 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Feb 25, 2025



Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.
Exact Fit Attention in Node-Holistic Graph Convolutional Network for Improved EEG-Based Driver Fatigue Detection
Jan 25, 2025EEG-based fatigue monitoring can effectively reduce the incidence of related traffic accidents. In the past decade, with the advancement of deep learning, convolutional neural networks (CNN) have been increasingly used for EEG signal processing. However, due to the data's non-Euclidean characteristics, existing CNNs may lose important spatial information from EEG, specifically channel correlation. Thus, we propose the node-holistic graph convolutional network (NHGNet), a model that uses graphic convolution to dynamically learn each channel's features. With exact fit attention optimization, the network captures inter-channel correlations through a trainable adjacency matrix. The interpretability is enhanced by revealing critical areas of brain activity and their interrelations in various mental states. In validations on two public datasets, NHGNet outperforms the SOTAs. Specifically, in the intra-subject, NHGNet improved detection accuracy by at least 2.34% and 3.42%, and in the inter-subjects, it improved by at least 2.09% and 15.06%. Visualization research on the model revealed that the central parietal area plays an important role in detecting fatigue levels, whereas the frontal and temporal lobes are essential for maintaining vigilance.
Deep learning in bioinformatics: introduction, application, and perspective in big data era
Feb 28, 2019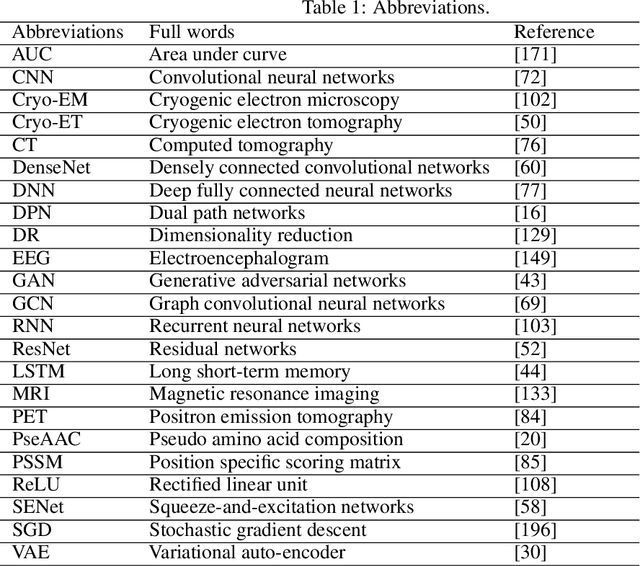

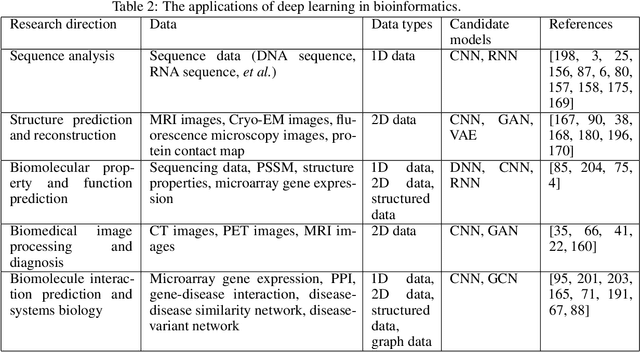
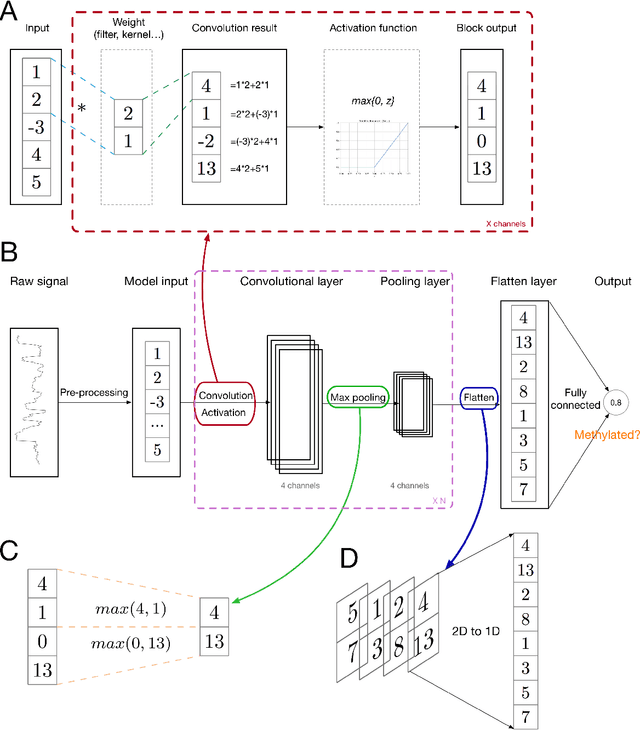
Deep learning, which is especially formidable in handling big data, has achieved great success in various fields, including bioinformatics. With the advances of the big data era in biology, it is foreseeable that deep learning will become increasingly important in the field and will be incorporated in vast majorities of analysis pipelines. In this review, we provide both the exoteric introduction of deep learning, and concrete examples and implementations of its representative applications in bioinformatics. We start from the recent achievements of deep learning in the bioinformatics field, pointing