 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024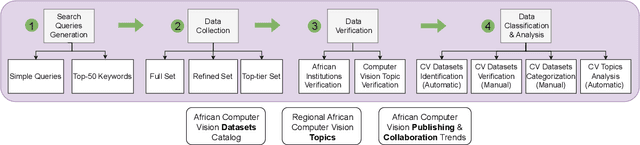


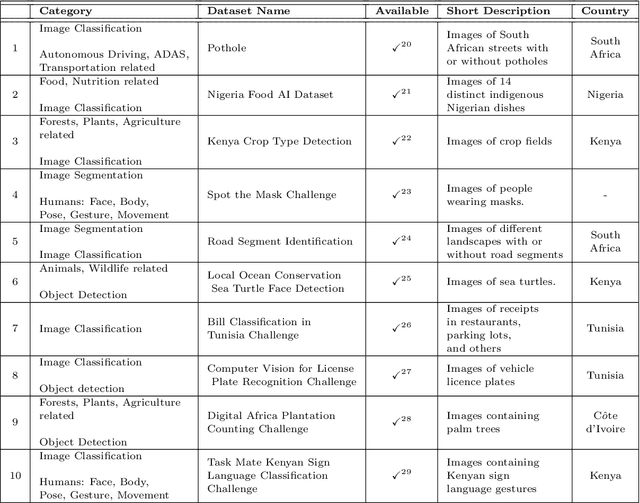
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023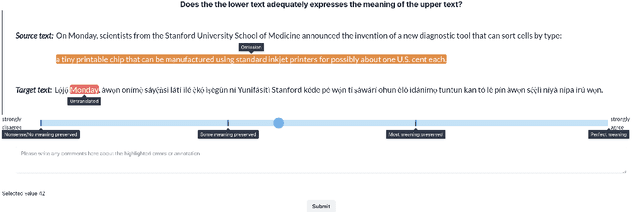
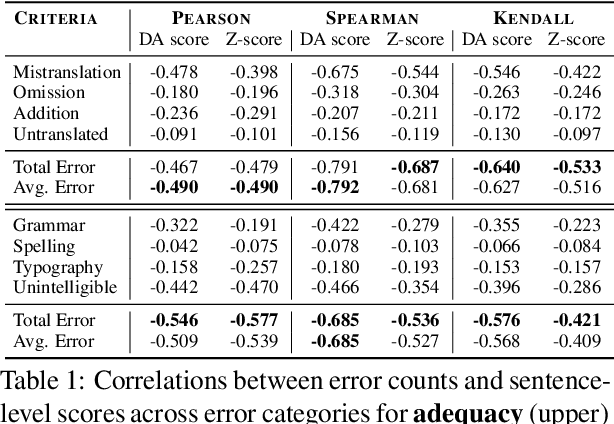
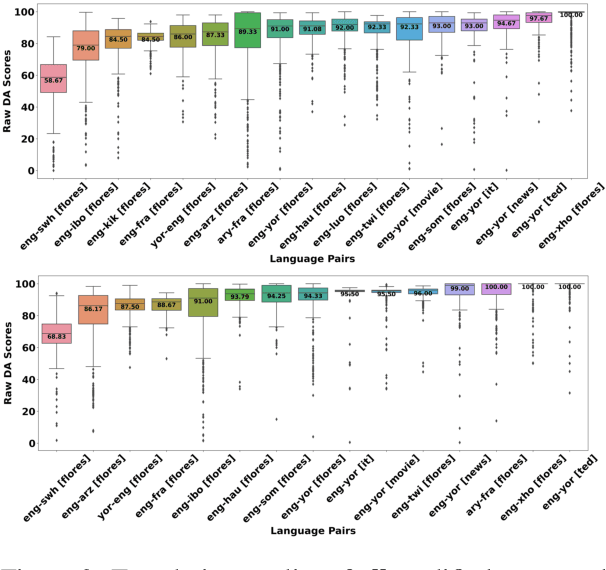
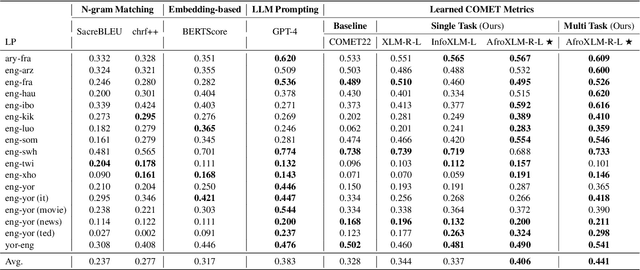
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
Towards a Better Understanding of the Computer Vision Research Community in Africa
May 11, 2023



