 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Globalizing Fairness: A Mixed Methods Study on Colonialism, AI, and Health in Africa
Mar 11, 2024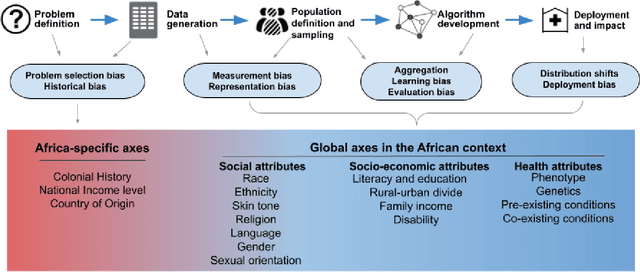
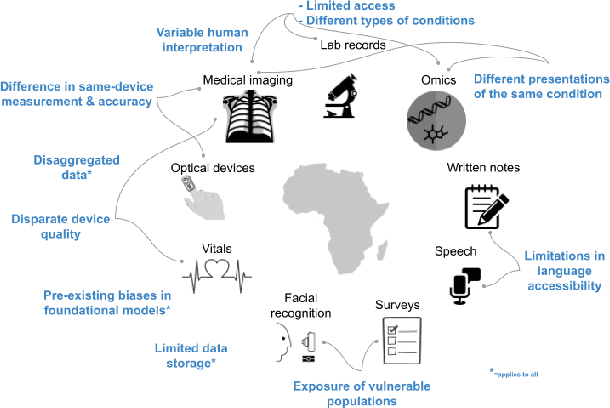
With growing application of machine learning (ML) technologies in healthcare, there have been calls for developing techniques to understand and mitigate biases these systems may exhibit. Fair-ness considerations in the development of ML-based solutions for health have particular implications for Africa, which already faces inequitable power imbalances between the Global North and South.This paper seeks to explore fairness for global health, with Africa as a case study. We conduct a scoping review to propose axes of disparities for fairness consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. We then conduct qualitative research studies with 672 general population study participants and 28 experts inML, health, and policy focused on Africa to obtain corroborative evidence on the proposed axes of disparities. Our analysis focuses on colonialism as the attribute of interest and examines the interplay between artificial intelligence (AI), health, and colonialism. Among the pre-identified attributes, we found that colonial history, country of origin, and national income level were specific axes of disparities that participants believed would cause an AI system to be biased.However, there was also divergence of opinion between experts and general population participants. Whereas experts generally expressed a shared view about the relevance of colonial history for the development and implementation of AI technologies in Africa, the majority of the general population participants surveyed did not think there was a direct link between AI and colonialism. Based on these findings, we provide practical recommendations for developing fairness-aware ML solutions for health in Africa.
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
Dec 21, 2023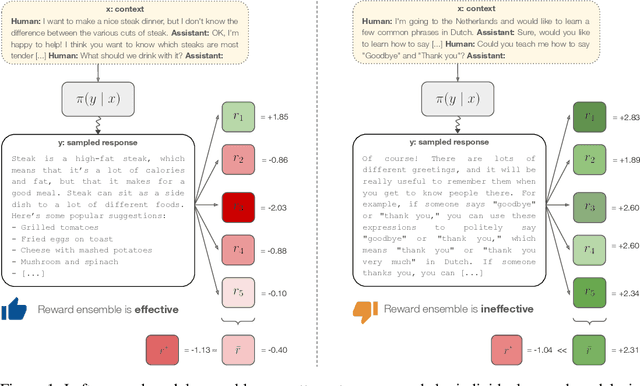

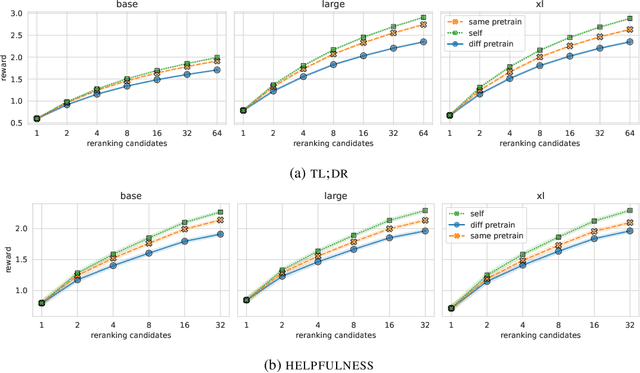
Reward models play a key role in aligning language model applications towards human preferences. However, this setup creates an incentive for the language model to exploit errors in the reward model to achieve high estimated reward, a phenomenon often termed \emph{reward hacking}. A natural mitigation is to train an ensemble of reward models, aggregating over model outputs to obtain a more robust reward estimate. We explore the application of reward ensembles to alignment at both training time (through reinforcement learning) and inference time (through reranking). First, we show that reward models are \emph{underspecified}: reward models that perform similarly in-distribution can yield very different rewards when used in alignment, due to distribution shift. Second, underspecification results in overoptimization, where alignment to one reward model does not improve reward as measured by another reward model trained on the same data. Third, overoptimization is mitigated by the use of reward ensembles, and ensembles that vary by their \emph{pretraining} seeds lead to better generalization than ensembles that differ only by their \emph{fine-tuning} seeds, with both outperforming individual reward models. However, even pretrain reward ensembles do not eliminate reward hacking: we show several qualitative reward hacking phenomena that are not mitigated by ensembling because all reward models in the ensemble exhibit similar error patterns.
