 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
Amplify Initiative: Building A Localized Data Platform for Globalized AI
Apr 18, 2025Current AI models often fail to account for local context and language, given the predominance of English and Western internet content in their training data. This hinders the global relevance, usefulness, and safety of these models as they gain more users around the globe. Amplify Initiative, a data platform and methodology, leverages expert communities to collect diverse, high-quality data to address the limitations of these models. The platform is designed to enable co-creation of datasets, provide access to high-quality multilingual datasets, and offer recognition to data authors. This paper presents the approach to co-creating datasets with domain experts (e.g., health workers, teachers) through a pilot conducted in Sub-Saharan Africa (Ghana, Kenya, Malawi, Nigeria, and Uganda). In partnership with local researchers situated in these countries, the pilot demonstrated an end-to-end approach to co-creating data with 155 experts in sensitive domains (e.g., physicians, bankers, anthropologists, human and civil rights advocates). This approach, implemented with an Android app, resulted in an annotated dataset of 8,091 adversarial queries in seven languages (e.g., Luganda, Swahili, Chichewa), capturing nuanced and contextual information related to key themes such as misinformation and public interest topics. This dataset in turn can be used to evaluate models for their safety and cultural relevance within the context of these languages.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
The Case for Globalizing Fairness: A Mixed Methods Study on Colonialism, AI, and Health in Africa
Mar 11, 2024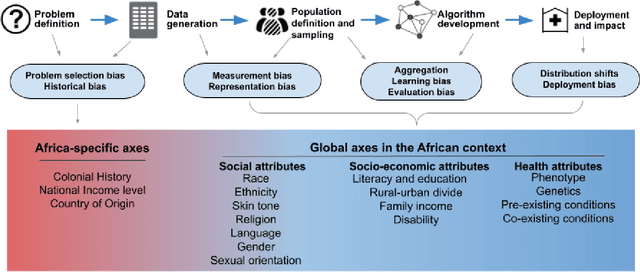
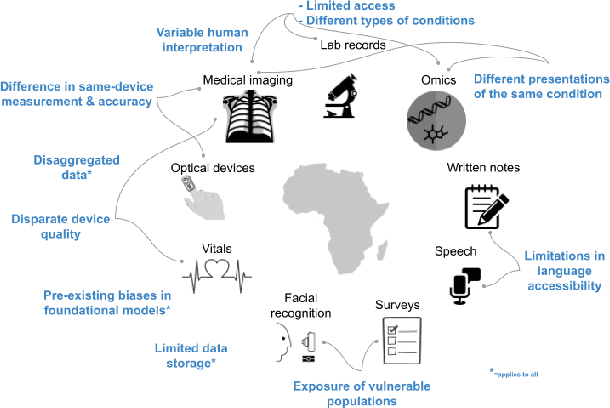
With growing application of machine learning (ML) technologies in healthcare, there have been calls for developing techniques to understand and mitigate biases these systems may exhibit. Fair-ness considerations in the development of ML-based solutions for health have particular implications for Africa, which already faces inequitable power imbalances between the Global North and South.This paper seeks to explore fairness for global health, with Africa as a case study. We conduct a scoping review to propose axes of disparities for fairness consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. We then conduct qualitative research studies with 672 general population study participants and 28 experts inML, health, and policy focused on Africa to obtain corroborative evidence on the proposed axes of disparities. Our analysis focuses on colonialism as the attribute of interest and examines the interplay between artificial intelligence (AI), health, and colonialism. Among the pre-identified attributes, we found that colonial history, country of origin, and national income level were specific axes of disparities that participants believed would cause an AI system to be biased.However, there was also divergence of opinion between experts and general population participants. Whereas experts generally expressed a shared view about the relevance of colonial history for the development and implementation of AI technologies in Africa, the majority of the general population participants surveyed did not think there was a direct link between AI and colonialism. Based on these findings, we provide practical recommendations for developing fairness-aware ML solutions for health in Africa.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024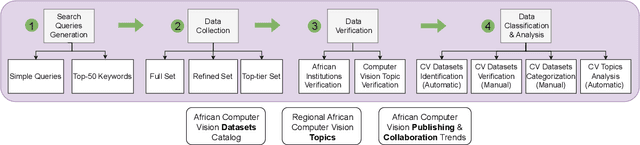


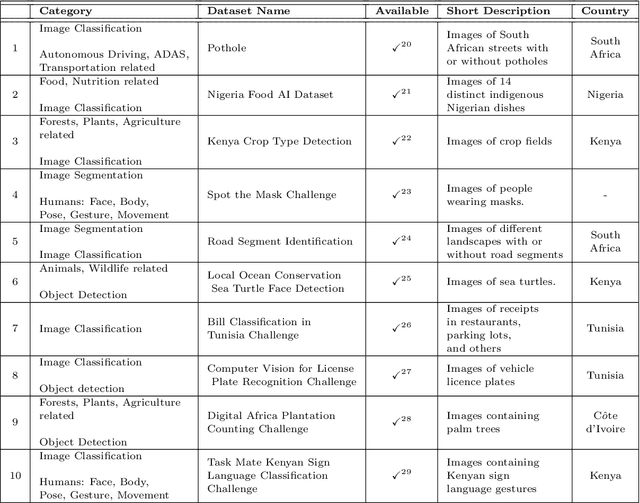
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Towards a Better Understanding of the Computer Vision Research Community in Africa
May 11, 2023



