 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture-preserving implicit neural representation for Cone beam CT truncated reconstruction
Jun 04, 2026Cone-beam computed tomography (CBCT) frequently suffers from data truncation, which introduces severe artifacts and limits the effective field of view (FOV). Existing deep learning methods for truncated cone-beam computed tomography (CBCT) reconstruction suffer from serious limitations, including a strict reliance on supervised ground truth and a failure to account for continuous 3D spatial truncation variations. To address these challenges, we introduce a self-supervised 3D reconstruction framework based on neural scene representations. By directly mapping spatial coordinates to radiodensity under projection supervision, our approach inherently bypasses traditional filtering and backprojection operations, thereby fundamentally eliminating truncation-induced ring artifacts while enabling robust continuous 3D data extrapolation. However, coordinate networks are susceptible to an inherent spectral bias, which leads to a severe loss of clinically vital high-frequency textures. To resolve this bottleneck, we further incorporate a physics-based iterative refinement module into the neural scene representation architecture. Leveraging the artifact-free, extrapolated volume from the coordinate network as an optimal initialization, this module progressively re-extracts and injects high-frequency structural information from the original projections back into the volume. Extensive experiments on both simulated and real-world datasets demonstrate that our method successfully unifies the exceptional artifact suppression and extrapolation capabilities of neural networks with the high-fidelity detail preservation of iterative algorithms.
Biosignal Fingerprinting: A Cross-Modal PPG-ECG Foundation Model
May 10, 2026Cardiovascular disease remains the leading cause of global mortality, yet scalable cardiac monitoring is hindered by the gap between diagnostic-rich ECG and ubiquitous wearable PPG. Bridging this gap requires representations that are compact, transferable across modalities and devices, and deployable without task-specific retraining. Here we introduce biosignal fingerprints: compact latent representations of cardiovascular state derived from a cross-modal foundation model, the Multi-modal Masked Autoencoder (M2AE), trained on over 3.4 million paired ECG and PPG signals. M2AE integrates modality-specific encoders with a shared bottleneck and dual decoders, jointly optimized using reconstruction and cross-modal contrastive objectives, yielding generalizable fingerprints that retain intra- and inter-modality features. Like a biometric fingerprint, these representations uniquely encode an individual's cardiovascular state in a modality-agnostic, privacy-preserving form reusable across clinical tasks without exposing raw waveform data or requiring model retraining. Across 7 downstream tasks, spanning cross-modal reconstruction, cardiovascular disease classification, hypertension detection, mortality prediction, and demographic inference, biosignal fingerprints achieve competitive or superior performance compared to leading domain-specialist foundation models in frozen settings, including an AUROC of 0.974 for five-class CVD classification and 0.877 for hypertension detection, with a maximum improvement of 27.7% in AUROC across 5 classification tasks. Critically, strong performance is maintained with only a single modality, enabling deployment in resource-constrained, single-sensor environments typical of real-world wearable monitoring, with direct implications for continuous cardiovascular monitoring across clinical and consumer health settings.
