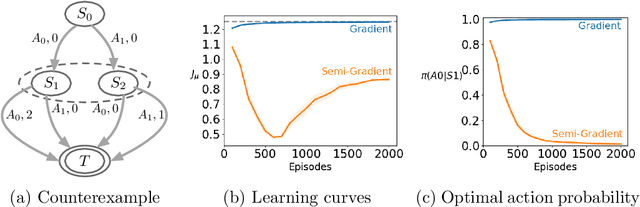
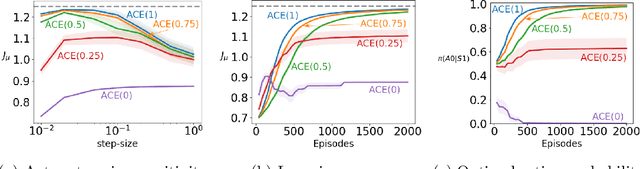
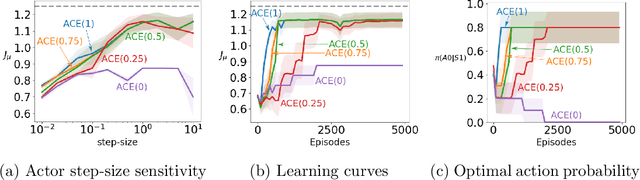
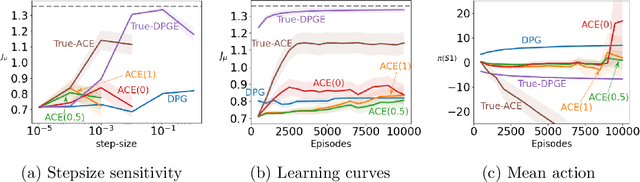
A variety of theoretically-sound policy gradient algorithms exist for the on-policy setting due to the policy gradient theorem, which provides a simplified form for the gradient. The off-policy setting, however, has been less clear due to the existence of multiple objectives and the lack of an explicit off-policy policy gradient theorem. In this work, we unify these objectives into one off-policy objective, and provide a policy gradient theorem for this unified objective. The derivation involves emphatic weightings and interest functions. We show multiple strategies to approximate the gradients, in an algorithm called Actor Critic with Emphatic weightings (ACE). We prove in a counterexample that previous (semi-gradient) off-policy actor-critic methods--particularly OffPAC and DPG--converge to the wrong solution whereas ACE finds the optimal solution. We also highlight why these semi-gradient approaches can still perform well in practice, suggesting strategies for variance reduction in ACE. We empirically study several variants of ACE on two classic control environments and an image-based environment designed to illustrate the tradeoffs made by each gradient approximation. We find that by approximating the emphatic weightings directly, ACE performs as well as or better than OffPAC in all settings tested.
Context-Dependent Upper-Confidence Bounds for Directed Exploration
Nov 15, 2018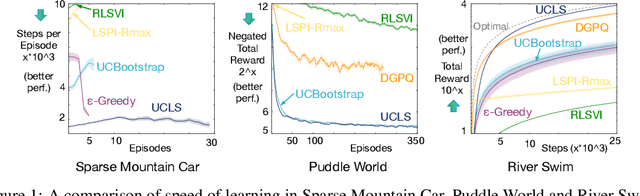
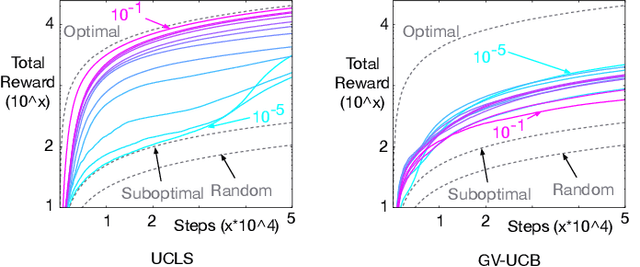
Directed exploration strategies for reinforcement learning are critical for learning an optimal policy in a minimal number of interactions with the environment. Many algorithms use optimism to direct exploration, either through visitation estimates or upper confidence bounds, as opposed to data-inefficient strategies like \epsilon-greedy that use random, undirected exploration. Most data-efficient exploration methods require significant computation, typically relying on a learned model to guide exploration. Least-squares methods have the potential to provide some of the data-efficiency benefits of model-based approaches -- because they summarize past interactions -- with the computation closer to that of model-free approaches. In this work, we provide a novel, computationally efficient, incremental exploration strategy, leveraging this property of least-squares temporal difference learning (LSTD). We derive upper confidence bounds on the action-values learned by LSTD, with context-dependent (or state-dependent) noise variance. Such context-dependent noise focuses exploration on a subset of variable states, and allows for reduced exploration in other states. We empirically demonstrate that our algorithm can converge more quickly than other incremental exploration strategies using confidence estimates on action-values.
