 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Mar 22, 2024



The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
Mar 14, 2024

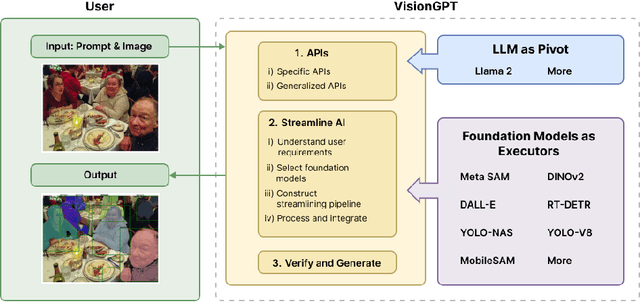

With the emergence of large language models (LLMs) and vision foundation models, how to combine the intelligence and capacity of these open-sourced or API-available models to achieve open-world visual perception remains an open question. In this paper, we introduce VisionGPT to consolidate and automate the integration of state-of-the-art foundation models, thereby facilitating vision-language understanding and the development of vision-oriented AI. VisionGPT builds upon a generalized multimodal framework that distinguishes itself through three key features: (1) utilizing LLMs (e.g., LLaMA-2) as the pivot to break down users' requests into detailed action proposals to call suitable foundation models; (2) integrating multi-source outputs from foundation models automatically and generating comprehensive responses for users; (3) adaptable to a wide range of applications such as text-conditioned image understanding/generation/editing and visual question answering. This paper outlines the architecture and capabilities of VisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, and generalization, and performance. Our code and models will be made publicly available. Keywords: VisionGPT, Open-world visual perception, Vision-language understanding, Large language model, and Foundation model
WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
Mar 10, 2024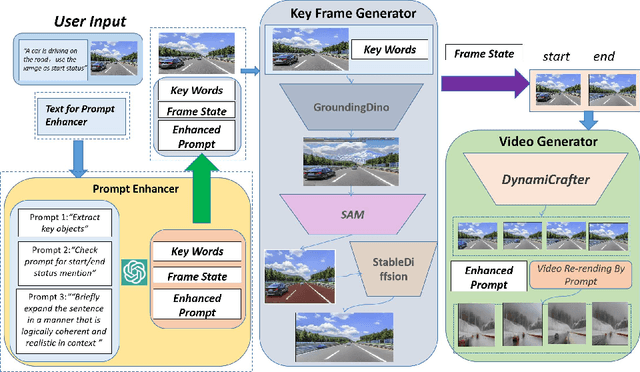
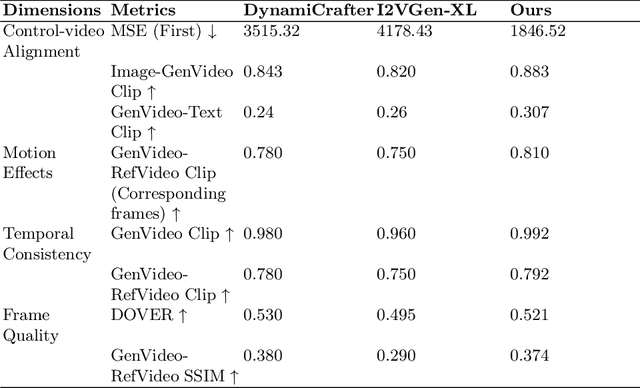


Several text-to-video diffusion models have demonstrated commendable capabilities in synthesizing high-quality video content. However, it remains a formidable challenge pertaining to maintaining temporal consistency and ensuring action smoothness throughout the generated sequences. In this paper, we present an innovative video generation AI agent that harnesses the power of Sora-inspired multimodal learning to build skilled world models framework based on textual prompts and accompanying images. The framework includes two parts: prompt enhancer and full video translation. The first part employs the capabilities of ChatGPT to meticulously distill and proactively construct precise prompts for each subsequent step, thereby guaranteeing the utmost accuracy in prompt communication and accurate execution in following model operations. The second part employ compatible with existing advanced diffusion techniques to expansively generate and refine the key frame at the conclusion of a video. Then we can expertly harness the power of leading and trailing key frames to craft videos with enhanced temporal consistency and action smoothness. The experimental results confirm that our method has strong effectiveness and novelty in constructing world models from text and image inputs over the other methods.
UnifiedVisionGPT: Streamlining Vision-Oriented AI through Generalized Multimodal Framework
Nov 16, 2023


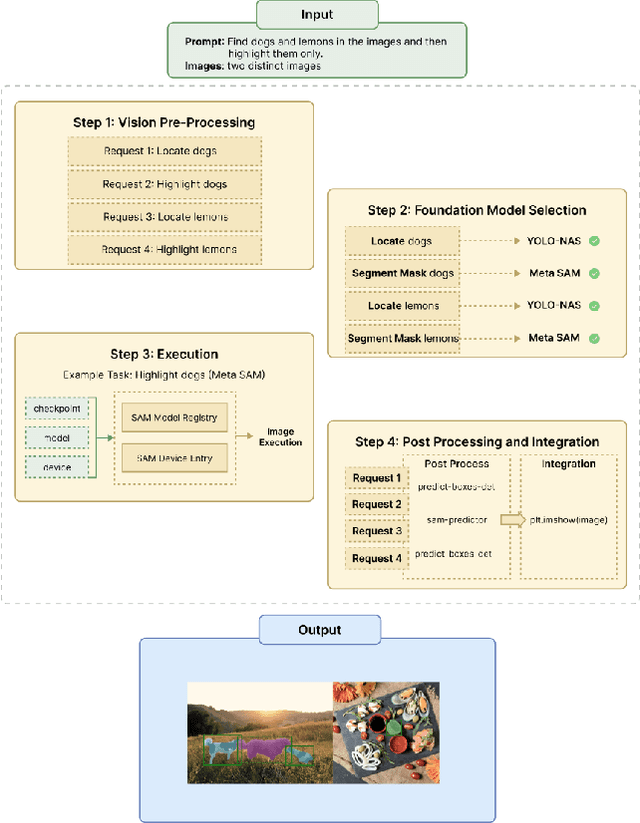
In the current landscape of artificial intelligence, foundation models serve as the bedrock for advancements in both language and vision domains. OpenAI GPT-4 has emerged as the pinnacle in large language models (LLMs), while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models such as Meta's SAM and DINO, and YOLOS. However, the financial and computational burdens of training new models from scratch remain a significant barrier to progress. In response to this challenge, we introduce UnifiedVisionGPT, a novel framework designed to consolidate and automate the integration of SOTA vision models, thereby facilitating the development of vision-oriented AI. UnifiedVisionGPT distinguishes itself through four key features: (1) provides a versatile multimodal framework adaptable to a wide range of applications, building upon the strengths of multimodal foundation models; (2) seamlessly integrates various SOTA vision models to create a comprehensive multimodal platform, capitalizing on the best components of each model; (3) prioritizes vision-oriented AI, ensuring a more rapid progression in the CV domain compared to the current trajectory of LLMs; and (4) introduces automation in the selection of SOTA vision models, generating optimal results based on diverse multimodal inputs such as text prompts and images. This paper outlines the architecture and capabilities of UnifiedVisionGPT, demonstrating its potential to revolutionize the field of computer vision through enhanced efficiency, versatility, generalization, and performance. Our implementation, along with the unified multimodal framework and comprehensive dataset, is made publicly available at https://github.com/LHBuilder/SA-Segment-Anything.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.