 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Residual Connections
Feb 09, 2026Existing work has linked properties of a function's gradient to the difficulty of function approximation. Motivated by these insights, we study how gradient information can be leveraged to improve neural network's ability to approximate high-frequency functions, and we propose a gradient-based residual connection as a complement to the standard identity skip connection used in residual networks. We provide simple theoretical intuition for why gradient information can help distinguish inputs and improve the approximation of functions with rapidly varying behaviour. On a synthetic regression task with a high-frequency sinusoidal ground truth, we show that conventional residual connections struggle to capture high-frequency patterns. In contrast, our gradient residual substantially improves approximation quality. We then introduce a convex combination of the standard and gradient residuals, allowing the network to flexibly control how strongly it relies on gradient information. After validating the design choices of our proposed method through an ablation study, we further validate our approach's utility on the single-image super-resolution task, where the underlying function may be high-frequency. Finally, on standard tasks such as image classification and segmentation, our method achieves performance comparable to standard residual networks, suggesting its broad utility.
Measures of Variability for Risk-averse Policy Gradient
Apr 15, 2025Risk-averse reinforcement learning (RARL) is critical for decision-making under uncertainty, which is especially valuable in high-stake applications. However, most existing works focus on risk measures, e.g., conditional value-at-risk (CVaR), while measures of variability remain underexplored. In this paper, we comprehensively study nine common measures of variability, namely Variance, Gini Deviation, Mean Deviation, Mean-Median Deviation, Standard Deviation, Inter-Quantile Range, CVaR Deviation, Semi_Variance, and Semi_Standard Deviation. Among them, four metrics have not been previously studied in RARL. We derive policy gradient formulas for these unstudied metrics, improve gradient estimation for Gini Deviation, analyze their gradient properties, and incorporate them with the REINFORCE and PPO frameworks to penalize the dispersion of returns. Our empirical study reveals that variance-based metrics lead to unstable policy updates. In contrast, CVaR Deviation and Gini Deviation show consistent performance across different randomness and evaluation domains, achieving high returns while effectively learning risk-averse policies. Mean Deviation and Semi_Standard Deviation are also competitive across different scenarios. This work provides a comprehensive overview of variability measures in RARL, offering practical insights for risk-aware decision-making and guiding future research on risk metrics and RARL algorithms.
PANDAS: Improving Many-shot Jailbreaking via Positive Affirmation, Negative Demonstration, and Adaptive Sampling
Feb 04, 2025



Many-shot jailbreaking circumvents the safety alignment of large language models by exploiting their ability to process long input sequences. To achieve this, the malicious target prompt is prefixed with hundreds of fabricated conversational turns between the user and the model. These fabricated exchanges are randomly sampled from a pool of malicious questions and responses, making it appear as though the model has already complied with harmful instructions. In this paper, we present PANDAS: a hybrid technique that improves many-shot jailbreaking by modifying these fabricated dialogues with positive affirmations, negative demonstrations, and an optimized adaptive sampling method tailored to the target prompt's topic. Extensive experiments on AdvBench and HarmBench, using state-of-the-art LLMs, demonstrate that PANDAS significantly outperforms baseline methods in long-context scenarios. Through an attention analysis, we provide insights on how long-context vulnerabilities are exploited and show how PANDAS further improves upon many-shot jailbreaking.
DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024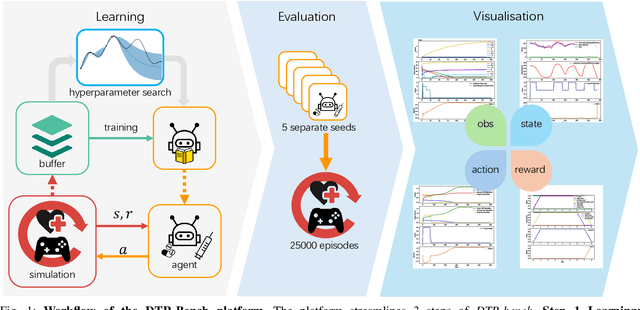
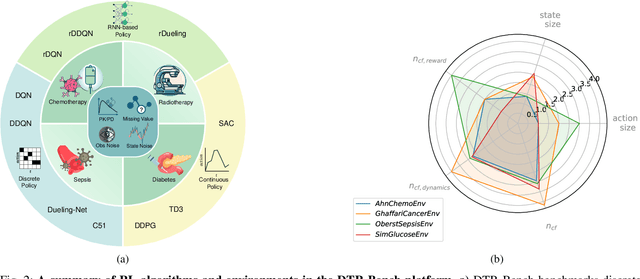


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
Reinforcement Learning in Dynamic Treatment Regimes Needs Critical Reexamination
May 28, 2024