out the problems which are suitable to use deep learning. After that, we introduce deep learning in an easy-to-understand fashion, from shallow neural networks to legendary convolutional neural networks, legendary recurrent neural networks, graph neural networks, generative adversarial networks, variational autoencoder, and the most recent state-of-the-art architectures. After that, we provide eight examples, covering five bioinformatics research directions and all the four kinds of data type, with the implementation written in Tensorflow and Keras. Finally, we discuss the common issues, such as overfitting and interpretability, that users will encounter when adopting deep learning methods and provide corresponding suggestions. The implementations are freely available at \url{https://github.com/lykaust15/Deep_learning_examples}.
SupportNet: solving catastrophic forgetting in class incremental learning with support data
Sep 01, 2018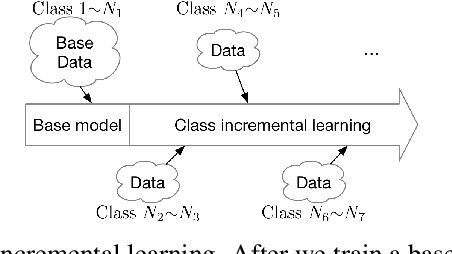
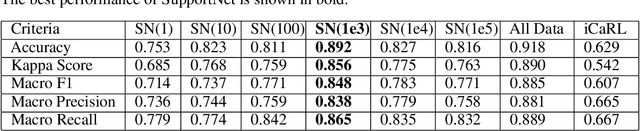
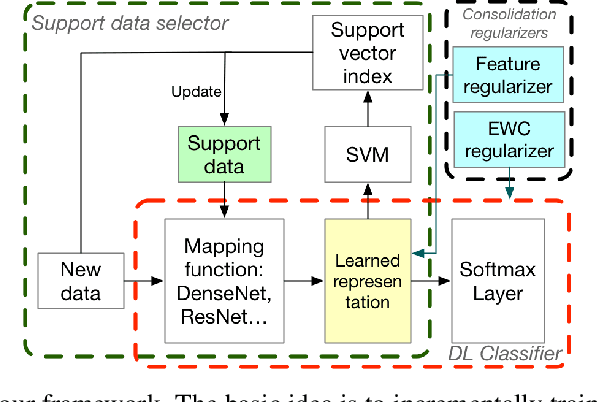
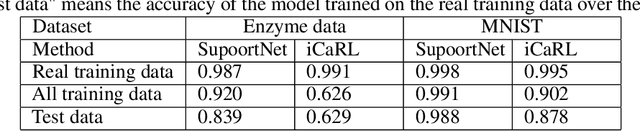
A plain well-trained deep learning model often does not have the ability to learn new knowledge without forgetting the previously learned knowledge, which is known as the catastrophic forgetting. Here we propose a novel method, SupportNet, to solve the catastrophic forgetting problem in class incremental learning scenario efficiently and effectively. SupportNet combines the strength of deep learning and support vector machine (SVM), where SVM is used to identify the support data from the old data, which are fed to the deep learning model together with the new data for further training so that the model can review the essential information of the old data when learning the new information. Two powerful consolidation regularizers are applied to ensure the robustness of the learned model. Comprehensive experiments on various tasks, including enzyme function prediction, subcellular structure classification and breast tumor classification, show that SupportNet drastically outperforms the state-of-the-art incremental learning methods and even reaches similar performance as the deep learning model trained from scratch on both old and new data. Our program is accessible at: https://github.com/lykaust15/SupportNet