 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024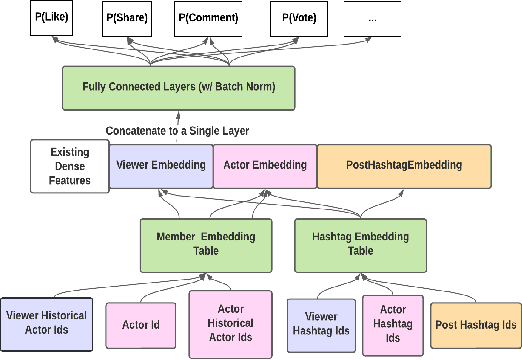

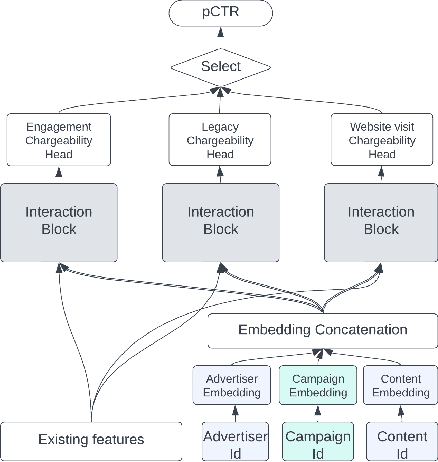

We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
The Utility of Sparse Representations for Control in Reinforcement Learning
Nov 15, 2018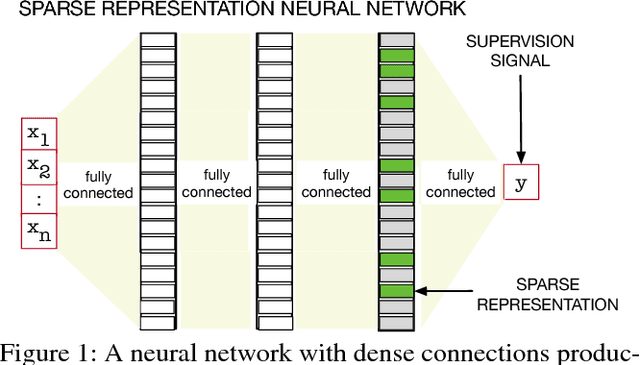
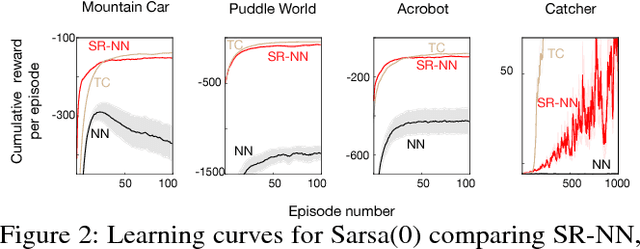
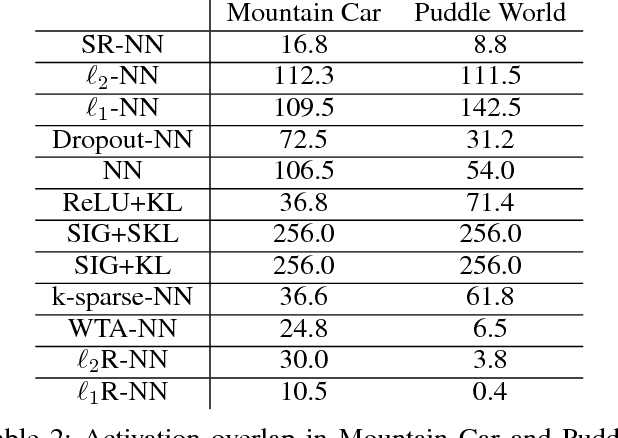
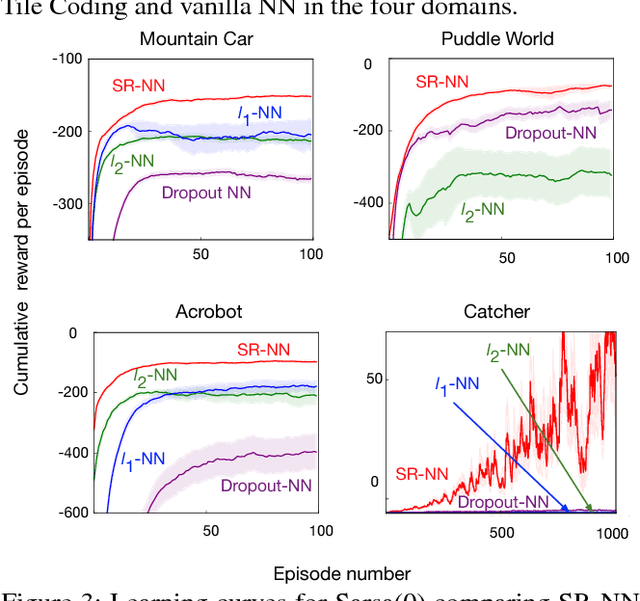
We investigate sparse representations for control in reinforcement learning. While these representations are widely used in computer vision, their prevalence in reinforcement learning is limited to sparse coding where extracting representations for new data can be computationally intensive. Here, we begin by demonstrating that learning a control policy incrementally with a representation from a standard neural network fails in classic control domains, whereas learning with a representation obtained from a neural network that has sparsity properties enforced is effective. We provide evidence that the reason for this is that the sparse representation provides locality, and so avoids catastrophic interference, and particularly keeps consistent, stable values for bootstrapping. We then discuss how to learn such sparse representations. We explore the idea of Distributional Regularizers, where the activation of hidden nodes is encouraged to match a particular distribution that results in sparse activation across time. We identify a simple but effective way to obtain sparse representations, not afforded by previously proposed strategies, making it more practical for further investigation into sparse representations for reinforcement learning.