In the rapidly changing healthcare landscape, the implementation of offline reinforcement learning (RL) in dynamic treatment regimes (DTRs) presents a mix of unprecedented opportunities and challenges. This position paper offers a critical examination of the current status of offline RL in the context of DTRs. We argue for a reassessment of applying RL in DTRs, citing concerns such as inconsistent and potentially inconclusive evaluation metrics, the absence of naive and supervised learning baselines, and the diverse choice of RL formulation in existing research. Through a case study with more than 17,000 evaluation experiments using a publicly available Sepsis dataset, we demonstrate that the performance of RL algorithms can significantly vary with changes in evaluation metrics and Markov Decision Process (MDP) formulations. Surprisingly, it is observed that in some instances, RL algorithms can be surpassed by random baselines subjected to policy evaluation methods and reward design. This calls for more careful policy evaluation and algorithm development in future DTR works. Additionally, we discussed potential enhancements toward more reliable development of RL-based dynamic treatment regimes and invited further discussion within the community. Code is available at https://github.com/GilesLuo/ReassessDTR.
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
Apr 23, 2024
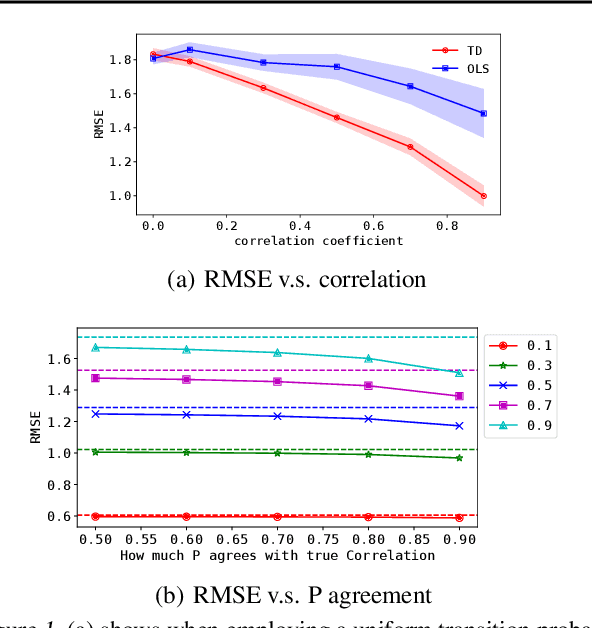
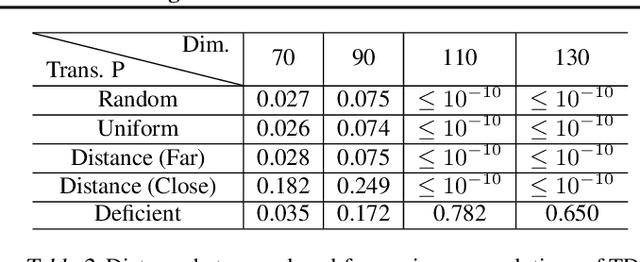
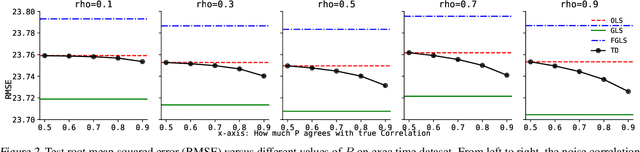
In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i.i.d.) following an unknown probability distribution. This paper presents a contrasting viewpoint, perceiving data points as interconnected and employing a Markov reward process (MRP) for data modeling. We reformulate the typical supervised learning as an on-policy policy evaluation problem within reinforcement learning (RL), introducing a generalized temporal difference (TD) learning algorithm as a resolution. Theoretically, our analysis draws connections between the solutions of linear TD learning and ordinary least squares (OLS). We also show that under specific conditions, particularly when noises are correlated, the TD's solution proves to be a more effective estimator than OLS. Furthermore, we establish the convergence of our generalized TD algorithms under linear function approximation. Empirical studies verify our theoretical results, examine the vital design of our TD algorithm and show practical utility across various datasets, encompassing tasks such as regression and image classification with deep learning.
A Simple Mixture Policy Parameterization for Improving Sample Efficiency of CVaR Optimization
Mar 20, 2024



Reinforcement learning algorithms utilizing policy gradients (PG) to optimize Conditional Value at Risk (CVaR) face significant challenges with sample inefficiency, hindering their practical applications. This inefficiency stems from two main facts: a focus on tail-end performance that overlooks many sampled trajectories, and the potential of gradient vanishing when the lower tail of the return distribution is overly flat. To address these challenges, we propose a simple mixture policy parameterization. This method integrates a risk-neutral policy with an adjustable policy to form a risk-averse policy. By employing this strategy, all collected trajectories can be utilized for policy updating, and the issue of vanishing gradients is counteracted by stimulating higher returns through the risk-neutral component, thus lifting the tail and preventing flatness. Our empirical study reveals that this mixture parameterization is uniquely effective across a variety of benchmark domains. Specifically, it excels in identifying risk-averse CVaR policies in some Mujoco environments where the traditional CVaR-PG fails to learn a reasonable policy.
Improving Adversarial Transferability via Model Alignment
Nov 30, 2023

