 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025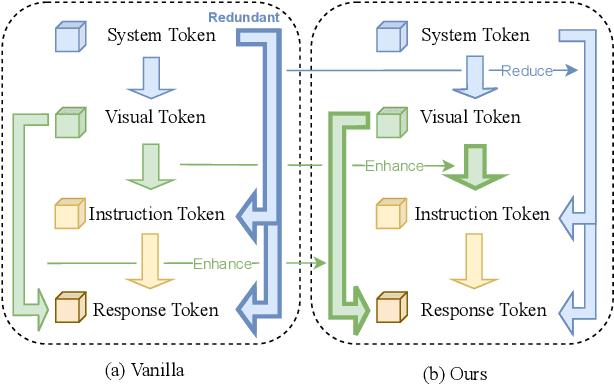
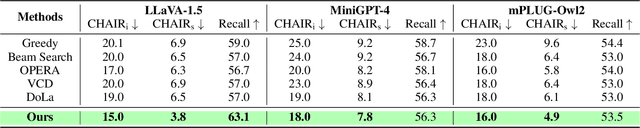
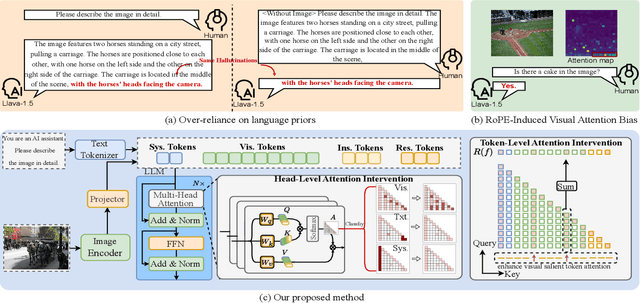

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Mar 22, 2024



The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
Mar 14, 2024

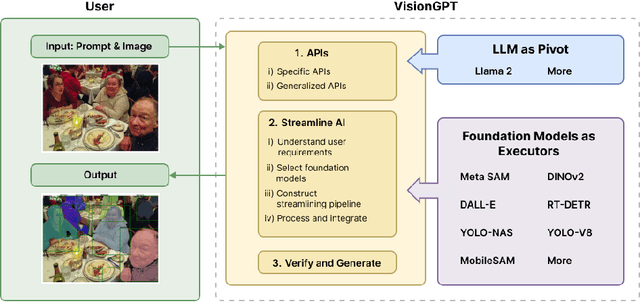

With the emergence of large language models (LLMs) and vision foundation models, how to combine the intelligence and capacity of these open-sourced or API-available models to achieve open-world visual perception remains an open question. In this paper, we introduce VisionGPT to consolidate and automate the integration of state-of-the-art foundation models, thereby facilitating vision-language understanding and the development of vision-oriented AI. VisionGPT builds upon a generalized multimodal framework that distinguishes itself through three key features: (1) utilizing LLMs (e.g., LLaMA-2) as the pivot to break down users' requests into detailed action proposals to call suitable foundation models; (2) integrating multi-source outputs from foundation models automatically and generating comprehensive responses for users; (3) adaptable to a wide range of applications such as text-conditioned image understanding/generation/editing and visual question answering. This paper outlines the architecture and capabilities of VisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, and generalization, and performance. Our code and models will be made publicly available. Keywords: VisionGPT, Open-world visual perception, Vision-language understanding, Large language model, and Foundation model
WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Mar 10, 2024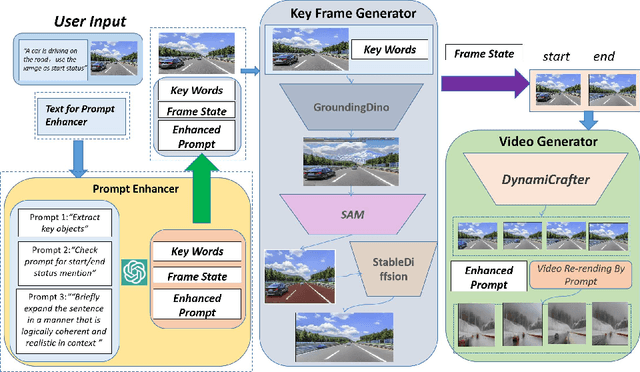
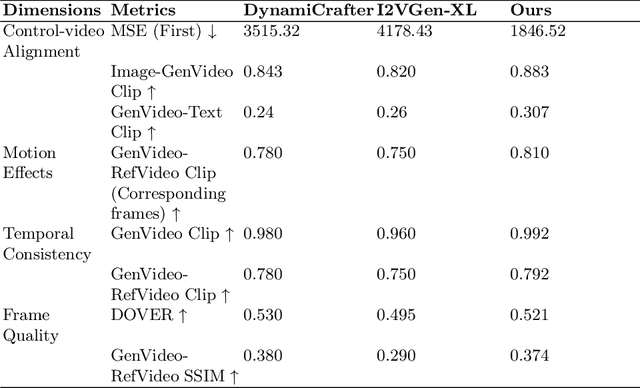