Towards Expert-Level Medical Question Answering with Large Language Models
May 16, 2023



Recent artificial intelligence (AI) systems have reached milestones in "grand challenges" ranging from Go to protein-folding. The capability to retrieve medical knowledge, reason over it, and answer medical questions comparably to physicians has long been viewed as one such grand challenge. Large language models (LLMs) have catalyzed significant progress in medical question answering; Med-PaLM was the first model to exceed a "passing" score in US Medical Licensing Examination (USMLE) style questions with a score of 67.2% on the MedQA dataset. However, this and other prior work suggested significant room for improvement, especially when models' answers were compared to clinicians' answers. Here we present Med-PaLM 2, which bridges these gaps by leveraging a combination of base LLM improvements (PaLM 2), medical domain finetuning, and prompting strategies including a novel ensemble refinement approach. Med-PaLM 2 scored up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19% and setting a new state-of-the-art. We also observed performance approaching or exceeding state-of-the-art across MedMCQA, PubMedQA, and MMLU clinical topics datasets. We performed detailed human evaluations on long-form questions along multiple axes relevant to clinical applications. In pairwise comparative ranking of 1066 consumer medical questions, physicians preferred Med-PaLM 2 answers to those produced by physicians on eight of nine axes pertaining to clinical utility (p < 0.001). We also observed significant improvements compared to Med-PaLM on every evaluation axis (p < 0.001) on newly introduced datasets of 240 long-form "adversarial" questions to probe LLM limitations. While further studies are necessary to validate the efficacy of these models in real-world settings, these results highlight rapid progress towards physician-level performance in medical question answering.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
A collection of the accepted abstracts for the Machine Learning for Health symposium 2021
Nov 30, 2021A collection of the accepted abstracts for the Machine Learning for Health (ML4H) symposium 2021. This index is not complete, as some accepted abstracts chose to opt-out of inclusion.
Counterfactual Reasoning for Fair Clinical Risk Prediction
Jul 14, 2019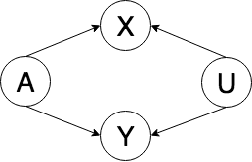
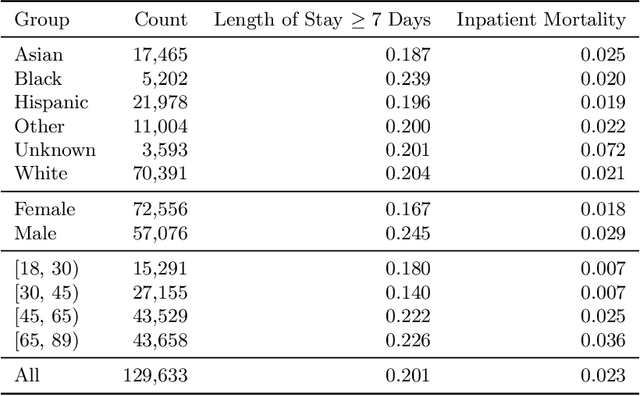
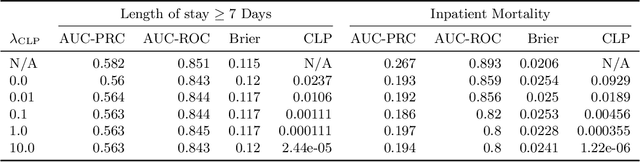
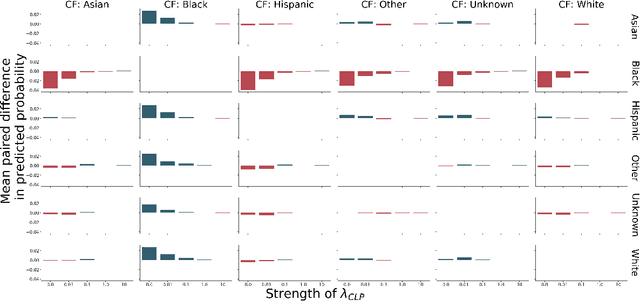
The use of machine learning systems to support decision making in healthcare raises questions as to what extent these systems may introduce or exacerbate disparities in care for historically underrepresented and mistreated groups, due to biases implicitly embedded in observational data in electronic health records. To address this problem in the context of clinical risk prediction models, we develop an augmented counterfactual fairness criteria to extend the group fairness criteria of equalized odds to an individual level. We do so by requiring that the same prediction be made for a patient, and a counterfactual patient resulting from changing a sensitive attribute, if the factual and counterfactual outcomes do not differ. We investigate the extent to which the augmented counterfactual fairness criteria may be applied to develop fair models for prolonged inpatient length of stay and mortality with observational electronic health records data. As the fairness criteria is ill-defined without knowledge of the data generating process, we use a variational autoencoder to perform counterfactual inference in the context of an assumed causal graph. While our technique provides a means to trade off maintenance of fairness with reduction in predictive performance in the context of a learned generative model, further work is needed to assess the generality of this approach.
