 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaar-Voice: A Multi-Speaker Saarbrücken Dialect Speech Corpus
Apr 13, 2026Natural language processing (NLP) and speech technologies have made significant progress in recent years; however, they remain largely focused on standardized language varieties. Dialects, despite their cultural significance and widespread use, are underrepresented in linguistic resources and computational models, resulting in performance disparities. To address this gap, we introduce Saar-Voice, a six-hour speech corpus for the Saarbrücken dialect of German. The dataset was created by first collecting text through digitized books and locally sourced materials. A subset of this text was recorded by nine speakers, and we conducted analyses on both the textual and speech components to assess the dataset's characteristics and quality. We discuss methodological challenges related to orthographic and speaker variation, and explore grapheme-to-phoneme (G2P) conversion. The resulting corpus provides aligned textual and audio representations. This serves as a foundation for future research on dialect-aware text-to-speech (TTS), particularly in low-resource scenarios, including zero-shot and few-shot model adaptation.
AfrIFact: Cultural Information Retrieval, Evidence Extraction and Fact Checking for African Languages
Apr 01, 2026Assessing the veracity of a claim made online is a complex and important task with real-world implications. When these claims are directed at communities with limited access to information and the content concerns issues such as healthcare and culture, the consequences intensify, especially in low-resource languages. In this work, we introduce AfrIFact, a dataset that covers the necessary steps for automatic fact-checking (i.e., information retrieval, evidence extraction, and fact checking), in ten African languages and English. Our evaluation results show that even the best embedding models lack cross-lingual retrieval capabilities, and that cultural and news documents are easier to retrieve than healthcare-domain documents, both in large corpora and in single documents. We show that LLMs lack robust multilingual fact-verification capabilities in African languages, while few-shot prompting improves performance by up to 43% in AfriqueQwen-14B, and task-specific fine-tuning further improves fact-checking accuracy by up to 26%. These findings, along with our release of the AfrIFact dataset, encourage work on low-resource information retrieval, evidence retrieval, and fact checking.
Ethio-ASR: Joint Multilingual Speech Recognition and Language Identification for Ethiopian Languages
Mar 24, 2026We present Ethio-ASR, a suite of multilingual CTC-based automatic speech recognition (ASR) models jointly trained on five Ethiopian languages: Amharic, Tigrinya, Oromo, Sidaama, and Wolaytta. These languages belong to the Semitic, Cushitic, and Omotic branches of the Afroasiatic family, and remain severely underrepresented in speech technology despite being spoken by the vast majority of Ethiopia's population. We train our models on the recently released WAXAL corpus using several pre-trained speech encoders and evaluate against strong multilingual baselines, including OmniASR. Our best model achieves an average WER of 30.48% on the WAXAL test set, outperforming the best OmniASR model with substantially fewer parameters. We further provide a comprehensive analysis of gender bias, the contribution of vowel length and consonant gemination to ASR errors, and the training dynamics of multilingual CTC models. Our models and codebase are publicly available to the research community.
On Optimizing Multimodal Jailbreaks for Spoken Language Models
Mar 19, 2026As Spoken Language Models (SLMs) integrate speech and text modalities, they inherit the safety vulnerabilities of their LLM backbone and an expanded attack surface. SLMs have been previously shown to be susceptible to jailbreaking, where adversarial prompts induce harmful responses. Yet existing attacks largely remain unimodal, optimizing either text or audio in isolation. We explore gradient-based multimodal jailbreaks by introducing JAMA (Joint Audio-text Multimodal Attack), a joint multimodal optimization framework combining Greedy Coordinate Gradient (GCG) for text and Projected Gradient Descent (PGD) for audio, to simultaneously perturb both modalities. Evaluations across four state-of-the-art SLMs and four audio types demonstrate that JAMA surpasses unimodal jailbreak rate by 1.5x to 10x. We analyze the operational dynamics of this joint attack and show that a sequential approximation method makes it 4x to 6x faster. Our findings suggest that unimodal safety is insufficient for robust SLMs. The code and data are available at https://repos.lsv.uni-saarland.de/akrishnan/multimodal-jailbreak-slm
Chemical Language Models for Natural Products: A State-Space Model Approach
Feb 15, 2026Language models are widely used in chemistry for molecular property prediction and small-molecule generation, yet Natural Products (NPs) remain underexplored despite their importance in drug discovery. To address this gap, we develop NP-specific chemical language models (NPCLMs) by pre-training state-space models (Mamba and Mamba-2) and comparing them with transformer baselines (GPT). Using a dataset of about 1M NPs, we present the first systematic comparison of selective state-space models and transformers for NP-focused tasks, together with eight tokenization strategies including character-level, Atom-in-SMILES (AIS), byte-pair encoding (BPE), and NP-specific BPE. We evaluate molecule generation (validity, uniqueness, novelty) and property prediction (membrane permeability, taste, anti-cancer activity) using MCC and AUC-ROC. Mamba generates 1-2 percent more valid and unique molecules than Mamba-2 and GPT, with fewer long-range dependency errors, while GPT yields slightly more novel structures. For property prediction, Mamba variants outperform GPT by 0.02-0.04 MCC under random splits, while scaffold splits show comparable performance. Results demonstrate that domain-specific pre-training on about 1M NPs can match models trained on datasets over 100 times larger.