Actor-Expert: A Framework for using Action-Value Methods in Continuous Action Spaces
Oct 22, 2018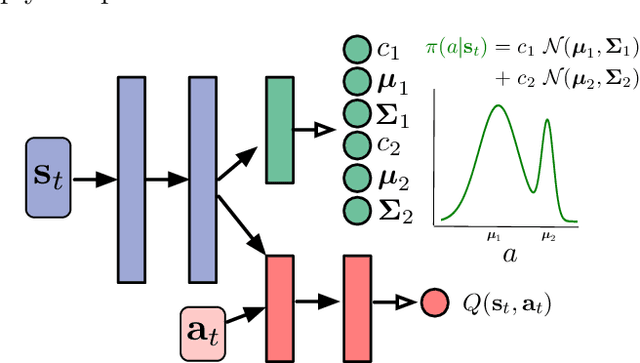

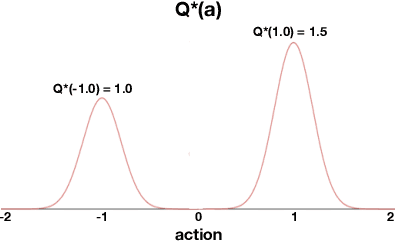
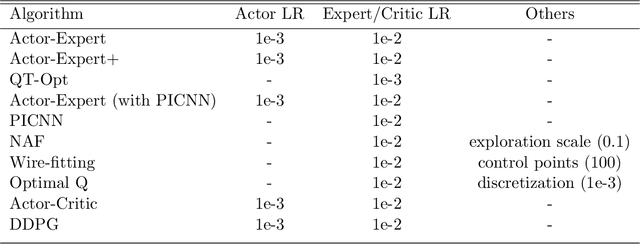
Value-based approaches can be difficult to use in continuous action spaces, because an optimization has to be solved to find the greedy action for the action-values. A common strategy has been to restrict the functional form of the action-values to be convex or quadratic in the actions, to simplify this optimization. Such restrictions, however, can prevent learning accurate action-values. In this work, we propose the Actor-Expert framework for value-based methods, that decouples action-selection (Actor) from the action-value representation (Expert). The Expert uses Q-learning to update the action-values towards the optimal action-values, whereas the Actor (learns to) output the greedy action for the current action-values. We develop a Conditional Cross Entropy Method for the Actor, to learn the greedy action for a generically parameterized Expert, and provide a two-timescale analysis to validate asymptotic behavior. We demonstrate in a toy domain with bimodal action-values that previous restrictive action-value methods fail whereas the decoupled Actor-Expert with a more general action-value parameterization succeeds. Finally, we demonstrate that Actor-Expert performs as well as or better than these other methods on several benchmark continuous-action domains.