Predicting Inpatient Discharge Prioritization With Electronic Health Records
Dec 02, 2018
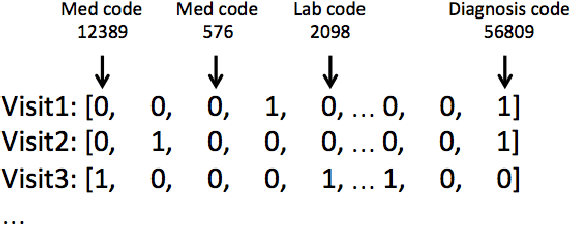


Identifying patients who will be discharged within 24 hours can improve hospital resource management and quality of care. We studied this problem using eight years of Electronic Health Records (EHR) data from Stanford Hospital. We fit models to predict 24 hour discharge across the entire inpatient population. The best performing models achieved an area under the receiver-operator characteristic curve (AUROC) of 0.85 and an AUPRC of 0.53 on a held out test set. This model was also well calibrated. Finally, we analyzed the utility of this model in a decision theoretic framework to identify regions of ROC space in which using the model increases expected utility compared to the trivial always negative or always positive classifiers.
The Effectiveness of Multitask Learning for Phenotyping with Electronic Health Records Data
Oct 04, 2018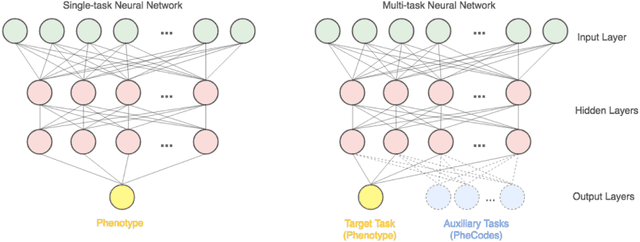
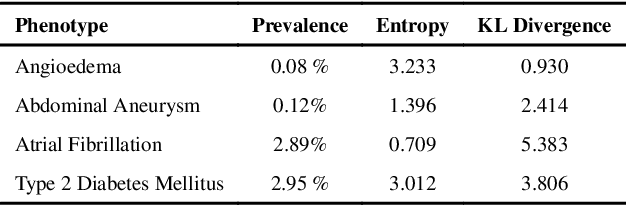
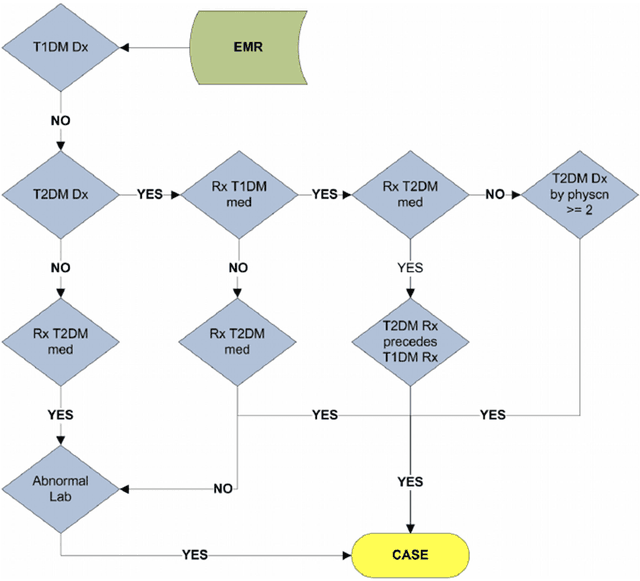
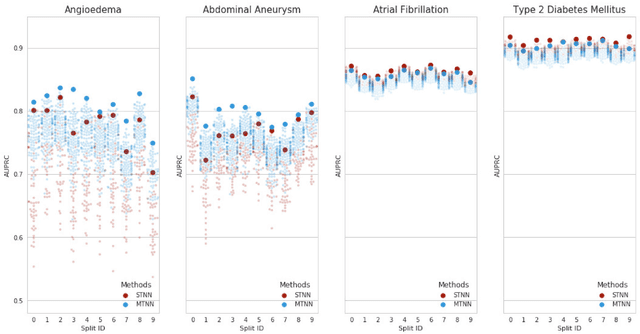
Electronic phenotyping is the task of ascertaining whether an individual has a medical condition of interest by analyzing their medical record and is foundational in clinical informatics. Increasingly, electronic phenotyping is performed via supervised learning. We investigate the effectiveness of multitask learning for phenotyping using electronic health records (EHR) data. Multitask learning aims to improve model performance on a target task by jointly learning additional auxiliary tasks and has been used in disparate areas of machine learning. However, its utility when applied to EHR data has not been established, and prior work suggests that its benefits are inconsistent. We present experiments that elucidate when multitask learning