 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Data Gaps of Rare Conditions in ICU: A Multi-Disease Adaptation Approach for Clinical Prediction
Jul 08, 2025Artificial Intelligence has revolutionised critical care for common conditions. Yet, rare conditions in the intensive care unit (ICU), including recognised rare diseases and low-prevalence conditions in the ICU, remain underserved due to data scarcity and intra-condition heterogeneity. To bridge such gaps, we developed KnowRare, a domain adaptation-based deep learning framework for predicting clinical outcomes for rare conditions in the ICU. KnowRare mitigates data scarcity by initially learning condition-agnostic representations from diverse electronic health records through self-supervised pre-training. It addresses intra-condition heterogeneity by selectively adapting knowledge from clinically similar conditions with a developed condition knowledge graph. Evaluated on two ICU datasets across five clinical prediction tasks (90-day mortality, 30-day readmission, ICU mortality, remaining length of stay, and phenotyping), KnowRare consistently outperformed existing state-of-the-art models. Additionally, KnowRare demonstrated superior predictive performance compared to established ICU scoring systems, including APACHE IV and IV-a. Case studies further demonstrated KnowRare's flexibility in adapting its parameters to accommodate dataset-specific and task-specific characteristics, its generalisation to common conditions under limited data scenarios, and its rationality in selecting source conditions. These findings highlight KnowRare's potential as a robust and practical solution for supporting clinical decision-making and improving care for rare conditions in the ICU.
DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024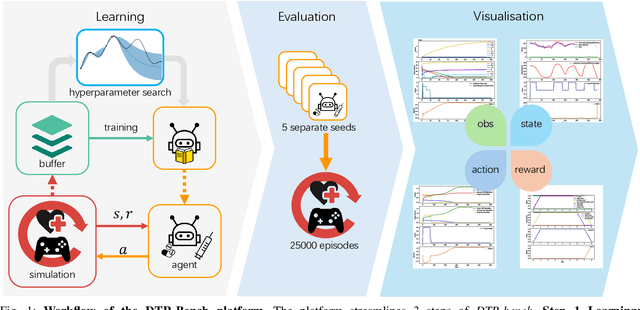
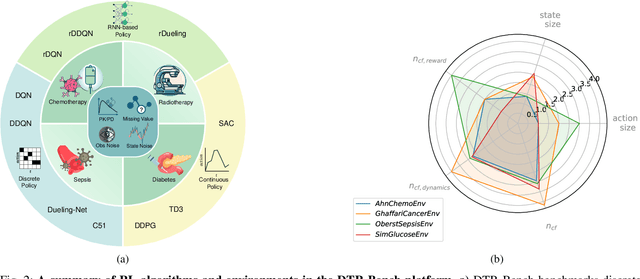


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.