 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePediaBench: A Comprehensive Chinese Pediatric Dataset for Benchmarking Large Language Models
Dec 09, 2024



The emergence of Large Language Models (LLMs) in the medical domain has stressed a compelling need for standard datasets to evaluate their question-answering (QA) performance. Although there have been several benchmark datasets for medical QA, they either cover common knowledge across different departments or are specific to another department rather than pediatrics. Moreover, some of them are limited to objective questions and do not measure the generation capacity of LLMs. Therefore, they cannot comprehensively assess the QA ability of LLMs in pediatrics. To fill this gap, we construct PediaBench, the first Chinese pediatric dataset for LLM evaluation. Specifically, it contains 4,565 objective questions and 1,632 subjective questions spanning 12 pediatric disease groups. It adopts an integrated scoring criterion based on different difficulty levels to thoroughly assess the proficiency of an LLM in instruction following, knowledge understanding, clinical case analysis, etc. Finally, we validate the effectiveness of PediaBench with extensive experiments on 20 open-source and commercial LLMs. Through an in-depth analysis of experimental results, we offer insights into the ability of LLMs to answer pediatric questions in the Chinese context, highlighting their limitations for further improvements. Our code and data are published at https://github.com/ACMISLab/PediaBench.
DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024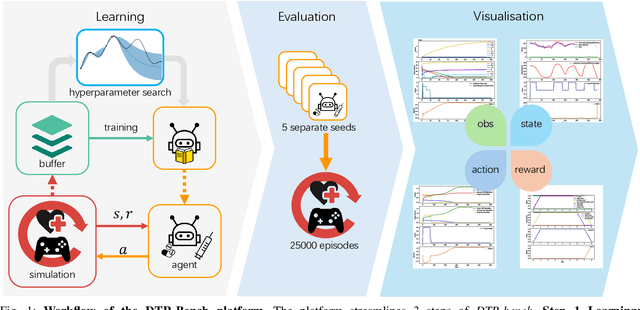
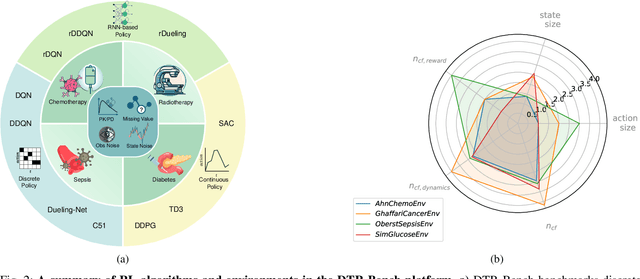


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
An Artificial Intelligence (AI) workflow for catalyst design and optimization
Feb 07, 2024



In the pursuit of novel catalyst development to address pressing environmental concerns and energy demand, conventional design and optimization methods often fall short due to the complexity and vastness of the catalyst parameter space. The advent of Machine Learning (ML) has ushered in a new era in the field of catalyst optimization, offering potential solutions to the shortcomings of traditional techniques. However, existing methods fail to effectively harness the wealth of information contained within the burgeoning body of scientific literature on catalyst synthesis. To address this gap, this study proposes an innovative Artificial Intelligence (AI) workflow that integrates Large Language Models (LLMs), Bayesian optimization, and an active learning loop to expedite and enhance catalyst optimization. Our methodology combines advanced language understanding with robust optimization strategies, effectively translating knowledge extracted from diverse literature into actionable parameters for practical experimentation and optimization. In this article, we demonstrate the application of this AI workflow in the optimization of catalyst synthesis for ammonia production. The results underscore the workflow's ability to streamline the catalyst development process, offering a swift, resource-efficient, and high-precision alternative to conventional methods.
* 31 pages, 7 figures
Explainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine
Nov 17, 2022