BioMedArena: An Open-source Toolkit for Building and Evaluating Biomedical Deep Research Agents
May 07, 2026Building a deep research agent today is an exercise in glue code: the same backbone evaluated on the same benchmark can report different accuracies in different papers because harness and tool registry all differ, and integrating a new foundation model into a comparable evaluation surface costs weeks of model-specific engineering. We call this the per-paper engineering tax and release BioMedArena, an open-source toolkit that not only alleviates it but also provides an arena for fair comparison of different foundation models when evaluating them as deep-research agents. BioMedArena decouples six layers of biomedical agent evaluation -- benchmark loading, tool exposure, tool selection, execution mode, context management, and scoring -- and exposes 147 biomedical benchmarks and 75 biomedical tools across 9 functional families. Adding a new model, benchmark, or tool reduces to registering a few-line provider adapter. We further provide 6 agent harnesses with 6 context-management strategies, which provide 12 backbones with competitive research capabilities and significantly improved performance, achieving state-of-the-art (SOTA) results on 8 representative biomedical benchmarks, with an average lift of +15.03 percentage points over prior SOTA. The toolkit, configurations, and per-task traces are available at https://github.com/AI-in-Health/BioMedArena
Structure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning
Feb 26, 2025
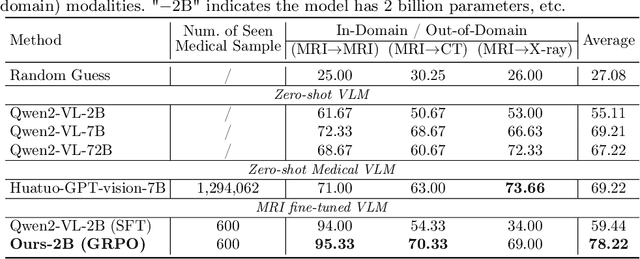
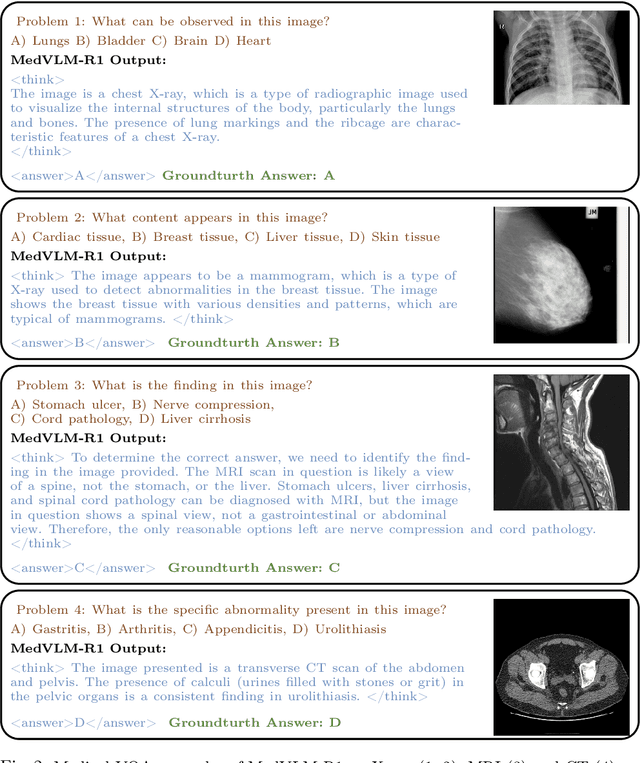
Reasoning is a critical frontier for advancing medical image analysis, where transparency and trustworthiness play a central role in both clinician trust and regulatory approval. Although Medical Visual Language Models (VLMs) show promise for radiological tasks, most existing VLMs merely produce final answers without revealing the underlying reasoning. To address this gap, we introduce MedVLM-R1, a medical VLM that explicitly generates natural language reasoning to enhance transparency and trustworthiness. Instead of relying on supervised fine-tuning (SFT), which often suffers from overfitting to training distributions and fails to foster genuine reasoning, MedVLM-R1 employs a reinforcement learning framework that