Several text-to-video diffusion models have demonstrated commendable capabilities in synthesizing high-quality video content. However, it remains a formidable challenge pertaining to maintaining temporal consistency and ensuring action smoothness throughout the generated sequences. In this paper, we present an innovative video generation AI agent that harnesses the power of Sora-inspired multimodal learning to build skilled world models framework based on textual prompts and accompanying images. The framework includes two parts: prompt enhancer and full video translation. The first part employs the capabilities of ChatGPT to meticulously distill and proactively construct precise prompts for each subsequent step, thereby guaranteeing the utmost accuracy in prompt communication and accurate execution in following model operations. The second part employ compatible with existing advanced diffusion techniques to expansively generate and refine the key frame at the conclusion of a video. Then we can expertly harness the power of leading and trailing key frames to craft videos with enhanced temporal consistency and action smoothness. The experimental results confirm that our method has strong effectiveness and novelty in constructing world models from text and image inputs over the other methods.
Embracing Language Inclusivity and Diversity in CLIP through Continual Language Learning
Jan 30, 2024

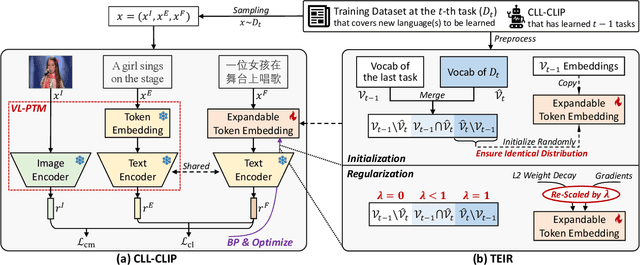
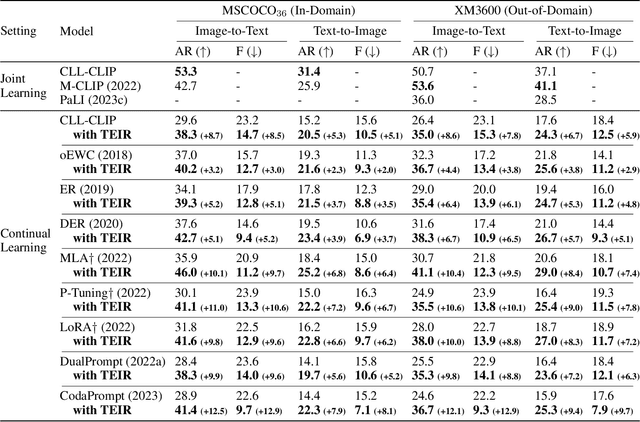
While vision-language pre-trained models (VL-PTMs) have advanced multimodal research in recent years, their mastery in a few languages like English restricts their applicability in broader communities. To this end, there is an increasing interest in developing multilingual VL models via a joint-learning setup, which, however, could be unrealistic due to expensive costs and data availability. In this work, we propose to extend VL-PTMs' language capacity by continual language learning (CLL), where a model needs to update its linguistic knowledge incrementally without suffering from catastrophic forgetting (CF). We begin our study by introducing a model dubbed CLL-CLIP, which builds upon CLIP, a prevailing VL-PTM that has acquired image-English text alignment. Specifically, CLL-CLIP contains an expandable token embedding layer to handle linguistic differences. It solely trains token embeddings to improve memory stability and is optimized under cross-modal and cross-lingual objectives to learn the alignment between images and multilingual texts. To alleviate CF raised by covariate shift and lexical overlap, we further propose a novel approach that ensures the identical distribution of all token embeddings during initialization and regularizes token embedding learning during training. We construct a CLL benchmark covering 36 languages based on MSCOCO and XM3600 datasets and then evaluate multilingual image-text retrieval performance. Extensive experiments verify the effectiveness of CLL-CLIP and show that our approach can boost CLL-CLIP, e.g., by 6.7% in text-to-image average Recall@1 on XM3600, and improve various state-of-the-art methods consistently. Our code and data are available at \url{https://github.com/yangbang18/CLFM}.
Improving Medical Report Generation with Adapter Tuning and Knowledge Enhancement in Vision-Language Foundation Models
Dec 07, 2023Medical report generation demands automatic creation of coherent and precise descriptions for medical images. However, the scarcity of labelled medical image-report pairs poses formidable challenges in developing large-scale neural networks capable of harnessing the potential of artificial intelligence, exemplified by large language models. This study builds upon the state-of-the-art vision-language pre-training and fine-tuning approach, BLIP-2, to customize general large-scale foundation models. Integrating adapter tuning and a medical knowledge enhancement loss, our model significantly improves accuracy and coherence. Validation on the dataset of ImageCLEFmedical 2023 demonstrates our model's prowess, achieving the best-averaged results against several state-of-the-art methods. Significant improvements in ROUGE and CIDEr underscore our method's efficacy, highlighting promising outcomes for the rapid medical-domain adaptation of the vision-language foundation models in addressing challenges posed by data scarcity.
UnifiedVisionGPT: Streamlining Vision-Oriented AI through Generalized Multimodal Framework
Nov 16, 2023


