 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGSM-Pro: A Simple Strategy for Robust Multilingual Mathematical Reasoning Evaluation
Jan 29, 2026Large language models have made substantial progress in mathematical reasoning. However, benchmark development for multilingual evaluation has lagged behind English in both difficulty and recency. Recently, GSM-Symbolic showed a strong evidence of high variance when models are evaluated on different instantiations of the same question; however, the evaluation was conducted only in English. In this paper, we introduce MGSM-Pro, an extension of MGSM dataset with GSM-Symbolic approach. Our dataset provides five instantiations per MGSM question by varying names, digits and irrelevant context. Evaluations across nine languages reveal that many low-resource languages suffer large performance drops when tested on digit instantiations different from those in the original test set. We further find that some proprietary models, notably Gemini 2.5 Flash and GPT-4.1, are less robust to digit instantiation, whereas Claude 4.0 Sonnet is more robust. Among open models, GPT-OSS 120B and DeepSeek V3 show stronger robustness. Based on these findings, we recommend evaluating each problem using at least five digit-varying instantiations to obtain a more robust and realistic assessment of math reasoning.
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
Masakhane-Afrisenti at SemEval-2023 Task 12: Sentiment Analysis using Afro-centric Language Models and Adapters for Low-resource African Languages
Apr 13, 2023



AfriSenti-SemEval Shared Task 12 of SemEval-2023. The task aims to perform monolingual sentiment classification (sub-task A) for 12 African languages, multilingual sentiment classification (sub-task B), and zero-shot sentiment classification (task C). For sub-task A, we conducted experiments using classical machine learning classifiers, Afro-centric language models, and language-specific models. For task B, we fine-tuned multilingual pre-trained language models that support many of the languages in the task. For task C, we used we make use of a parameter-efficient Adapter approach that leverages monolingual texts in the target language for effective zero-shot transfer. Our findings suggest that using pre-trained Afro-centric language models improves performance for low-resource African languages. We also ran experiments using adapters for zero-shot tasks, and the results suggest that we can obtain promising results by using adapters with a limited amount of resources.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022
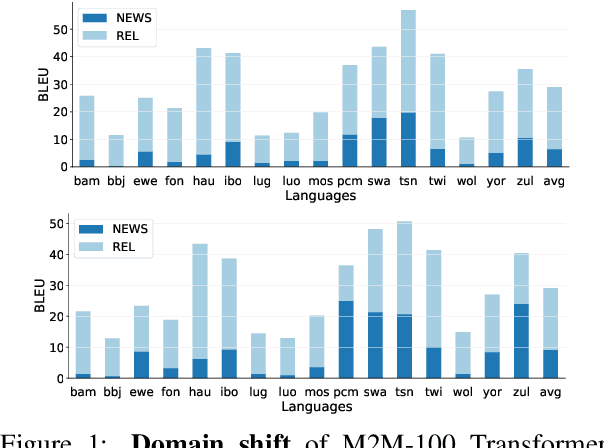

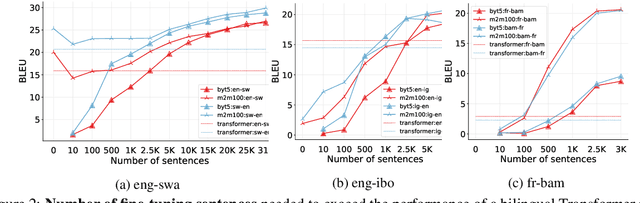
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
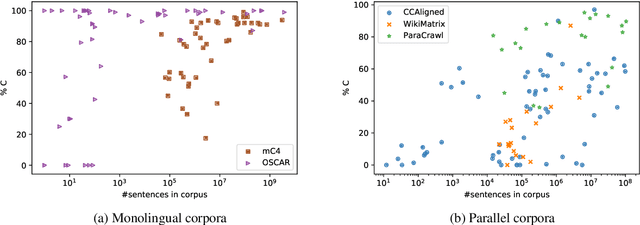

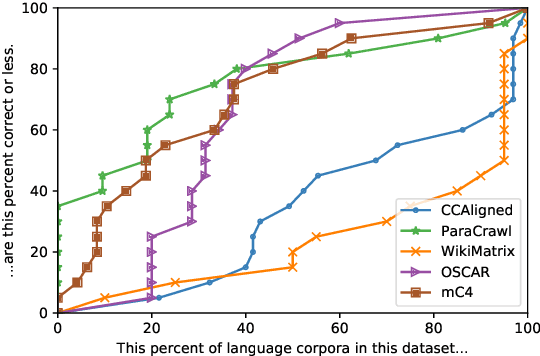
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021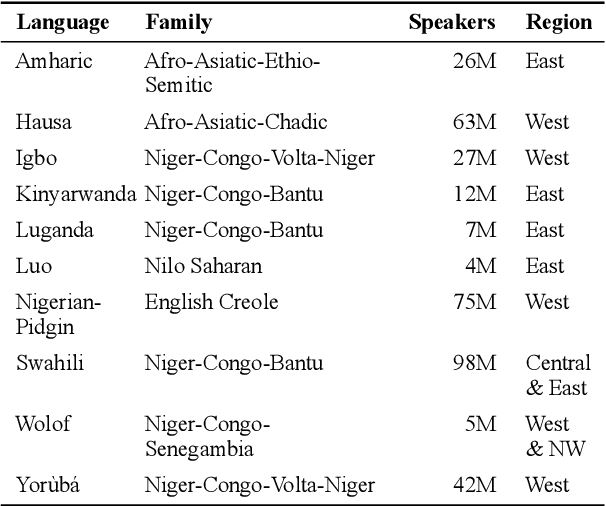