Identifying global optimality for dictionary learning
Aug 07, 2017

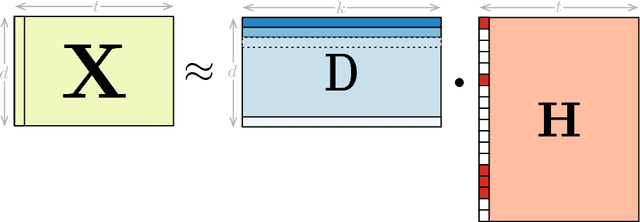
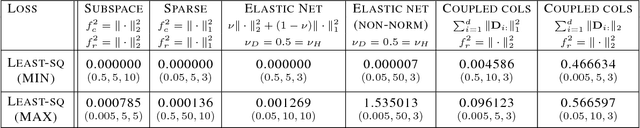
Learning new representations of input observations in machine learning is often tackled using a factorization of the data. For many such problems, including sparse coding and matrix completion, learning these factorizations can be difficult, in terms of efficiency and to guarantee that the solution is a global minimum. Recently, a general class of objectives have been introduced-which we term induced dictionary learning models (DLMs)-that have an induced convex form that enables global optimization. Though attractive theoretically, this induced form is impractical, particularly for large or growing datasets. In this work, we investigate the use of practical alternating minimization algorithms for induced DLMs, that ensure convergence to global optima. We characterize the stationary points of these models, and, using these insights, highlight practical choices for the objectives. We then provide theoretical and empirical evidence that alternating minimization, from a random initialization, converges to global minima for a large subclass of induced DLMs. In particular, we take advantage of the existence of the (potentially unknown) convex induced form, to identify when stationary points are global minima for the dictionary learning objective. We then provide an empirical investigation into practical optimization choices for using alternating minimization for induced DLMs, for both batch and stochastic gradient descent.
Learning Sparse Representations in Reinforcement Learning with Sparse Coding
Jul 26, 2017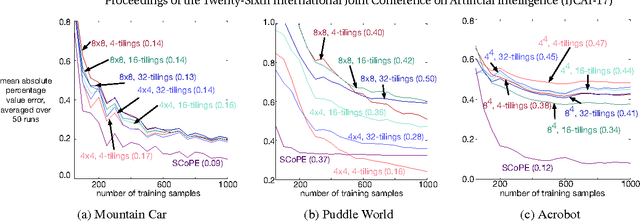

A variety of representation learning approaches have been investigated for reinforcement learning; much less attention, however, has been given to investigating the utility of sparse coding. Outside of reinforcement learning, sparse coding representations have been widely used, with non-convex objectives that result in discriminative representations. In this work, we develop a supervised sparse coding objective for policy evaluation. Despite the non-convexity of this objective, we prove that all local minima are global minima, making the approach amenable to simple optimization strategies. We empirically show that it is key to use a supervised objective, rather than the more straightforward unsupervised sparse coding approach. We compare the learned representations to a canonical fixed sparse representation, called tile-coding, demonstrating that the sparse coding representation outperforms a wide variety of tilecoding representations.