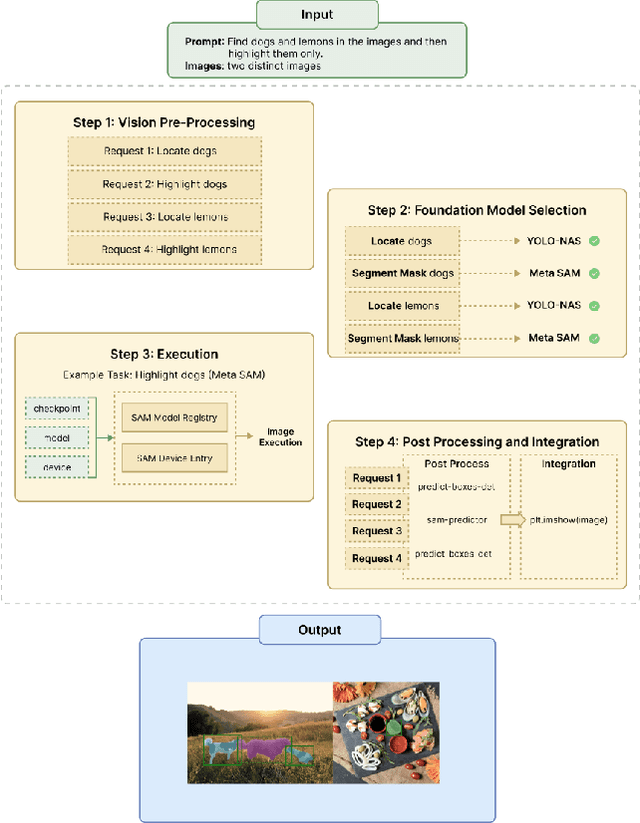
In the current landscape of artificial intelligence, foundation models serve as the bedrock for advancements in both language and vision domains. OpenAI GPT-4 has emerged as the pinnacle in large language models (LLMs), while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models such as Meta's SAM and DINO, and YOLOS. However, the financial and computational burdens of training new models from scratch remain a significant barrier to progress. In response to this challenge, we introduce UnifiedVisionGPT, a novel framework designed to consolidate and automate the integration of SOTA vision models, thereby facilitating the development of vision-oriented AI. UnifiedVisionGPT distinguishes itself through four key features: (1) provides a versatile multimodal framework adaptable to a wide range of applications, building upon the strengths of multimodal foundation models; (2) seamlessly integrates various SOTA vision models to create a comprehensive multimodal platform, capitalizing on the best components of each model; (3) prioritizes vision-oriented AI, ensuring a more rapid progression in the CV domain compared to the current trajectory of LLMs; and (4) introduces automation in the selection of SOTA vision models, generating optimal results based on diverse multimodal inputs such as text prompts and images. This paper outlines the architecture and capabilities of UnifiedVisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, generalization, and performance. Our implementation, along with the unified multimodal framework and comprehensive dataset, is made publicly available at https://github.com/LHBuilder/SA-Segment-Anything.
MultiCapCLIP: Auto-Encoding Prompts for Zero-Shot Multilingual Visual Captioning
Aug 25, 2023