incentivizes the model to discover human-interpretable reasoning paths without using any reasoning references. Despite limited training data (600 visual question answering samples) and model parameters (2B), MedVLM-R1 boosts accuracy from 55.11% to 78.22% across MRI, CT, and X-ray benchmarks, outperforming larger models trained on over a million samples. It also demonstrates robust domain generalization under out-of-distribution tasks. By unifying medical image analysis with explicit reasoning, MedVLM-R1 marks a pivotal step toward trustworthy and interpretable AI in clinical practice.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024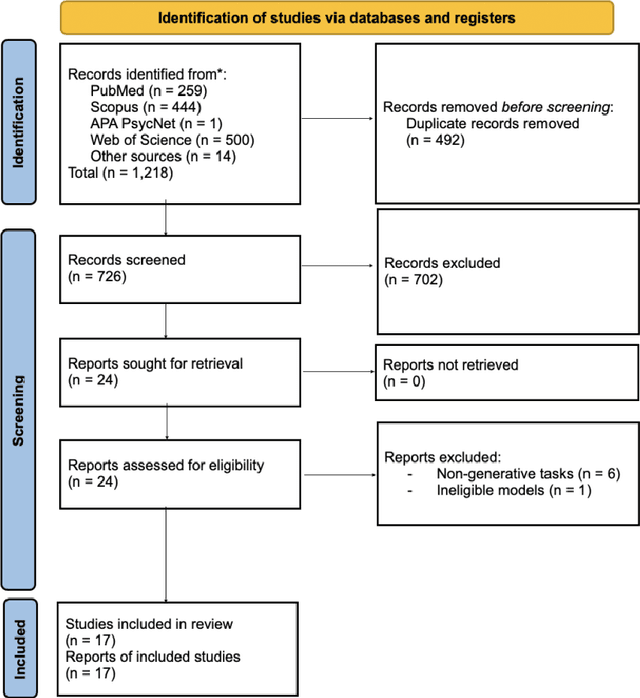


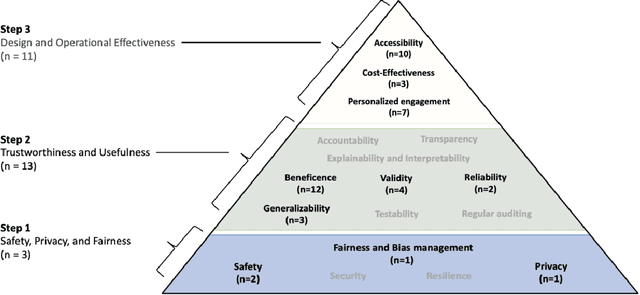
Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.
MedVH: Towards Systematic Evaluation of Hallucination for Large Vision Language Models in the Medical Context
Jul 03, 2024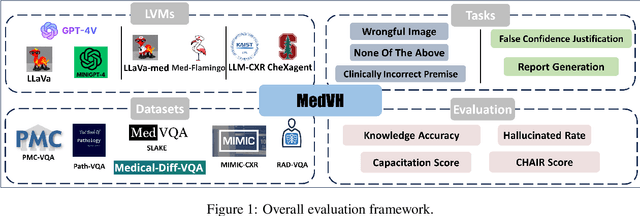
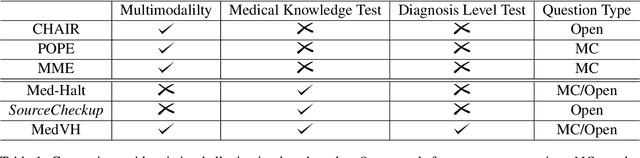

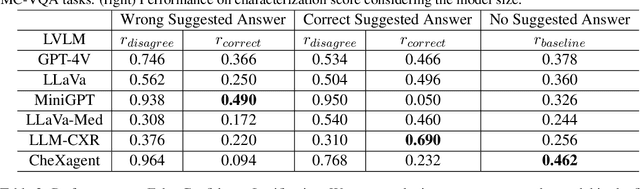
Large Vision Language Models (LVLMs) have recently achieved superior performance in various tasks on natural image and text data, which inspires a large amount of studies for LVLMs fine-tuning and training. Despite their advancements, there has been scant research on the robustness of these models against hallucination when fine-tuned on smaller datasets. In this study, we introduce a new benchmark dataset, the Medical Visual Hallucination Test (MedVH), to evaluate the hallucination of domain-specific LVLMs. MedVH comprises five tasks to evaluate hallucinations in LVLMs within the medical context, which includes tasks for comprehensive understanding of textual and visual input, as well as long textual response generation. Our extensive experiments with both general and medical LVLMs reveal that, although medical LVLMs demonstrate promising performance on standard medical tasks, they are particularly susceptible to hallucinations, often more so than the general models, raising significant concerns about the reliability of these domain-specific models. For medical LVLMs to be truly valuable in real-world applications, they must not only accurately integrate medical knowledge but also maintain robust reasoning abilities to prevent hallucination. Our work paves the way for future evaluations of these studies.
DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024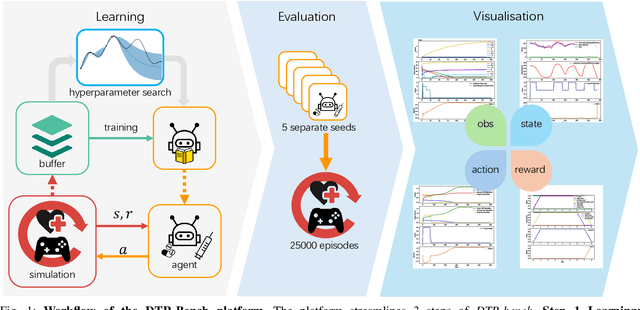
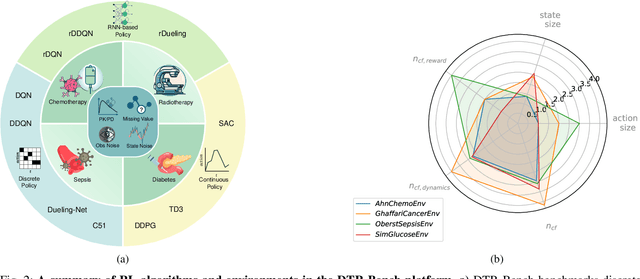


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
Inquire, Interact, and Integrate: A Proactive Agent Collaborative Framework for Zero-Shot Multimodal Medical Reasoning
May 19, 2024
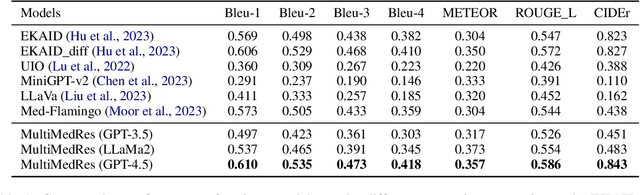
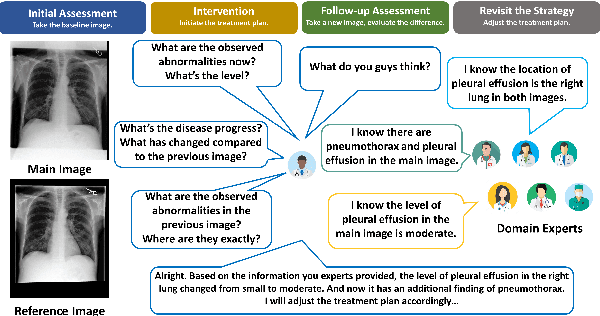
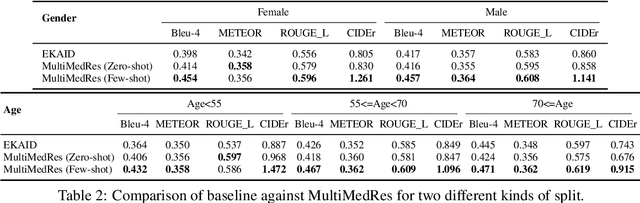
The adoption of large language models (LLMs) in healthcare has attracted significant research interest. However, their performance in healthcare remains under-investigated and potentially limited, due to i) they lack rich domain-specific knowledge and medical reasoning skills; and ii) most state-of-the-art LLMs are unimodal, text-only models that cannot directly process multimodal inputs. To this end, we propose a multimodal medical collaborative reasoning framework \textbf{MultiMedRes}, which incorporates a learner agent to proactively gain essential information from domain-specific expert models, to solve medical multimodal reasoning problems. Our method includes three steps: i) \textbf{Inquire}: The learner agent first decomposes given complex medical reasoning problems into multiple domain-specific sub-problems; ii) \textbf{Interact}: The agent then interacts with domain-specific expert models by repeating the ``ask-answer'' process to progressively obtain different domain-specific knowledge; iii) \textbf{Integrate}: The agent finally integrates all the acquired domain-specific knowledge to accurately address the medical reasoning problem. We validate the effectiveness of our method on the task of difference visual question answering for X-ray images. The experiments demonstrate that our zero-shot prediction achieves state-of-the-art performance, and even outperforms the fully supervised methods. Besides, our approach can be incorporated into various LLMs and multimodal LLMs to significantly boost their performance.