with neural nets improves performance for phenotyping using EHR data relative to neural nets trained for a single phenotype and to well-tuned logistic regression baselines. We find that multitask neural nets consistently outperform single-task neural nets for rare phenotypes but underperform for relatively more common phenotypes. The effect size increases as more auxiliary tasks are added. Moreover, multitask learning reduces the sensitivity of neural nets to hyperparameter settings for rare phenotypes. Last, we quantify phenotype complexity and find that neural nets trained with or without multitask learning do not improve on simple baselines unless the phenotypes are sufficiently complex.
Creating Fair Models of Atherosclerotic Cardiovascular Disease Risk
Sep 16, 2018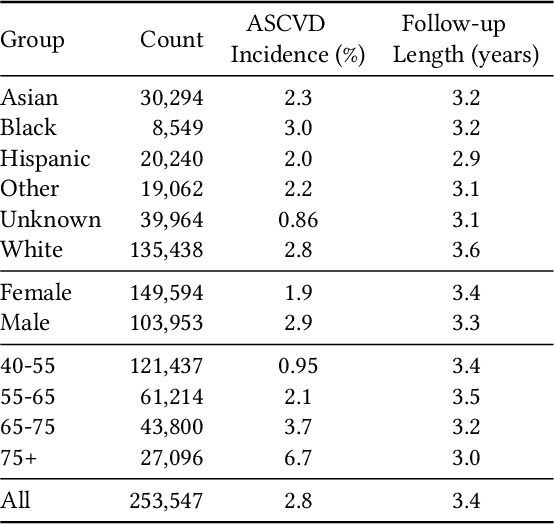

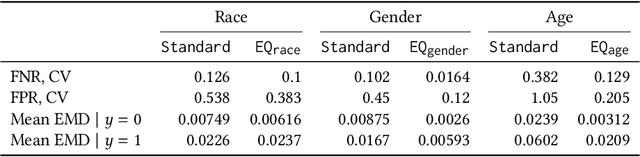
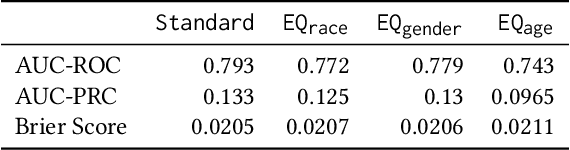
Guidelines for the management of atherosclerotic cardiovascular disease (ASCVD) recommend the use of risk stratification models to identify patients most likely to benefit from cholesterol-lowering and other therapies. These models have differential performance across race and gender groups with inconsistent behavior across studies, potentially resulting in an inequitable distribution of beneficial therapy. In this work, we leverage adversarial learning and a large observational cohort extracted from electronic health records (EHRs) to develop a "fair" ASCVD risk prediction model with reduced variability in error rates across groups. We empirically demonstrate that our approach is capable of aligning the distribution of risk predictions conditioned on the outcome across several groups simultaneously for models built from high-dimensional EHR data. We also discuss the relevance of these results in the context of the empirical trade-off between fairness and model performance.