Supervised visual captioning models typically require a large scale of images or videos paired with descriptions in a specific language (i.e., the vision-caption pairs) for training. However, collecting and labeling large-scale datasets is time-consuming and expensive for many scenarios and languages. Therefore, sufficient labeled pairs are usually not available. To deal with the label shortage problem, we present a simple yet effective zero-shot approach MultiCapCLIP that can generate visual captions for different scenarios and languages without any labeled vision-caption pairs of downstream datasets. In the training stage, MultiCapCLIP only requires text data for input. Then it conducts two main steps: 1) retrieving concept prompts that preserve the corresponding domain knowledge of new scenarios; 2) auto-encoding the prompts to learn writing styles to output captions in a desired language. In the testing stage, MultiCapCLIP instead takes visual data as input directly to retrieve the concept prompts to generate the final visual descriptions. The extensive experiments on image and video captioning across four benchmarks and four languages (i.e., English, Chinese, German, and French) confirm the effectiveness of our approach. Compared with state-of-the-art zero-shot and weakly-supervised methods, our method achieves 4.8% and 21.5% absolute improvements in terms of BLEU@4 and CIDEr metrics. Our code is available at https://github.com/yangbang18/MultiCapCLIP.
Multimodal Prompt Learning for Product Title Generation with Extremely Limited Labels
Jul 05, 2023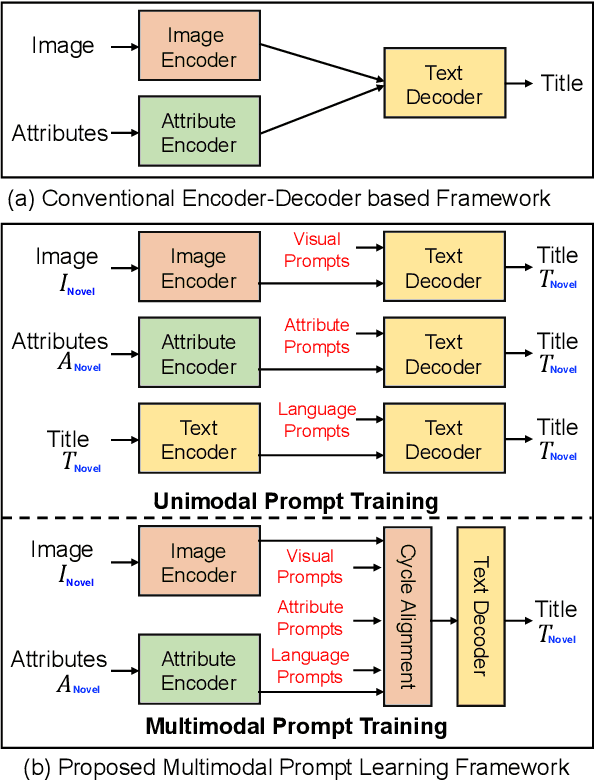
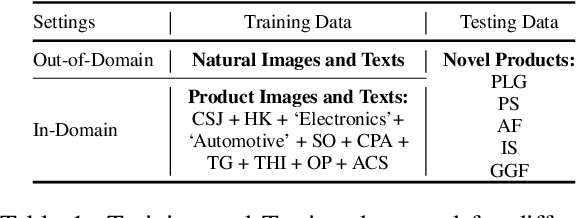
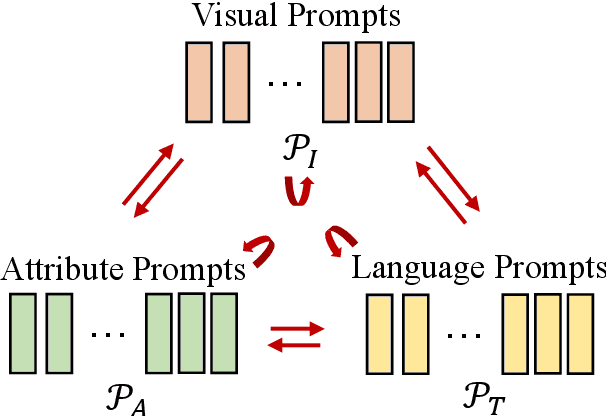
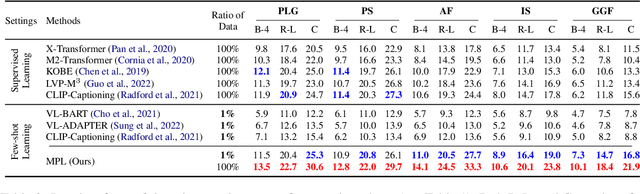
Generating an informative and attractive title for the product is a crucial task for e-commerce. Most existing works follow the standard multimodal natural language generation approaches, e.g., image captioning, and employ the large scale of human-labelled datasets to train desirable models. However, for novel products, especially in a different domain, there are few existing labelled data. In this paper, we propose a prompt-based approach, i.e., the Multimodal Prompt Learning framework, to accurately and efficiently generate titles for novel products with limited labels. We observe that the core challenges of novel product title generation are the understanding of novel product characteristics and the generation of titles in a novel writing style. To this end, we build a set of multimodal prompts from different modalities to preserve the corresponding characteristics and writing styles of novel products. As a result, with extremely limited labels for training, the proposed method can retrieve the multimodal prompts to generate desirable titles for novel products. The experiments and analyses are conducted on five novel product categories under both the in-domain and out-of-domain experimental settings. The results show that, with only 1% of downstream labelled data for training, our proposed approach achieves the best few-shot results and even achieves competitive results with fully-supervised methods trained on 100% of training data; With the full labelled data for training, our method achieves state-of-the-art results.
Customizing General-Purpose Foundation Models for Medical Report Generation
Jun 09, 2023
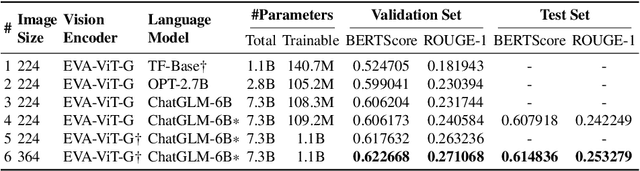