Computer vision is a broad field of study that encompasses different tasks (e.g., object detection, semantic segmentation, 3D reconstruction). Although computer vision is relevant to the African communities in various applications, yet computer vision research is under-explored in the continent and constructs only 0.06% of top-tier publications in the last 10 years. In this paper, our goal is to have a better understanding of the computer vision research conducted in Africa and provide pointers on whether there is equity in research or not. We do this through an empirical analysis of the African computer vision publications that are Scopus indexed. We first study the opportunities available for African institutions to publish in top-tier computer vision venues. We show that African publishing trends in top-tier venues over the years do not exhibit consistent growth. We also devise a novel way to retrieve African authors through their affiliation history to have a better understanding of their contributions in top-tier venues. Moreover, we study all computer vision publications beyond top-tier venues in different African regions to find that mainly Northern and Southern Africa are publishing in computer vision with more than 85% of African publications. Finally, we present the most recurring keywords in computer vision publications. In summary, our analysis reveals that African researchers are key contributors to African research, yet there exists multiple barriers to publish in top-tier venues and the current trend of topics published in the continent might not necessarily reflect the communities' needs. This work is part of a community based effort that is focused on improving computer vision research in Africa.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023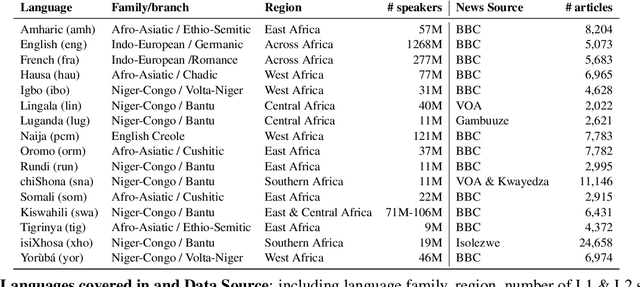
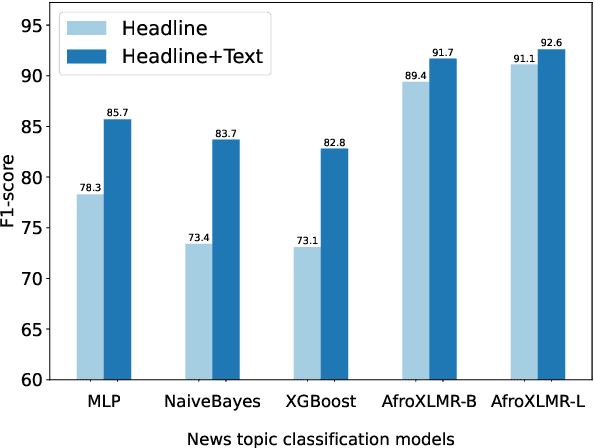
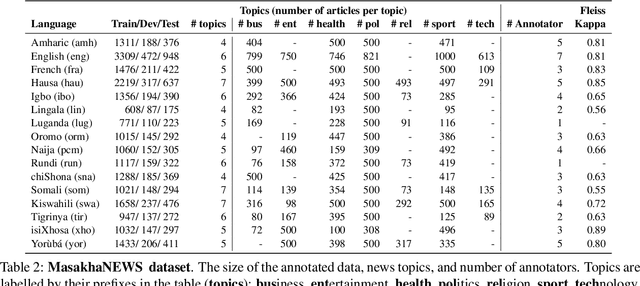
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Adapting to the Low-Resource Double-Bind: Investigating Low-Compute Methods on Low-Resource African Languages
Mar 29, 2023

Many natural language processing (NLP) tasks make use of massively pre-trained language models, which are computationally expensive. However, access to high computational resources added to the issue of data scarcity of African languages constitutes a real barrier to research experiments on these languages. In this work, we explore the applicability of low-compute approaches such as language adapters in the context of this low-resource double-bind. We intend to answer the following question: do language adapters allow those who are doubly bound by data and compute to practically build useful models? Through fine-tuning experiments on African languages, we evaluate their effectiveness as cost-effective approaches to low-resource African NLP. Using solely free compute resources, our results show that language adapters achieve comparable performances to massive pre-trained language models which are heavy on computational resources. This opens the door to further experimentation and exploration on full-extent of language adapters capacities.