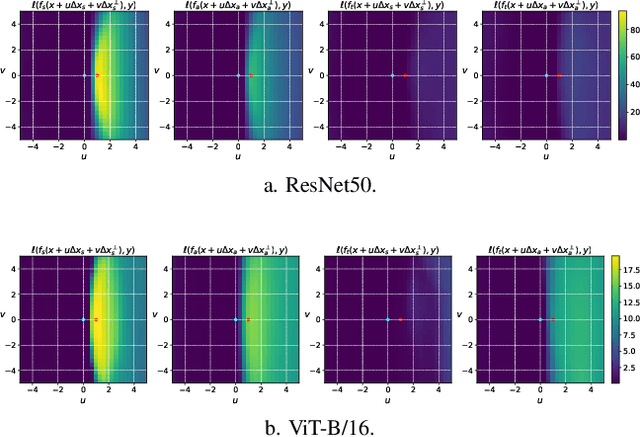

Neural networks are susceptible to adversarial perturbations that are transferable across different models. In this paper, we introduce a novel model alignment technique aimed at improving a given source model's ability in generating transferable adversarial perturbations. During the alignment process, the parameters of the source model are fine-tuned to minimize an alignment loss. This loss measures the divergence in the predictions between the source model and another, independently trained model, referred to as the witness model. To understand the effect of model alignment, we conduct a geometric anlaysis of the resulting changes in the loss landscape. Extensive experiments on the ImageNet dataset, using a variety of model architectures, demonstrate that perturbations generated from aligned source models exhibit significantly higher transferability than those from the original source model.
Understanding the robustness difference between stochastic gradient descent and adaptive gradient methods
Aug 13, 2023Stochastic gradient descent (SGD) and adaptive gradient methods, such as Adam and RMSProp, have been widely used in training deep neural networks. We empirically show that while the difference between the standard generalization performance of models trained using these methods is small, those trained using SGD exhibit far greater robustness under input perturbations. Notably, our investigation demonstrates the presence of irrelevant frequencies in natural datasets, where alterations do not affect models' generalization performance. However, models trained with adaptive methods show sensitivity to these changes, suggesting that their use of irrelevant frequencies can lead to solutions sensitive to perturbations. To better understand this difference, we study the learning dynamics of gradient descent (GD) and sign gradient descent (signGD) on a synthetic dataset that mirrors natural signals. With a three-dimensional input space, the models optimized with GD and signGD have standard risks close to zero but vary in their adversarial risks. Our result shows that linear models' robustness to $\ell_2$-norm bounded changes is inversely proportional to the model parameters' weight norm: a smaller weight norm implies better robustness. In the context of deep learning, our experiments show that SGD-trained neural networks show smaller Lipschitz constants, explaining the better robustness to input perturbations than those trained with adaptive gradient methods.
An Alternative to Variance: Gini Deviation for Risk-averse Policy Gradient
Aug 09, 2023


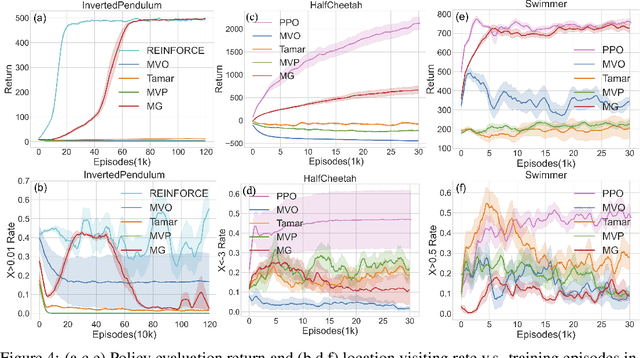
Restricting the variance of a policy's return is a popular choice in risk-averse Reinforcement Learning (RL) due to its clear mathematical definition and easy interpretability. Traditional methods directly restrict the total return variance. Recent methods restrict the per-step reward variance as a proxy. We thoroughly examine the limitations of these variance-based methods, such as sensitivity to numerical scale and hindering of policy learning, and propose to use an alternative risk measure, Gini deviation, as a substitute. We study various properties of this new risk measure and derive a policy gradient algorithm to minimize it. Empirical evaluation in domains where risk-aversion can be clearly defined, shows that our algorithm can mitigate the limitations of variance-based risk measures and achieves high return with low risk in terms of variance and Gini deviation when others fail to learn a reasonable policy.