Artificial intelligence (AI) continues to transform data analysis in many domains. Progress in each domain is driven by a growing body of annotated data, increased computational resources, and technological innovations. In medicine, the sensitivity of the data, the complexity of the tasks, the potentially high stakes, and a requirement of accountability give rise to a particular set of challenges. In this review, we focus on three key methodological approaches that address some of the particular challenges in AI-driven medical decision making. (1) Explainable AI aims to produce a human-interpretable justification for each output. Such models increase confidence if the results appear plausible and match the clinicians expectations. However, the absence of a plausible explanation does not imply an inaccurate model. Especially in highly non-linear, complex models that are tuned to maximize accuracy, such interpretable representations only reflect a small portion of the justification. (2) Domain adaptation and transfer learning enable AI models to be trained and applied across multiple domains. For example, a classification task based on images acquired on different acquisition hardware. (3) Federated learning enables learning large-scale models without exposing sensitive personal health information. Unlike centralized AI learning, where the centralized learning machine has access to the entire training data, the federated learning process iteratively updates models across multiple sites by exchanging only parameter updates, not personal health data. This narrative review covers the basic concepts, highlights relevant corner-stone and state-of-the-art research in the field, and discusses perspectives.
A robust low data solution: dimension prediction of semiconductor nanorods
Oct 27, 2020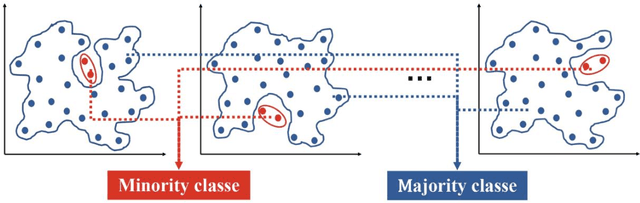

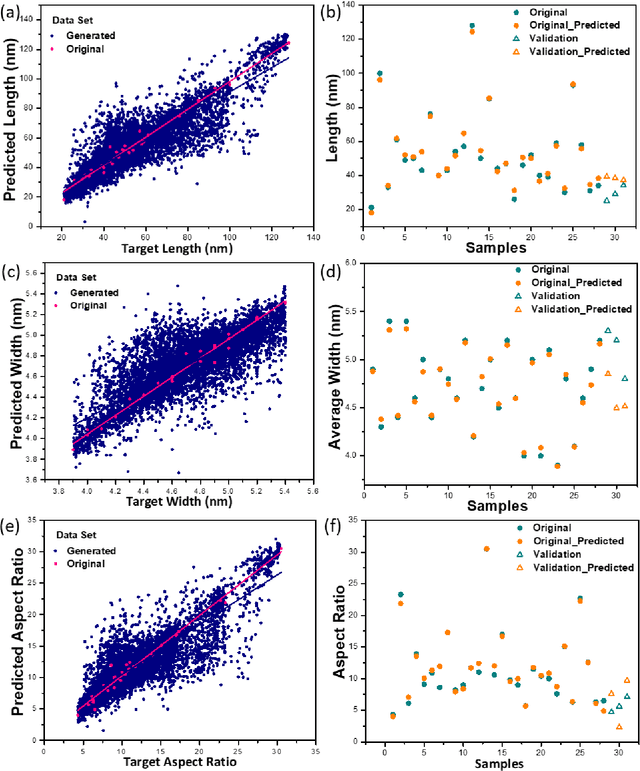
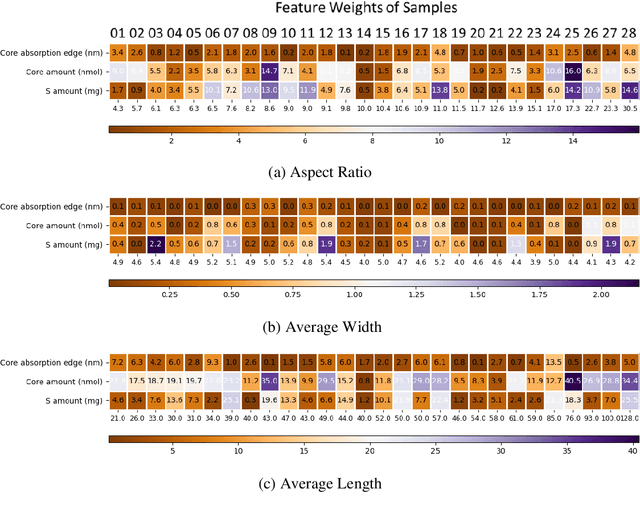
Precise control over dimension of nanocrystals is critical to tune the properties for various applications. However, the traditional control through experimental optimization is slow, tedious and time consuming. Herein a robust deep neural network-based regression algorithm has been developed for precise prediction of length, width, and aspect ratios of semiconductor nanorods (NRs). Given there is limited experimental data available (28 samples), a Synthetic Minority Oversampling Technique for regression (SMOTE-REG) has been employed for the first time for data generation. Deep neural network is further applied to develop regression model which demonstrated the well performed prediction on both the original and generated data with a similar distribution. The prediction model is further validated with additional experimental data, showing accurate prediction results. Additionally, Local Interpretable Model-Agnostic Explanations (LIME) is used to interpret the weight for each variable, which corresponds to its importance towards the target dimension, which is approved to be well correlated well with experimental observations.