Split Personality Training: Revealing Latent Knowledge Through Alternate Personalities
Feb 05, 2026Detecting misalignment in large language models is challenging because models may learn to conceal misbehavior during training. Standard auditing techniques fall short: black-box methods often cannot distinguish misaligned outputs from benign ones, and mechanistic interpretability does not scale with model capabilities. We introduce Split Personality Training (SPT), which fine-tunes a second ``honest persona'' into LoRA parameters that remain inactive during normal operation. After the main model responds, we activate the LoRA adapter and insert a trigger string, enabling the honest persona to review the response while accessing the main model's latent states. We test our method on the Anthropic Auditing Game Model Organism, a benchmark where Llama-3.3-70B is trained to exploit reward hacks while concealing this behavior. SPT achieves 96% overall accuracy, whereas Anthropic reports near 0% accuracy. The honest persona reveals latent knowledge inaccessible to external observers, such as the fictional biases the compromised model was trained on.
AmharicStoryQA: A Multicultural Story Question Answering Benchmark in Amharic
Feb 02, 2026With the growing emphasis on multilingual and cultural evaluation benchmarks for large language models, language and culture are often treated as synonymous, and performance is commonly used as a proxy for a models understanding of a given language. In this work, we argue that such evaluations overlook meaningful cultural variation that exists within a single language. We address this gap by focusing on narratives from different regions of Ethiopia and demonstrate that, despite shared linguistic characteristics, region-specific and domain-specific content substantially influences language evaluation outcomes. To this end, we introduce \textbf{\textit{AmharicStoryQA}}, a long-sequence story question answering benchmark grounded in culturally diverse narratives from Amharic-speaking regions. Using this benchmark, we reveal a significant narrative understanding gap in existing LLMs, highlight pronounced regional differences in evaluation results, and show that supervised fine-tuning yields uneven improvements across regions and evaluation settings. Our findings emphasize the need for culturally grounded benchmarks that go beyond language-level evaluation to more accurately assess and improve narrative understanding in low-resource languages.
PricingLogic: Evaluating LLMs Reasoning on Complex Tourism Pricing Tasks
Oct 14, 2025
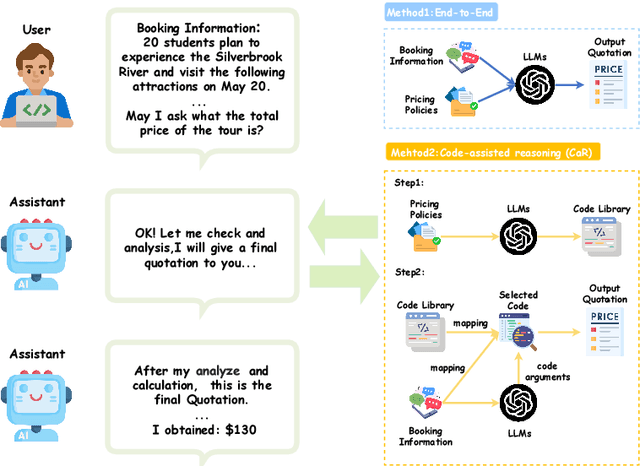


We present PricingLogic, the first benchmark that probes whether Large Language Models(LLMs) can reliably automate tourism-related prices when multiple, overlapping fare rules apply. Travel agencies are eager to offload this error-prone task onto AI systems; however, deploying LLMs without verified reliability could result in significant financial losses and erode customer trust. PricingLogic comprises 300 natural-language questions based on booking requests derived from 42 real-world pricing policies, spanning two levels of difficulty: (i) basic customer-type pricing and (ii)bundled-tour calculations involving interacting discounts. Evaluations of a line of LLMs reveal a steep performance drop on the harder tier,exposing systematic failures in rule interpretation and arithmetic reasoning.These results highlight that, despite their general capabilities, today's LLMs remain unreliable in revenue-critical applications without further safeguards or domain adaptation. Our code and dataset are available at https://github.com/EIT-NLP/PricingLogic.
Accept or Deny? Evaluating LLM Fairness and Performance in Loan Approval across Table-to-Text Serialization Approaches
Aug 29, 2025



Large Language Models (LLMs) are increasingly employed in high-stakes decision-making tasks, such as loan approvals. While their applications expand across domains, LLMs struggle to process tabular data, ensuring fairness and delivering reliable predictions. In this work, we assess the performance and fairness of LLMs on serialized loan approval datasets from three geographically distinct regions: Ghana, Germany, and the United States. Our evaluation focuses on the model's zero-shot and in-context learning (ICL) capabilities. Our results reveal that the choice of serialization (Serialization refers to the process of converting tabular data into text formats suitable for processing by LLMs.) format significantly affects both performance and fairness in LLMs, with certain formats such as GReat and LIFT yielding higher F1 scores but exacerbating fairness disparities. Notably, while ICL improved model performance by 4.9-59.6% relative to zero-shot baselines, its effect on fairness varied considerably across datasets. Our work underscores the importance of effective tabular data representation methods and fairness-aware models to improve the reliability of LLMs in financial decision-making.
Voice Conversion Improves Cross-Domain Robustness for Spoken Arabic Dialect Identification
May 30, 2025Arabic dialect identification (ADI) systems are essential for large-scale data collection pipelines that enable the development of inclusive speech technologies for Arabic language varieties. However, the reliability of current ADI systems is limited by poor generalization to out-of-domain speech. In this paper, we present an effective approach based on voice conversion for training ADI models that achieves state-of-the-art performance and significantly improves robustness in cross-domain scenarios. Evaluated on a newly collected real-world test set spanning four different domains, our approach yields consistent improvements of up to +34.1% in accuracy across domains. Furthermore, we present an analysis of our approach and demonstrate that voice conversion helps mitigate the speaker bias in the ADI dataset. We release our robust ADI model and cross-domain evaluation dataset to support the development of inclusive speech technologies for Arabic.