On predictability of rare events leveraging social media: a machine learning perspective
Feb 20, 2015
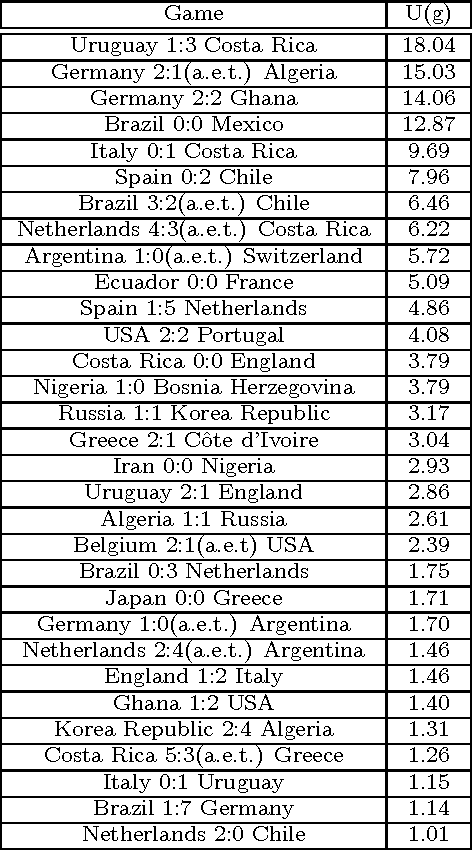
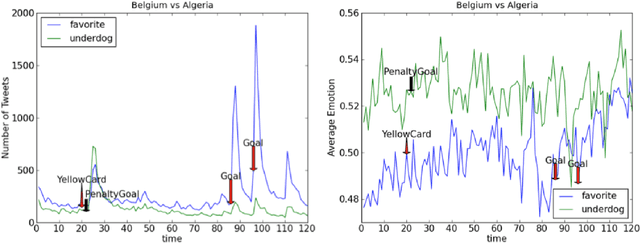
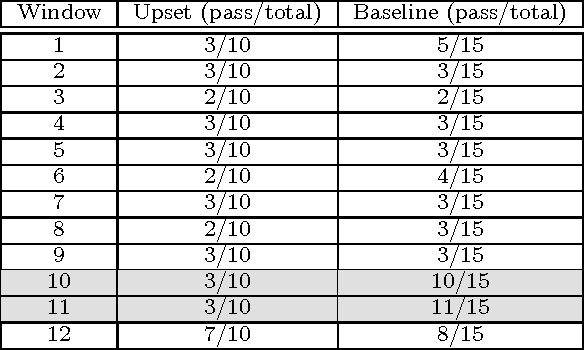
Information extracted from social media streams has been leveraged to forecast the outcome of a large number of real-world events, from political elections to stock market fluctuations. An increasing amount of studies demonstrates how the analysis of social media conversations provides cheap access to the wisdom of the crowd. However, extents and contexts in which such forecasting power can be effectively leveraged are still unverified at least in a systematic way. It is also unclear how social-media-based predictions compare to those based on alternative information sources. To address these issues, here we develop a machine learning framework that leverages social media streams to automatically identify and predict the outcomes of soccer matches. We focus in particular on matches in which at least one of the possible outcomes is deemed as highly unlikely by professional bookmakers. We argue that sport events offer a systematic approach for testing the predictive power of social media, and allow to compare such power against the rigorous baselines set by external sources. Despite such strict baselines, our framework yields above 8% marginal profit when used to inform simple betting strategies. The system is based on real-time sentiment analysis and exploits data collected immediately before the games, allowing for informed bets. We discuss the rationale behind our approach, describe the learning framework, its prediction performance and the return it provides as compared to a set of betting strategies. To test our framework we use both historical Twitter data from the 2014 FIFA World Cup games, and real-time Twitter data collected by monitoring the conversations about all soccer matches of four major European tournaments (FA Premier League, Serie A, La Liga, and Bundesliga), and the 2014 UEFA Champions League, during the period between Oct. 25th 2014 and Nov. 26th 2014.
* 10 pages, 10 tables, 8 figures