Computer vision is a broad field of study that encompasses different tasks (e.g., object detection, semantic segmentation, 3D reconstruction). Although computer vision is relevant to the African communities in various applications, yet computer vision research is under-explored in the continent and constructs only 0.06% of top-tier publications in the last 10 years. In this paper, our goal is to have a better understanding of the computer vision research conducted in Africa and provide pointers on whether there is equity in research or not. We do this through an empirical analysis of the African computer vision publications that are Scopus indexed. We first study the opportunities available for African institutions to publish in top-tier computer vision venues. We show that African publishing trends in top-tier venues over the years do not exhibit consistent growth. We also devise a novel way to retrieve African authors through their affiliation history to have a better understanding of their contributions in top-tier venues. Moreover, we study all computer vision publications beyond top-tier venues in different African regions to find that mainly Northern and Southern Africa are publishing in computer vision with more than 85% of African publications. Finally, we present the most recurring keywords in computer vision publications. In summary, our analysis reveals that African researchers are key contributors to African research, yet there exists multiple barriers to publish in top-tier venues and the current trend of topics published in the continent might not necessarily reflect the communities' needs. This work is part of a community based effort that is focused on improving computer vision research in Africa.
Globalizing Fairness Attributes in Machine Learning: A Case Study on Health in Africa
Apr 05, 2023With growing machine learning (ML) applications in healthcare, there have been calls for fairness in ML to understand and mitigate ethical concerns these systems may pose. Fairness has implications for global health in Africa, which already has inequitable power imbalances between the Global North and South. This paper seeks to explore fairness for global health, with Africa as a case study. We propose fairness attributes for consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. This work serves as a basis and call for action for furthering research into fairness in global health.
AfroLM: A Self-Active Learning-based Multilingual Pretrained Language Model for 23 African Languages
Nov 07, 2022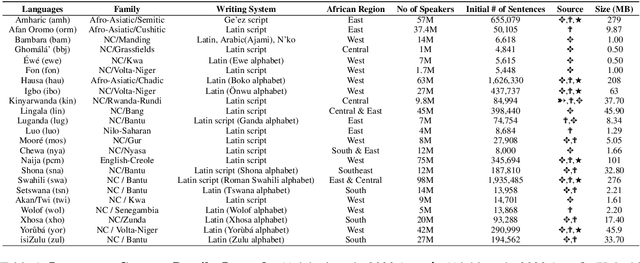
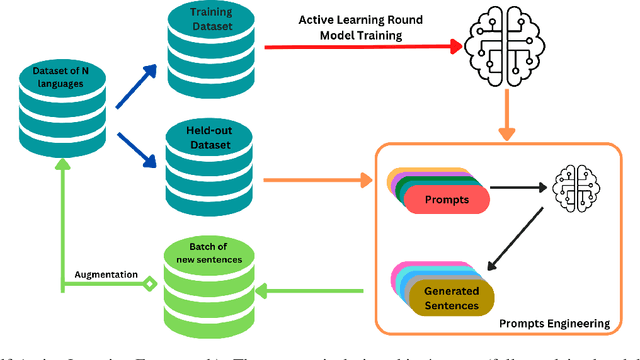


In recent years, multilingual pre-trained language models have gained prominence due to their remarkable performance on numerous downstream Natural Language Processing tasks (NLP). However, pre-training these large multilingual language models requires a lot of training data, which is not available for African Languages. Active learning is a semi-supervised learning algorithm, in which a model consistently and dynamically learns to identify the most beneficial samples to train itself on, in order to achieve better optimization and performance on downstream tasks. Furthermore, active learning effectively and practically addresses real-world data scarcity. Despite all its benefits, active learning, in the context of NLP and especially multilingual language models pretraining, has received little consideration. In this paper, we present AfroLM, a multilingual language model pretrained from scratch on 23 African languages (the largest effort to date) using our novel self-active learning framework. Pretrained on a dataset significantly (14x) smaller than existing baselines, AfroLM outperforms many multilingual pretrained language models (AfriBERTa, XLMR-base, mBERT) on various NLP downstream tasks (NER, text classification, and sentiment analysis). Additional out-of-domain sentiment analysis experiments show that \textbf{AfroLM} is able to generalize well across various domains. We release the code source, and our datasets used in our framework at https://github.com/bonaventuredossou/MLM_AL.