The Utility of Sparse Representations for Control in Reinforcement Learning
Nov 15, 2018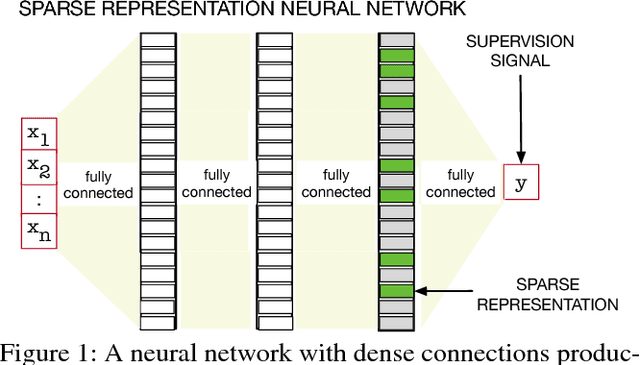
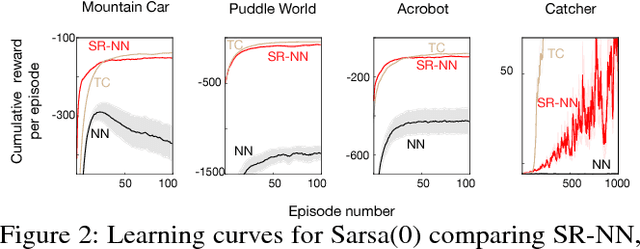
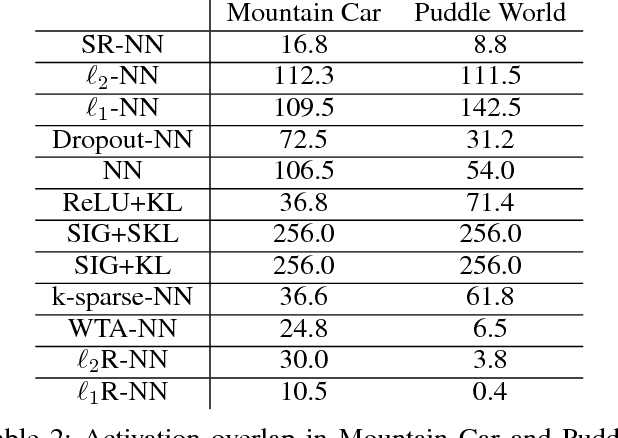
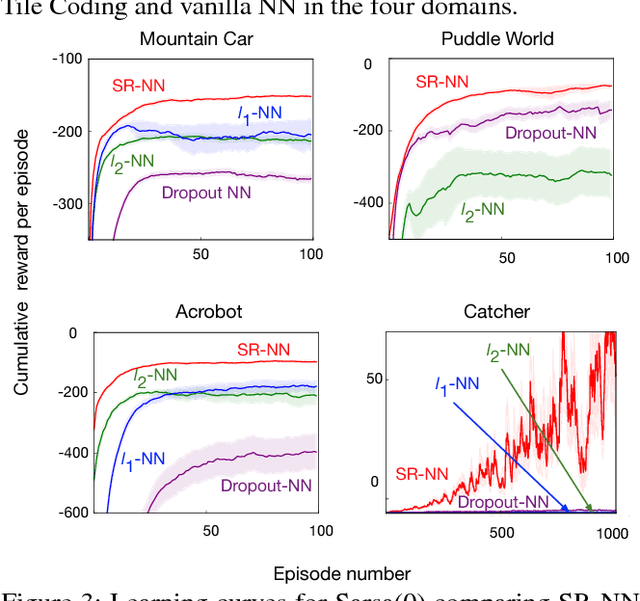
We investigate sparse representations for control in reinforcement learning. While these representations are widely used in computer vision, their prevalence in reinforcement learning is limited to sparse coding where extracting representations for new data can be computationally intensive. Here, we begin by demonstrating that learning a control policy incrementally with a representation from a standard neural network fails in classic control domains, whereas learning with a representation obtained from a neural network that has sparsity properties enforced is effective. We provide evidence that the reason for this is that the sparse representation provides locality, and so avoids catastrophic interference, and particularly keeps consistent, stable values for bootstrapping. We then discuss how to learn such sparse representations. We explore the idea of Distributional Regularizers, where the activation of hidden nodes is encouraged to match a particular distribution that results in sparse activation across time. We identify a simple but effective way to obtain sparse representations, not afforded by previously proposed strategies, making it more practical for further investigation into sparse representations for reinforcement learning.
Learning Sparse Representations in Reinforcement Learning with Sparse Coding
Jul 26, 2017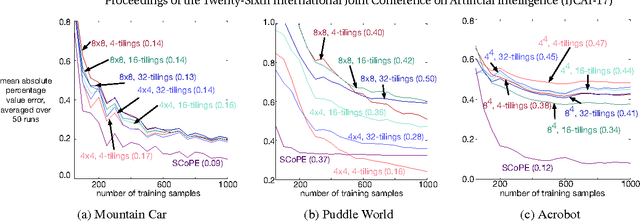

A variety of representation learning approaches have been investigated for reinforcement learning; much less attention, however, has been given to investigating the utility of sparse coding. Outside of reinforcement learning, sparse coding representations have been widely used, with non-convex objectives that result in discriminative representations. In this work, we develop a supervised sparse coding objective for policy evaluation. Despite the non-convexity of this objective, we prove that all local minima are global minima, making the approach amenable to simple optimization strategies. We empirically show that it is key to use a supervised objective, rather than the more straightforward unsupervised sparse coding approach. We compare the learned representations to a canonical fixed sparse representation, called tile-coding, demonstrating that the sparse coding representation outperforms a wide variety of tilecoding representations.