Medical caption prediction which can be regarded as a task of medical report generation (MRG), requires the automatic generation of coherent and accurate captions for the given medical images. However, the scarcity of labelled medical image-report pairs presents great challenges in the development of deep and large-scale neural networks capable of harnessing the potential artificial general intelligence power like large language models (LLMs). In this work, we propose customizing off-the-shelf general-purpose large-scale pre-trained models, i.e., foundation models (FMs), in computer vision and natural language processing with a specific focus on medical report generation. Specifically, following BLIP-2, a state-of-the-art vision-language pre-training approach, we introduce our encoder-decoder-based MRG model. This model utilizes a lightweight query Transformer to connect two FMs: the giant vision Transformer EVA-ViT-g and a bilingual LLM trained to align with human intentions (referred to as ChatGLM-6B). Furthermore, we conduct ablative experiments on the trainable components of the model to identify the crucial factors for effective transfer learning. Our findings demonstrate that unfreezing EVA-ViT-g to learn medical image representations, followed by parameter-efficient training of ChatGLM-6B to capture the writing styles of medical reports, is essential for achieving optimal results. Our best attempt (PCLmed Team) achieved the 4th and the 2nd, respectively, out of 13 participating teams, based on the BERTScore and ROUGE-1 metrics, in the ImageCLEFmedical Caption 2023 Caption Prediction Task competition.