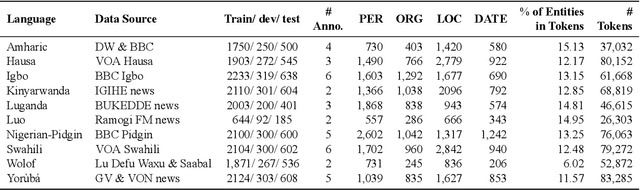
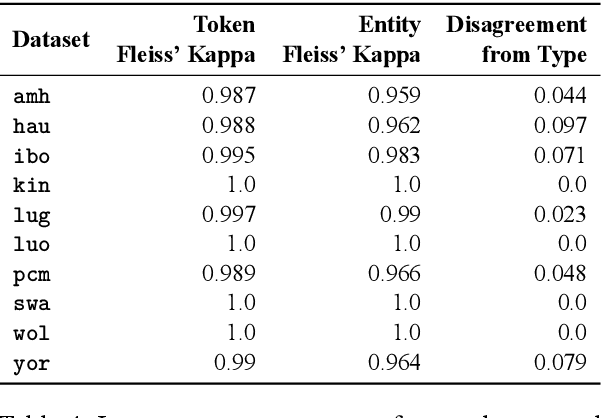
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
MENYO-20k: A Multi-domain English-Yorùbá Corpus for Machine Translation and Domain Adaptation
Mar 15, 2021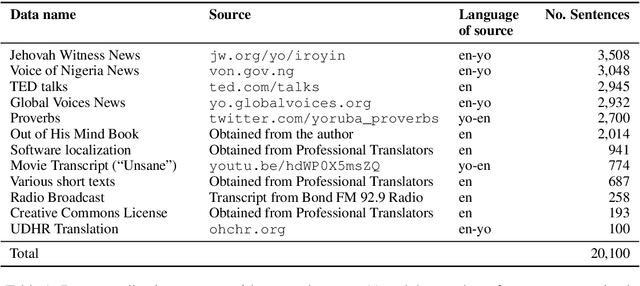
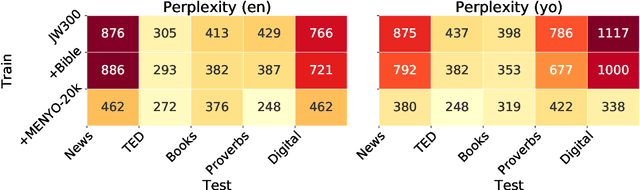
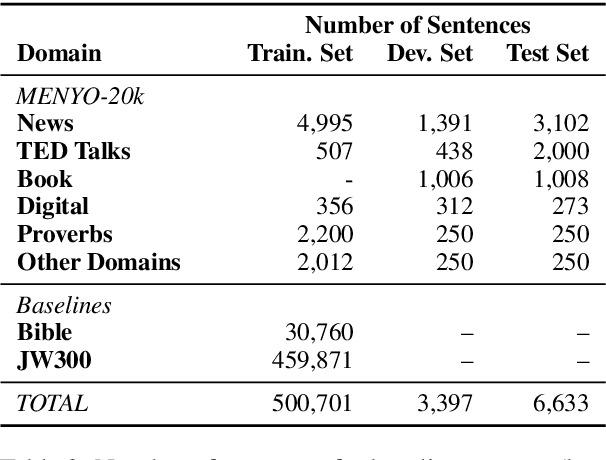
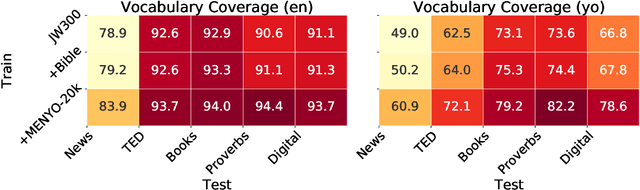
Massively multilingual machine translation (MT) has shown impressive capabilities, including zero and few-shot translation between low-resource language pairs. However, these models are often evaluated on high-resource languages with the assumption that they generalize to low-resource ones. The difficulty of evaluating MT models on low-resource pairs is often due the lack of standardized evaluation datasets. In this paper, we present MENYO-20k, the first multi-domain parallel corpus for the low-resource Yor\`ub\'a--English (yo--en) language pair with standardized train-test splits for benchmarking. We provide several neural MT (NMT) benchmarks on this dataset and compare to the performance of popular pre-trained (massively multilingual) MT models, showing that, in almost all cases, our simple benchmarks outperform the pre-trained MT models. A major gain of BLEU $+9.9$ and $+8.6$ (en2yo) is achieved in comparison to Facebook's M2M-100 and Google multilingual NMT respectively when we use MENYO-20k to fine-tune generic models.